1,Node.js REPL交互式解释器:nodejs安装完毕后,打开终端,进入到nodejs的安装目录下,输入node,进入到新的页面,该页面称为Node.js REPL (交互式解释器);可以简单的输入表达式然后回车,会得到计算结果;如输入1+4,回车,会显示5;
2,使用变量,可以使用 var 将数据存储到变量中;不是在语句体内时单独声明变量,可以不加分号;
3,Node.js REPL交互式解释器支持使用多行表达式,如循环体,类似javascript,系统会自动检查是否为连续循环体,会自动生成三个点的符号;
4,想得到两个变量的计算结果时,直接输入如 x+y 无需带等号,分号之类的,否则会报错;
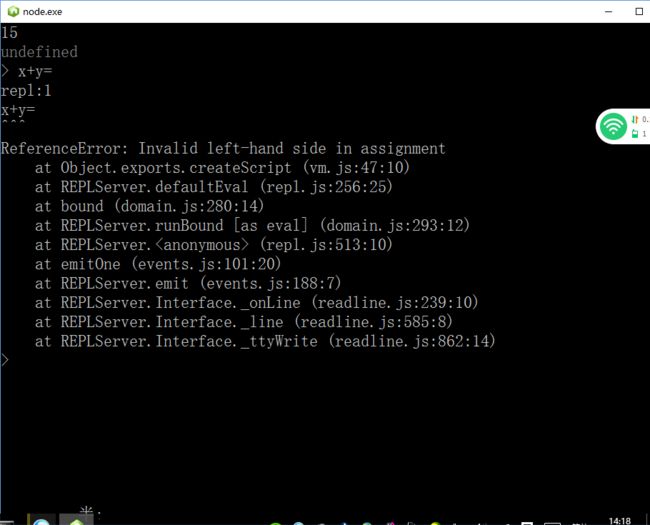
5,可以使用下划线获得表达式的结果,如分别声明了var x=5 var y=4 输入x+y 回车后显示 9 再输入 var sum=_ 回车,再输入console.log(sum); 回车后得到15 ; 此时15已经存到了sum里面,直接输入sum,回车会显示15;
6,REPL的命令:
ctrl+c : 退出当前终端;
ctrl+c: 连续按两次,退出REPL
ctrl+d :退出REPL
tab键:列出当前命令;
.help :列出使用命令;
.break : 退出多行表达式;
.clear : 退出多行表达式;
.save filename : 保存当前REPL会话内容到文件filename;
.load filename : 载入当前REPL会话文件内容;
7,Nodejs的异步编程就体现在回掉函数上;从而提高了执行效率;执行异步逻辑的时候,采用后续传递的方式,将后续逻辑封装到回调函数中,作为起始函数的参数,逐层嵌套,逐层执行;
如,读文件的内容,可以边读取文件,边执行其他命令;
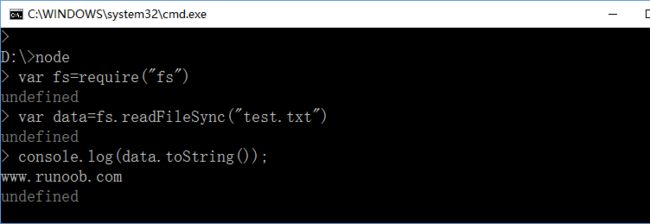
阻塞式的方法读取文件内容:
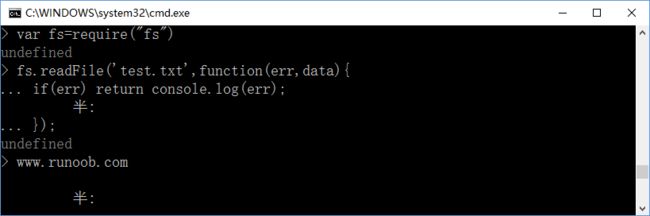
非阻塞式的方法读取文件内容:
将上述执行代码存到main.js文件中;.save main.js
ctrl+c退出到终端后执行:node main.js
5,访问(载入)模块通过require指令:假如访问event模块:require("event");
6,创建服务器并监听端口:createServer().listen(端口号);;
7,EventEmitter 提供了多个属性,on和emit,on用来绑定事件函数,emit用来触发事件;
8,nodejs自带了一个http的模块,我们在代码中使用require请求它,并将其赋给一个本地变量,这个本地变量就变成带有这个模块的所有方法的对象;
一般给这个本地变量起一个和模块相同的名字是惯例,如:var http=require('http');但也可以起不同的名字;
9,处理不同的HTTP请求在代码是一个不同的部分,叫做“路由选择”;
路由:指针对不同的url请求,有不同的处理方式;
10,回掉函数onRequest()被触发的时候,有两个参数被传入,request和response;
11,采用异步回调来实现非阻塞的处理post请求的数据;为了是整个过程非阻塞,会将post数据(因为post数据较厚重)分成小的数据块,然后通过触发特定事件,将小数据块传递个回调函数;特定的事件如data(表示小数据块到达),end事件(表示所有数据都已接收完毕);
我们需要告诉nodejs当这些特定时间发生时,回调哪些函数,通过什么方法告诉呢,通过在request对象上注册监听器(listener)实现,request对象就是每次接收到http请求时,回调函数onrequest()的第一个参数;
12,formidable 模块就是将http post请求的表单可以在nodejs中被解析;
13,javascript中只有字符串类型,没有二进制类型,而处理TCP或文件流时,必须使用二进制数据,所以nodejs中就有了buffer缓冲区,专门用来存放二进制数据;
14,当在node.js中需要处理文件流时,就要用到buffer,原始数据存储在buffer类的实例中,一个buffer类类似于一个整数数组;
15,nodejs中的拷贝缓冲区语法:buf.copy(targetbuf); //targebuf 是作为被拷贝的对象;
16,Stream是一个抽象接口,nodejs中很多实例都实现了这个接口;例如对http服务器发起请求的request对象,还有stdout标准输出;
17,Stream有四种流类型:
Readable:可读操作;
Writable:可写操作;
Duplex:可读可写操作;
Transform:被写入数据,然后读出结果;
所有Stream的对象都是EventEmitter的实例;
常用的事件有:data:当有数据可读时触发;end:没有更多的数据可读时触发;
error:在接收和写入过程中发生错误时触发;
finish:所有数据已被写入到底层系统时触发;
10,管道流提供了输出流到输入流的机制;通常用于从一个流中获取数据,并传到另一个流中;
例:
var fs=require("fs");
var readerStream=fs.createReadStream("input.txt");
var writerStream=fs.createWriteStream("output.txt");
readerStream.pipe(writerStream);
console("程序执行完毕");
查看文件内容:cat output.txt
10,模块的流程:创建模块,导出模块,加载模块,执行模块,
11,创建模块:
创建main.js文件;
var hello=require('./hello'); //引入当前目录下的hello.js文件,Node.js默认的文件后缀名是.js;
hello.world();
Node.js提供了两个对象exports和require,exports 是模块公开的接口,require是用于从外部获取模块的接口,即所获取模块的exports对象;
创建hello.js文件:
exports.world=function(){
console.log('hello world');
}
在以上hello.js文件中:hello.js 通过exports对象 把world作为模块的接口;在main.js中通过require('./hello')加载这个模块;然后就可以直接引用hello.js中exports的的这个成员函数了;
有时,我们只是想把一个模块封装到对象中,格式:module.exports=function(){ // .....}
例:hello.js:
function Hello(){
var name;
this.setName=function(tName){
name=tName;
};
this.sayHello=function(){
console.log('Hello '+name);
};
}
main.js:
var Hello=require('./hello');使用require引入hello模块,并赋值给Hello局部变量;
var hello=new Hello();
hello.setName('Tom');
hello.sayHello(); //会输出 Hello Tom
12,Node.js中 class是关键字,一般声明时尽量避免使用class,可以使用klass;
13,总结:当我们想让模块导出的是一个对象时, exports 和 module.exports 均可使用(但 exports 也不能重新覆盖为一个新的对象),而当我们想导出非对象接口时,就必须也只能覆盖 module.exports 。
14,URL:统一资源定位符;URL肯定是URI,但URI不一定是URL;
URI:统一资源标识符;偏重标识,抽象的定义
15,URL模块:
有三个常用方法:
url.parse():将url地址解析成对象;
例:
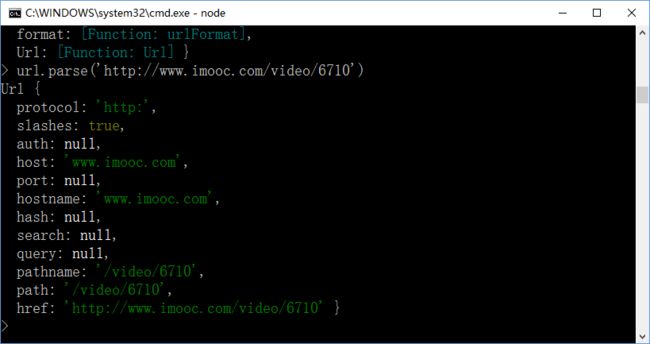
protocol:协议名;
slashes:是否有协议的双斜线;
host:http服务器的IP地址或域名;
port:端口号;
hostname:主机名;
hash:哈希值,锚点,加#将页面滚动到当前位置;
search:查询字符串参数;
query:发送给http服务器的数据;用等号分隔的键值对;
pathname:访问资源的路径名;
path:访问资源的路径;
href:没被解析的完整的超链接;
以上这些参数所代表的含义应该记住及对应哪部分!!!
将url地址修改添加相关参数后再次解析得到:
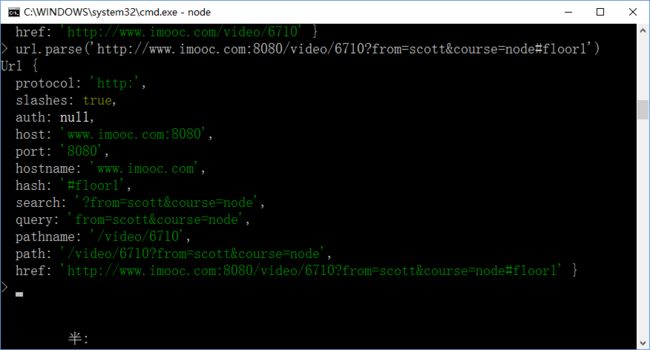
2),url.parse(urlStr, [parseQueryString]):这里第二个参数就是将query解析成对象,默认是false(可以不写)效果和上面一样,如果设置为true,则显示如下:query后面的内容变成了from:'scott', course:'node'
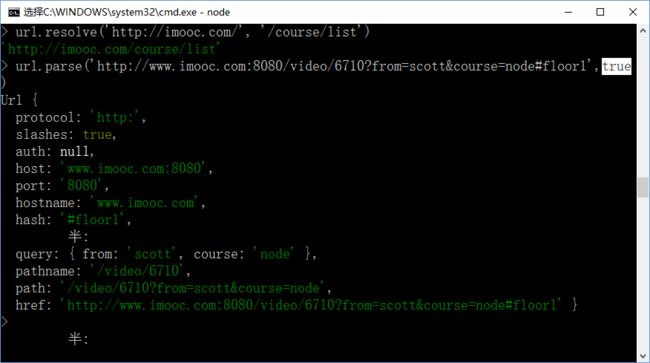
3)url.parse(urlString , [parseQueryString],[slashesDenoteHost]) :第三个参数就是当没有标明协议类型是否是http或是别的,及不写路径等参数时仍要解析出原来的地址;默认是false,不写的时候,host会显示为null及path不会显示出完整的带有http的url,如下:
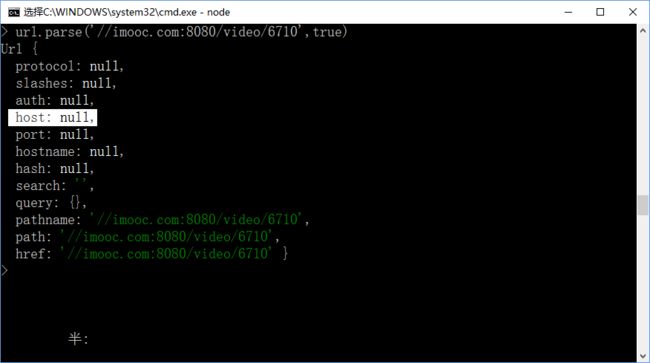
当将第三个参数设置为true时,host(服务器的IP地址或域名)就会显示出来,并且path的内容也会完整地将协议名如http显示出来:
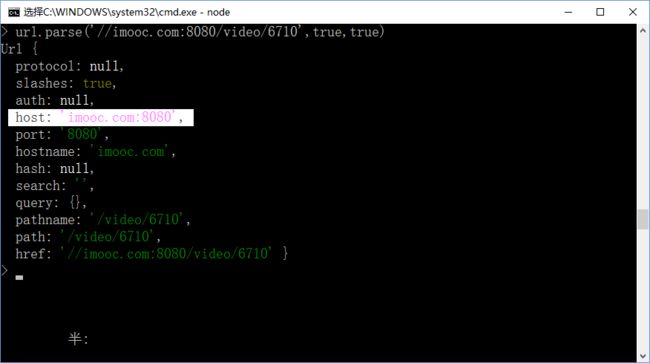
15,使用url.format()方法将上例中已经被解析的地址再还原回去;
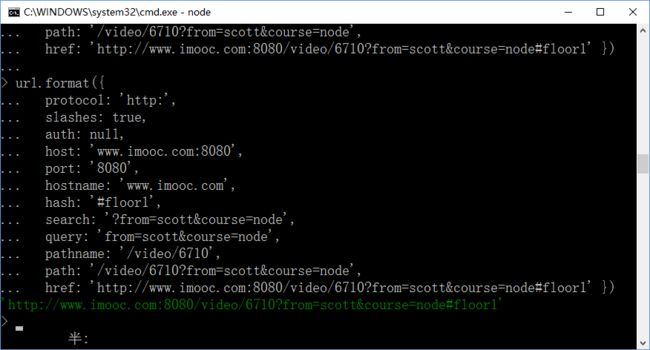
注意先输入:url(,然后将上例的已经解析的一堆字符串右键->标记,ctrl+c复制,然后粘贴到url(的后面,再输入 小括号 ) 然后回车;即可得到原来的url地址;
16,url.resolve(from ,to) 方法:第一个参数from:首页地址(结尾可以加斜线也可不加),第二个参数:路径path;
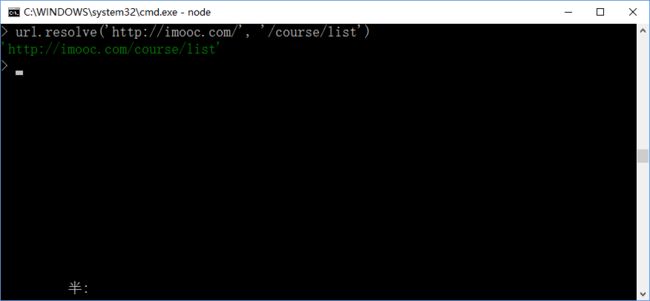
语法例子:
url.resolve('/one/two/three', 'four') // '/one/two/four' url.resolve('http://example.com/', '/one') // 'http://example.com/one' url.resolve('http://example.com/one', '/two') //'http://example.com/two'
16,QueryString:常常将不同的参数追加到url的末尾发送给服务器,服务器拿到的是字符串的参数串,服务器不知道参数个数及参数名,参数值;
就需要将这些参数拎出来;我们可以遍历对象,也可以获取这个值;
querystring.strinify({}):该方法可以将多个字符串对象序列化成字符串;注意方法里的大括号;
该方法的第二个参数就是连接符,默认是与 ’& ‘;也可以改成别的,如逗号 ’,‘;
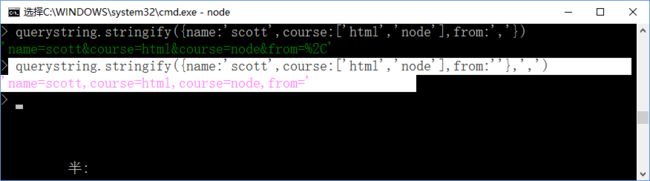
第三个参数就是key和value中间的等号,此处如name和值之间的等号,可以用别的符号来替换,如冒号 ’:‘
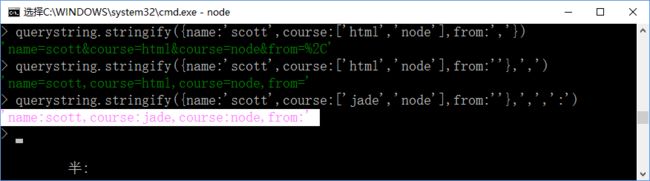
反序列化方法:querystring.parse('反序列化的字符串'):第一个参数就是用于反序列化的字符串;如下:
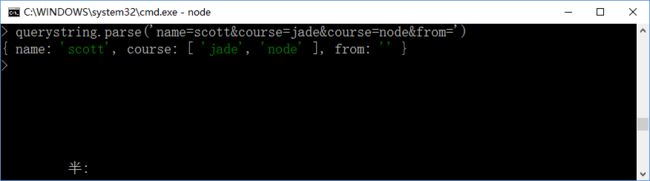
若连接符不是默认的 等号 = 和与 &,则需要传递一个参数,假如是逗号连接的,就要传回逗号,如下:
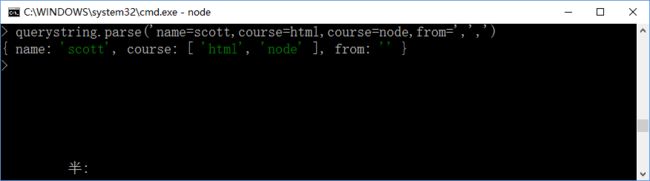
否则若是不传递回连接符的参数,则会将其当成完整的字符串;如下:这是错误的!!!
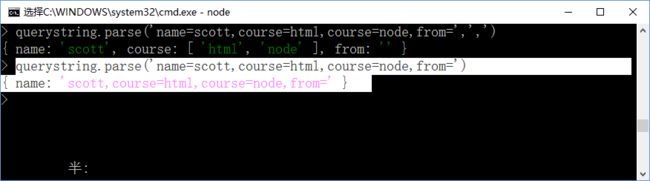
第三个参数就是key和value之间的连接符如果不是默认 的 &,也要传递参数,如冒号’:‘,如下:
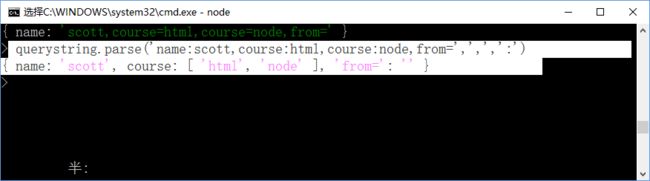
还有第四个参数,就是options,代表参数的个数,默认是1000个,超过限制则不行了,可以通过maxKeys=0,将其设为0,这样就没有限制了,;
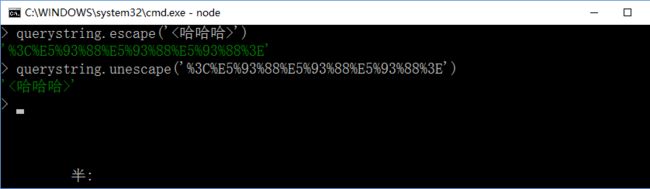
转译和反转译,querystring.escape()和querystring.unescape();如下:
16,HTTP:
就是一个协议;
http客户端发起请求,创建端口;http服务器端再到端口监听客户端请求,一旦接收到请求,http服务器端向客户端返回状态(如200:成功,404:未找到)和内容(如文件等);
在这个请求和应答的过程中,计算机和浏览器做很多事情:
首先是域名解析:
第一步:浏览器要检查自身DNS缓存;查找缓存的方法:如在浏览器下,输入chrome://net-internals/#dns (不是谷歌浏览器也可以,会自动更改浏览器名称的)然后回车,便会查看到dns缓存记录,
第二步:浏览器会搜索操作系统自身的DNS缓存,进行解析(前提是当浏览器没有找到缓存或缓存已失效)
第三步:读取本地的host文件(前提是如果操作系统的缓存也没有找到),在window的系统文件system32下的drivers里面的etc,里面的host文件;
第四步:浏览器会发起一个dns的系统调用(前提是如果在host里面也没找到对应的配置项),就会向本地主库的一个dns服务器(一般是宽带运营商提供的)发起域名解析请求;
第五步:浏览器获得域名对应的IP地址后,发起HTTP三次握手;
第六步:TCP/IP简历连接后,浏览器就可以向服务器发送http请求了,
第七部:服务器端接收到请求,根据路径参数,经过后端的一些处理后,将结果返回给浏览器,如果是页面,就会将完整的页面代码返回给浏览器;
第八步,浏览器得到了服务器的返回结果---页面代码,在解析和渲染页面时,里面的css, js,图片等资源时,也是http请求,也是按照以上7个步骤进行的;
第九步:浏览器解析完后,就把完整的页面呈现给了用户;
HTTP中常见状态码:
1xx :表示的是指示信息,请求已经接收,继续进行;
2xx:表示成功,请求已经chulil;
3xx:表示重定向,请求需要更进一步处理;
4xx:表示客户端错误,语法错误,或是无法实现;
5xx:服务器端的错误,可能不能实现;
200:成功;
400:客户端可能语法错误,服务器端不能理解;
401:请求没有经过授权;
403:服务器端收到请求但是拒绝服务;
404:文件找不到;
500:服务器端发生了不可预期的错误;
503:服务器当前还不能处理客户端的请求,可能过段时间才能恢复正常;
17,javascript中的异步函数:settimeout和setInerval;
18,单线程:一次只能执行一个程序, 只有当这个程序执行完了,才能执行下一个程序;
多线程:同时执行多个程序;
19,IO:磁盘的写入和读出;
20,阻塞:事件挂起,停止了
非阻塞:
21,所有能够触发事件的对象都是EventEmitter的实例;
22,事件驱动:为某个事件注册了回调函数,但这个回调函数不是马上执行,只有当事件发生的时候才调用回调函数,这种方式就叫事件驱动;这种回调就是基于事件驱动的回调;如果回调是和IO有关,就叫基于回调的异步IO;
事件循环:eventloop是个队列,用于处理大量异步操作,IO密集操作,完成的时候需要调用回调,而不发省阻塞;
23,http源码解读:
作用域:全局作用域和局部作用域(某个函数内部),在局部作用域里可以访问其外部全局作用域变量或函数,而在局部作用域挖边不可以访问局部作用域里的变量;
上下文:代表this变量的值及this的指向;分为定义时的上下文和运行时的上下文;上下文时可以改变的;
24,this:用于指向调用当前方法的对象;
1)例:var pet={
words: '....';
speak:function(){
console.log(this.words);
console.log(this === pet); //判断this 是否是执行pet
}
}
pet.speak();
//执行结果是 .... 和 true,说明this指向的就是pet,此处声明pet为一个对象,pet.speak(),pet对象调用了speak方法,所以此处this指向的就是pet;
2)例:
function pet(words){
this.words=words;
console.log(this.words);
console.log(this);
}
pet('....'); //执行结果就是一大堆的东西,如下图,原因是this此处指向的是global全局对象;所以console.log(this);打印的是一大堆
可以通过修改console.log(this)变成console.log(this === global)验证一下,得到true,说明this指向的就是true;
3)例:function Pet(words){ //注意Pet是大写的,因为后面要利用它构造实例
this.words=words;
this.speak=function(){
console.log(this.words);
console.log(this);
}
}var cat = new Pet('miao');
cat.speak(); //执行结果为 如下图:
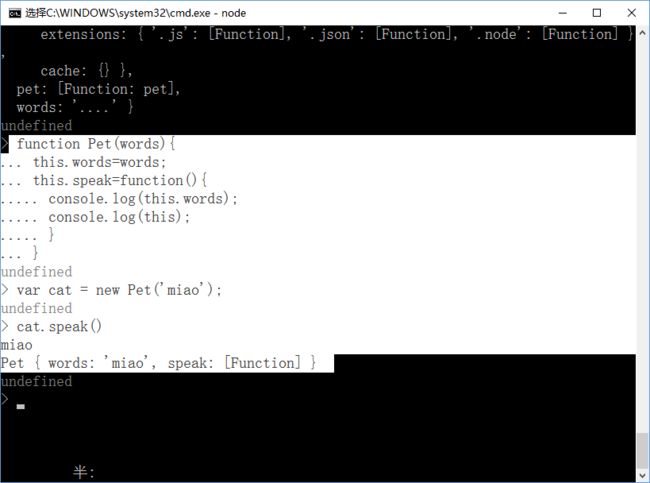
此处的cat是Pet的实例对象,所以cat调用speak方法后,this指向的就是cat对象;有words属性,有speak方法;
20,在javascript里面,this关键字通常指向当前函数的拥有者;这个拥有者就叫做执行上下文;this通常只能在函数内部使用;
21,函数的上下文执行对象需要依据情况而定,会动态的改变,在全局运行的上下文中,this指的是全局对象global;在函数内部时取决于函数的调用方式,有以上3种方式;
22,call()和apply():使用call和apply可以改变上下文对象;call和apply作用的是相同的,只是call需要参数列表,但是apply是需要传递参数作为数组;就是更改this执行的对象,了、例下图:
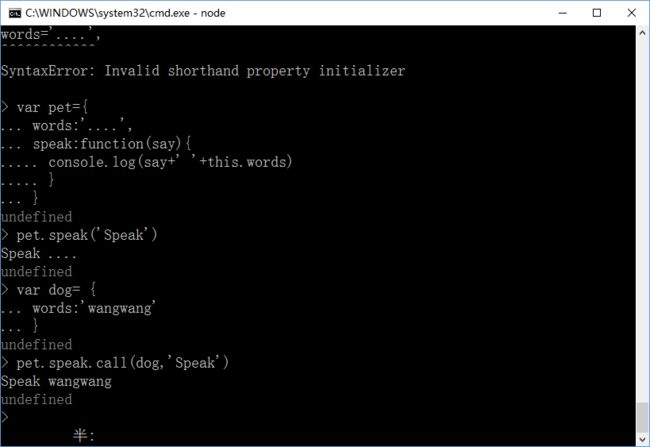
声明了dog对象,当dog也想拥有pet的技能speak时,通过call方法,将原本由于pet.speak而指向pet对象的this,通过call转变成dog,改变了执行上下文;得到Speak wangwang;
2)通过call和apply改变上下文的方法也可以实现继承:
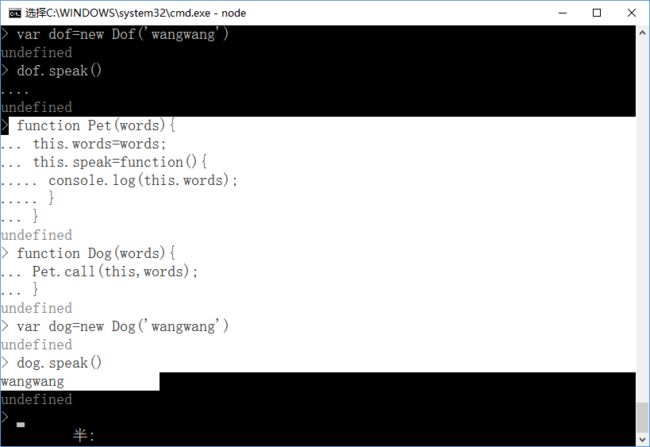
通过使用call方法,将Pet构造函数里面的this替换成Dog的,从而Dog也拥有了speak方法;相当于将Pet中的this.words=words;代码移植到Dog构造函数内部。所以通过Dog可以访问speak方法;
或者是使用Pet.apply(this,argument); //argument是一个数组
共同点:都是将参数依次排在”要替换的执行环境“后面,
区别:指定调用对象时传递构造参数的方式,,call是使用类似java中断可变参数,apply则是使用数组;
使用场合:
Person是父类,student是子类,如果父类和子类的构造参数完全一样,此处即Person对象的构造参数和Student对象的构造参数完全一样(包括顺序)。此时,我们应该选择call还是apply呢?由于apply接收一个数组、Person和Student的构造参数一样且arguments也是一个数组。则,我们可以直接用:object.apply(this, arguments);就可进行继承。但是有人说,call也可以啊。我直接将参数依次写在object.call(this, arg1, arg2,...,argn)。如果Person和Student的参数有n个,则你需要写多少呢,你能保证你不会把顺序写错,你觉得代码可读性好吗?因此,如果被继承和继承的构造函数一样(包括参数顺序),则推荐使用apply方式。
3)注意:call和apply不能直接继承原型的属性和方法;
例如:
Person.prototype.getName = function(){
return this.name;
};
var stu=new Student('Bob' ,);
alert(stu.getName); //这种是不对的;
call和apply只能通过原型链的方式进行继承;
Student.prototype=new Person('Bob');
这样就可以让student实例调用Person的原型方法getName()了;
HTTP源码解读:
16,在github里面搜索的快捷键是 t,能突出搜索的面板,方便检索;
假设,如何找到何处使用到了request?,
1)可以先输入request,但是会有很多的,不方便查看;
2)直接输入emit,会直接看到哪里触发了request;
3)前边带下划线的是http的私有模块;
4)_http_incoming和_http_outgoing是提供输入输出流的对象;
response是outgoingMessage的实例,,也是serverresponse的实例;request是incomingMessage的实例;
5)createServer的作用就是返回server的一个实例,再将回掉函数继续作为参数,给server的实例:
| exports.createServer = function(requestListener) { | |
| return new Server(requestListener); | |
| }; |
在githtb里面的某个代码文件中想要搜索某个固定的单词,ctrl+f,就会在顶部突出搜索框,然后输入要查找的单词即可;
16,Nodejs的性能测试:
测试工具:Apache ab
例:ab -n1000 -c10 http://localhost:2015/
-n 代表:网络请求数是1000;-c代表:并发数是10;注意地址后边要加斜线;-t: 总时间,-p:post 的数组文件,-w:以html表格的形式输出结果;
远程对web服务器压力测试时,效果往往不理想;因为有网络延时,建议用内网的另一台,或多台测试;
17,http小爬虫,借助http API ;
18,package.json for NPM 详解:
http://ju.outofmemory.cn/entry/130809