基于三元组知识图谱的简易问答系统
基于三元组知识图谱的简易问答系统
最近实现了一个基于三元组知识图谱的简易问答系统。关于这个,我还写了一篇有趣的博文 准备考试?python也能帮你划重点,上考场(误)
效果示例:
问:谁复辟了帝制?
答:袁世凯
问:清政府签订了哪些条约?
答:清政府签订了北京条约、天津条约。
问:孙中山干了哪些事?
答:他就任临时大总统、发动护法运动、让位于袁世凯。
问:孙中山做出了哪些贡献?
答:他的贡献包括:就任临时大总统、发动护法运动。
下面整理一下我的搭建思路:
为了设计问答系统,我逐步解决了三个问题:问了什么?答案是什么?怎么回答?
问了什么?【问句解析】
基于知识图谱的问答系统很难直接回答自然文本状态的问题,所以我们要把问题转化为一定的结构。一个很好的选择就是三元组:
RDF是知识图谱的一种常见表示形式,以(subject, predicate, object)的三元组形式就足以表示实体之间的许多复杂联系。如:
- [‘清政府’, ‘签订’, ‘天津条约’]
- [‘袁世凯’, ‘复辟’, ‘帝制’]
- [‘孙中山’, ‘就任’, ‘临时大总统’]
下图是从《中国近现代史纲要》的部分文本中提取的知识图谱的示意图。
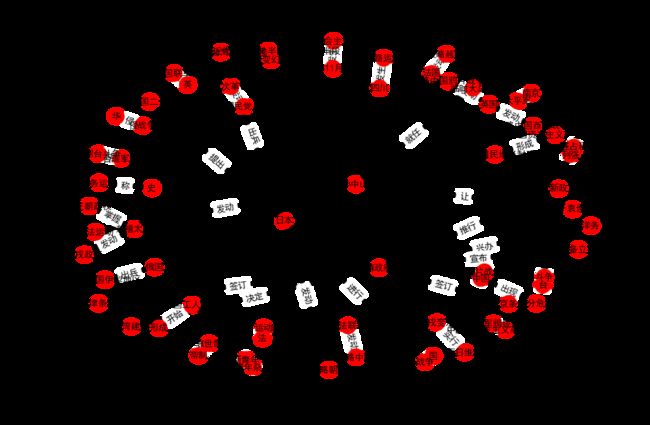
问句可以看做残缺的三元组,提问的部分就是三元组中缺失的部分。问句中有些部分的具体内容在已经包含,可以作为已知条件。而有些部分未知,是作为“谁”,“什么”这样的问词形式存在的,这些部分就替换为查询变量。
例如:"清政府干了些什么?"可以看成(清政府,?x,?y)的三元组。
答案是什么?【查询模板】
要从知识图谱中提取答案,需要有对应的查询语句——SPARQL,它的形式接近SQL。例如"清政府干了些什么?",即(清政府,?x,?y),就可以翻译成下面的SPARQL。:
SELECT ?x ?y
WHERE {
清政府 ?x ?y
}
这句话能够查找所有首元素为“清政府”的三元组,并提取出其中的后两个元素。结果大致是[("签订","天津条约"), ("兴办","洋务"),...]
上一个问句主语已知,需要查询谓词和宾语。根据主谓宾不同的已知情况,我们需要分别处理,替换三元组的对应部分为已知或查询变量。开头的示例就包括了(清政府,签订,?x), (?x,复辟,帝制)等。
(简化起见,上例省略了命名空间)有关RDF、SPARQL等概念的教程,这个网站上有不错的资料:https://www.cambridgesemantics.com/blog/semantic-university/
怎么回答?【回答句式】
虽然上面都使用了三元组结构,但是为了用户体验,回答问题依然希望能够使用自然语言。这就需要指定答案以及可以利用的原问句已知条件,套用一定的句式翻译成自然语言。
上例中:问句中的已知条件为"清政府",答案比如有(“签订”,“天津条约”),那回答就可以是“清政府签订天津条约。”
首先由问句的主谓宾解析结果得到候选的问题模板集,它们会限制回答句式。比如仅仅解析结果(清政府,?x,?y),一般不会对应"清政府签订了xxx?"这个同时知道了主语和谓词签订的问题,在回答模板中也就不应该预先出现签订这个词。
确定了候选的问题模板集,然后就可以利用原始问句,从中找到语义最接近的具体模板(通过最小编辑距离)。再对于具体的问题模板,人工设定对应的具体回答方式,就能够保证回答与问题在语义上的协调性。
-
首先,从问题中涉及到的具体实体类型,我们就能够极大地确定问题的语义范围。比如模板
#机构名#签订了哪些条约?(#机构名#,签订,?x),就能够匹配到包括清政府在内的各种机构的签约情况,而个人则会被排除在外。harvesttext里有很方便的工具能够指定和链接实体类型。实体类型也应当限制回答的方式,比如对于#人名#,在回答中用"他/她"干了什么来开头更加自然,而对于#机构名#,我们则可以在回答中重复机构名。 -
另外,问题中的一些措辞也会体现一定的倾向性或者意图,可以通过模板针对性地进行调整。比如模板
#人名#作出了哪些贡献?(#人名#,?x,?y),中包含的贡献一词,尽管不在解析结果中,但它指示我们寻找正面的结果。比如我们询问(孙中山,?x,?y),对于模板#人名#作了哪些事情?,我们能够匹配到[(发动,护国运动),(让,位于袁世凯)],前者为积极而后者为消极,而对于#人名#作出了哪些贡献?我们就应当只返回前者。
流程图
综合以上三个步骤,梳理流程图如下:
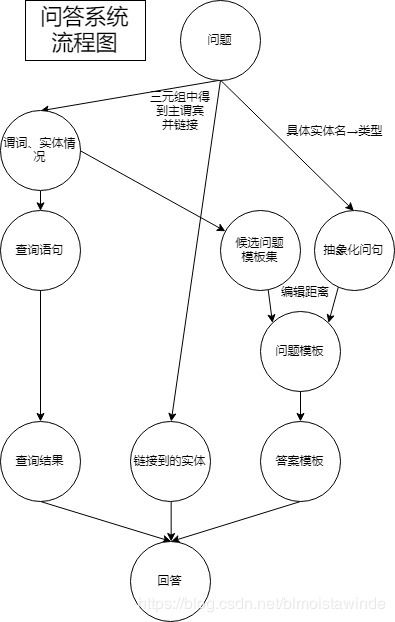
python实现的具体源码可以见:https://github.com/blmoistawinde/hello_world/blob/master/python近代史纲要/naiveKGQA.py
其中主函数QA的代码实现与这一流程图基本一致。