【文献解读 情感合成】Expressive Speech Driven Talking Avatar Synthesis with DBLSTM using 有限的情感双峰数据

论文题目:Expressive Speech Driven Talking Avatar Synthesis with DBLSTM using Limited Amount of Emotional Bimodal Data
论文来源:INTERSPEECH 2016 清华大学, 香港中文大学
论文链接:https://isca-speech.org/archive/Interspeech_2016/pdfs/0364.PDF
关键词:合成会讲话的虚拟人,情感,嘴唇动作,面部表情,DBLSTM
这学期一门课期末要汇报文献,需要讲解和情感计算相关的文献,于是看了这篇,整理一下。
文章目录
- 1 摘要
- 2 引言
- 3 数据描述
- 3.1 情感和中性的双峰语料
- 3.2 语音和视觉特征
- 4 方法
- 4.1 Method(a): 情感数据训练的网络
- 4.2 Method(b): 混合数据训练的网络
- 4.3 Method( c ): 重训练的网络
- 4.4 Method(d): 双监督网络
- 4.5 Method(e): 级联的网络
- 5 实验和结果
- 5.1 实验设置
- 5.2 对不同情绪的客观评价
- 5.3 帧级别的客观评价
- 5.4 主观评价
- 6 总结和展望
- 参考文献
1 摘要
本文解决的问题是合成有表现力的语音头像替身,这一任务的关键在于建模面部情绪和嘴唇动作的交互。
传统的方法要不就是对嘴唇的动作和面部表情分别建模,要不就是需要大量高质量的有情感信息的音视频双峰训练数据,但是这种数据通常很难获取到。
本文提出了几种方法,探索使用大量的中立语料和数据有限的小型情感语料捕获面部表情和嘴唇动作互动的不同可能性。
为了整合语境的影响,我们采用深层双向长短时记忆(DNLSTM)循环神经网络作为回归模型,从声音特征、情感状态和语境三个方面对人脸特征进行预测。
实验结果显示,通过拼接中性的人脸特征和情感声音特征作为DBLSTM模型的输入,在客观和主观评价两方面都取得了最好的结果。
2 引言
会讲话的虚拟人已经广泛应用于虚拟主机/导师、语音代理、远程通信等人机交互领域。一个生动的人脸模型需要语音、唇动和面部的情感表情来增强互动。
一些研究表明说话人在不同情绪影响下的行为是截然不同的。这种影响因语音语境的不同而不同。例如,讲“what?”时由于面部表情的不同(happy or sad),唇部的形状和动作也是不同的。因此,在合成会讲话的虚拟人(expressive talking avatar)时,面部的情感表情和唇动应该被纳入考虑。
已有一些研究,通过对现有的中性虚拟人合成系统进行扩展,以得到有表现力的合成的会讲话的虚拟人。表现为,从情感音视频语料中学习不同表情的情感面部帧或参数,然后简单地应用到情感中立的头像面部上。
但是,这样的方法是对唇动和面部表情分别建模的,忽视了两者之间的交互关联。为了解决这一问题,有一些使用回归模型的统计的方法被提出,例如支持向量回归(SVR)、神经网络(NNs)、隐式马尔科夫模型(HMMs)。训练这样的回归模型需要包含不同情感的大型的语音数据集。但是,收集在不同情感下的大量的语音数据是非常低效并且耗时的。我们已有的大型数据集是包含了中立信息的音视频语料。如何充分利用这些中立的语料,作为对规模相对较小的情感语料的补充,以提高虚拟说话人的表达能力,需要进一步的研究。
针对上述问题,本文提出了几种语音驱动的生成虚拟说话人的回归模型,并对其进行了测试。受DBLSTM的影响,我们将它应用到了回归模型中以合并有语音特征和情感状态的语境信息。基于DBLSTM,我们提出了5种方法,在使用大型的中立语料和一小部分的情感语料的前提下,得到捕获交互信息的不同概率。
这5种方法的不同在于利用中立信息的方式不同。具体来说,在方法(a)中,只使用情感语料训练DBLSTM网络;方法(b)和©通过训练一个DBLSTM网络,同时捕获中立的和情感的信息;方法(d)和(e)使用一个DBLSTM网络捕获中立信息,然后还使用了捕获情感信息的DBLSTM。
3 数据描述
3.1 情感和中性的双峰语料
本工作应用到的中性语料包含由一个母语是英文的女性录制的321个中性的话语,每个话语持续3~4秒。
对于情感语料,我们使用了eNTERFACE’05情感数据集。44名试验人员以6种基本情绪阅读句子,包括愤怒、厌恶、恐惧、快乐、悲伤和惊讶。每种情感类别包括5个句子,录制每个句子大概持续4秒。这些试验人员都不是演员,他们的面部表情都是不专业的,而且每个人都不一样。
3.2 语音和视觉特征
对于语音特征,我们从INTERSPEECH 2009 Emotion Challenge中选取了384维的特征,包括16个低水平表示符(LLDs)和他们一阶的delta系数以及12 functionals。LLD特征是使用openSMILE抽取出来的,帧长为40ms,帧位移为10ms。
对于视觉特征,我们使用了由MPEG-4规范定义的面部动画参数,用于虚拟说话人的动画,其中包括68个FAPs和66 low-levels ones和2 high-level ones。low-level的FAPs代表了基础面部行动的完全集;2 high-level FAPs分别代表了发音嘴型和表情。
4 方法
在语音驱动的说话虚拟人中,发音参数主要由声音输入决定。应在建模协同发音现象时考虑语境信息。发音参数也受和不同的情感状态有关的面部表情影响。情感状态、面部表情和唇动间的交互会随着时间的变化而变化,这取决于声音和语境信息。回归模型应该能从训练语料中挖掘出这样关系。本文采用了DBLSTM回归模型来预测面部参数。
设计了5个方法来挖掘使用中立语料信息来提升情感说话虚拟人表现的可能性。5种方法的结构如图 1所示。

4.1 Method(a): 情感数据训练的网络
为了从声音数据中预测出情绪人脸参数。最直接的方法和SOTA方法都是使用含有不同情感状态的情感语料训练出一个回归模型或者映射模型。
如图1 a所示,回归模型学习到了面部特征和情感状态间的交互是随时间变化的,并且考虑到了语音特征和语境信息。令 X E X_E XE表示输入的情感语音特征(E-LLD), Y E Y_E YE表示目标的面部特征(E-FAPs),要处理的问题是找到一个优化的情感回归模型 F E F_E FE满足:
但是,为了训练这样的回归模型,需要包含不同情感的大型语料库。本文的角度是仅仅使用有限的情感双峰数据,由于训练数据的不充足,DBLSTM训练的效果可能会很差。
4.2 Method(b): 混合数据训练的网络

为了利用到中性的数据,一种方法是混合中立语料和情感语料,使用混合后的数据进行模型的训练。如图1 b所示,随机地从中立语料或情感语料中选取训练数据,输入到DBLSTM模型中,最小化如下的函数:

其中 X N E X_{NE} XNE和 Y N E Y_{NE} YNE表示描述从混合的中立-情感(neutral-emorional)语料中得到的训练数据的LLD(low level descriptors)和FAPs(facial animation parameters)。
对式(2)进行优化可能会导致中性语料库和情感语料库之间回归模型的折衷结果。但是中性的数据量远大于每种情绪类别下的情感数据量,中性数据和情感数据间不均衡的分布可能会导致当需要有情绪的表情时结果却是中性的面部表情。
4.3 Method( c ): 重训练的网络
为了解决Method (b)中的问题,我们提出了另一个方法,可以人为地调整中性数据和情感数据之间的影响比例。如图1 c所示,首先使用中性语料库训练DBLSTM网络,然后使用情感语料库中的数据重训练/微调,以让原始网络中的参数可以适用到情感模型中。重训练的epoch数可以人为地调整以适应于情感语料库的影响。模型可以形式化为如下的形式:

其中 F N → E F_{N\rightarrow E} FN→E表示重训练的DBLSTM网络, X N , Y N X_N, Y_N XN,YN分别表示中性的语音特征(N-LLD)和中性的面部特征(N-FAPs)。
在训练的第一阶段(式(3)), F N → E F_{N\rightarrow E} FN→E中对中性信息敏感的节点被激活。在第二阶段(式(4)),和情感信息有关的节点被激活。对于两个语料库都敏感的节点,它们的权重由式(3)和式(4)进行调整。这种覆盖的程度由第二阶段的epoch数量决定
通过选择合适的epoch数量,我们可以得到在中性数据和情感数据间取得了平衡的理想的模型,并且和仅使用情感数据的模型相比有着更好的性能。然而,决定一个恰当的epoch数是很难的,这与中性数据和情感数据的质量和数量有关。而且,人为选取epoch数可能会对模型引入主观因素。
4.4 Method(d): 双监督网络
为了避免Method©中的人为因素并且解决Method(b)中数据不平衡的问题,我们进一步提出了Method(d),即双监督(dual-supervised)的DBLSTM网络。
本方法最初的想法是:情感面部表现依赖于中性表现。后者提供了初步的面部动画,例如中性的唇动和表现;前者是由中性表现进一步变形而来的。

如图1 d所示,我们首先使用N-LLD作为输入,使用中性数据训练了一个DBLSTM网络,N-FAPs作为输出。然后将E-LLD作为神经网络的输入以得到预测的FAPs(P-FAPs)。P-FAPs和直接从情感语料库中抽取出的E-FAPs是帧对帧对齐的。然后训练情感DBLSTM网络,分别将帧对齐的P-FAPs和E-FAPs作为情感DBLSTM网络的输入和输出:
通过中立DBLSTM网络 F N F_N FN(式(5))可以从中性语料库中得到和初步面部动画相关的信息。然后通过 F N ( X E ) F_N(X_E) FN(XE)预测转换成了P-FAPs。通过优化式(6),考虑从中性数据到表情表达的变形信息的获取。
4.5 Method(e): 级联的网络

情感声音特征中隐含的情感信息对于合成有表现力的虚拟说话人是很关键的。受此启发,我们对Method(d)的方法略加修改得到了新方法Method(e),如图1 e所示。在此方法中,将有情感的E-LLD和预测的P-FAPs级联起来作为输入,来训练情感的DBLSTM网络,E-FAPs是输出:

和Method(d)不同的是,我们将 X E X_E XE和预测的P-FAPs F N ( X E ) F_N(X_E) FN(XE)拼接起来,如式(8)所示,来增强有情感的声音特征对最终的面部动画表现的影响。
5 实验和结果
5.1 实验设置
- Adam是优化器;
- BILSTM隐层的激活函数是tanh;
- 最后一层回归层的激活函数是线性的;
- 所有的DBLSTM网络都有3层隐层,每一层有100个单元;
- 设置Dropout层(dropout=0.3)来避免过拟合;
- LLD特征的维度是384维,FAP特征的维度是46维。
对于情感语料库,我们使用前38个测试者的前4个话语(所有6个情感类别)作为训练集,其余的6个测试者的最后一个话语(utterances)作为测试集。从训练集随机地选取10个话语作为验证集。
在Method(b)中,中性语料库中的321个话语都被添加到了训练集中。在Method©, (d)和(e)中,中性语料库中随机选择出10个话语作为验证集,其余的话语添加到训练集中。
5.2 对不同情绪的客观评价
对模型预测出的FAPs和ground truth使用RMSE(root mean squared error)来评估模型的性能。实验结果如图 2所示,反应了5种不同的方法对6种情绪的RMSE值。这反应了不同的回归模型如何适用于不同的情绪。

图中平均的RMSE值结果可以看出,Method(e)的效果最好,Method©的方法和其也是可比拟的。结果验证了中性的语料库数据为生成具有表现力的虚拟说话人提供了有用的信息。
对于惊讶(surprise)和厌恶(disgust)情绪来说,仅仅使用情感数据训练的方法Method(a)取得了最好的效果。然而,对于悲伤(sadness)来说,Method(a)的效果最差。可能是因为如果要表达惊讶和厌恶的情绪,需要夸大的面部表情和唇动,表达悲伤的情绪则面部表情较为平和。比起夸大的表达,中性语料库中的信息对于平和的表达更具有价值。
5.3 帧级别的客观评价
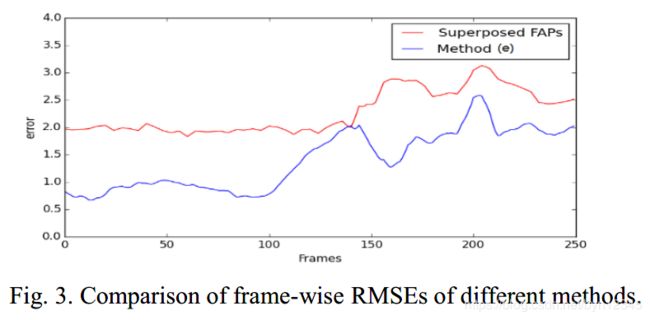
作者还进一步使用RMSE评价指标,在帧级别比较了Method(e)和文献[1]中提出的方法。对比的实验结果如图 3所示。可以看出对于绝大多数帧来说,Method(e)预测结果的RMSE值更小。结果表明,本文提出的方法可以有效地对情绪状态、面部表情和嘴唇动作间的交互进行综合的建模。
5.4 主观评价
我们进一步进行了主观评价来在虚拟说话人系统[2]上测试预测出的FAPs。针对测试集中的话语,模型预测出FAP值,使用这些值生成3D虚拟说话人的视频。让6个测试者根据视频中说话者的表现力和自然性对每个视频进行打分,分值范围为1~5(‘1’ (bad), ‘2’ (poor), ‘3’ (fair), ‘4’ (good) and ‘5’ (excellent) )。每个方法针对不同情绪的平均分值(mean opinion scores, MOS)如图 4所示。

从结果可以看出,平均来说,级联的DBLSTM网络(Method(e))在主观评测中表现的效果最好,这一结果也和客观评价相一致,表明了本文提出方法的有效性。
6 总结和展望
本文提出了几个不同的回归模型来从声音信息中预测出情绪面部参数,用于生成有表现力的虚拟说话人。其中,发音参数由声音输入决定,并受不同的情绪状态下的面部表情的影响。
情绪状态、面部表情和唇动间的交互依赖于声音和语境信息,并随着时间的变化而变化。为了捕获到这样的复杂交互信息,我们采用DBLSTM作为回归模型。由于情感数据的有限,我们提出了一些方法,考察了在使用大型的中性语料库和少量的情感语料库的条件下,捕获到这些交互信息的不同的可能性。
实验表明使用中性语料库有助于提高合成的虚拟说话人的性能。此外,作者还发现应用中性语料库最佳的方法是级联的DBLSTM网络。
未来工作:将文中提到的不同的结构合并到合成面部动画(synthesis facial animation)中,并尝试在单个回归框架中为所有的情绪生成有表现力的面部特征。
本文针对的任务是合成有面部表情的虚拟说话人,模型的输入是语音特征,输出是用于虚拟说话人系统的面部特征。
亮点在于:以现有的有情感信息的语料库数据较少为动机,提出使用大型的情感表现为中性的语料库作为补充。
提出了5个模型,结果表明级联的DBLSTM网络(Method(e))表现效果最好。
参考文献
[1] J. Jia, Z. Wu, S. Zhang,H. Meng, L. Cai, “Head and facial gestures synthesis using PAD model for an expressive talking avatar,” Multimedia Tools and Applications, 73(1): 439-461, 2014.
[2] Z. Wu, S. Zhang, L. Cai, H. Meng, “Real-time synthesis of Chinese visual speech and facial expressions using MPEG4 FAP features in a three-dimensional avatar,” in Proc. ICSLP, pp. 1802-1805, 2006.