Oracle12c Optimizer Statistics Concepts
Optimizer Statistics的简介
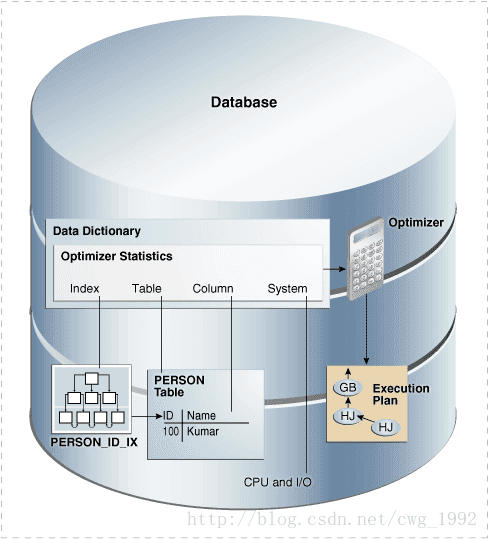
Oracle数据库optimizer statistics描述了数据库及其对象的详细信息。优化成本模型依赖于收集的统计信息查询涉及的对象,并运行查询的数据库和主机。统计挑选最好的一个SQL语句的执行计划
Optimizer statistics 包括以下内容:
表的统计信息
行数
的块数
平均行长度
列统计信息
在一列中的不同值的数目(NDV)
在一列中的空值的数量
数据分布(直方图)
扩展的统计信息
index统计
叶块的数量
级别数
index的聚集因子(Index clustering factor)
系统统计
I / O性能和利用率
CPU性能和利用率
关于 Optimizer Statistics类型
optimizercollects器统计不同的数据库对象和不同的环境有一下几种不同的统计类型
有一下几中:
表统计
字段统计信息
index统计
全局临时表的特定会话统计
系统统计
用户定义的优化统计
Table Statistics(表统计)
在Oracle数据库中,表的统计信息包括行和块的信息。优化器使用这些统计数据来确定表扫描和表联接的成本。DBMS_STATS永久性和临时性的收集和统计表的信息
将永久跟踪数据库相关的表的信息
DBMS_STATS.GATHER_TABLE_STATS在提交之前永久表收集统计。
在DBMS_STATS.GATHER_TABLE_STATS触发前,将对表进行永久统计。
例如,表统计存储在DBA_TAB_STATISTICS如下:
SQL> select NUM_ROWS, AVG_ROW_LEN, BLOCKS, LAST_ANALYZED from DBA_TAB_STATISTICS where table_name = 'T';
NUM_ROWS AVG_ROW_LEN BLOCKS LAST_ANALYZE
-------------------- ------------------------ -------------------------------------
91876 107 1434 28-9月 -13
行数和平均行长度
数据库使用的行计数存储在确定基数时DBA_TAB_STATISTICS。
表的数据块数
优化器使用的数据块的块数与DB_FILE_MULTIBLOCK_READ_COUNT初始化参数确定访问表的基本成本。
Column Statistics(列统计)
列统计信息跟踪列值的信息和数据分布。优化器使用这些统计数据,以产生精确的估计,并做出更好的有关索引的使用决策,加入命令,加入到连接方法等。
例如,索引统计信息在DBA_TAB_COL_STATISTICS跟踪如下:
不同的值(NDV)
空值
最高值和最低值
直方图相关信息(见“直方图”)
优化器可以使用扩展的统计信息,这是一种特殊类型的列统计信息。这些统计数据是有用的通知优化列之间的逻辑关系。
查看例子:
SQL> select table_name, column_name,low_value,last_analyzed from DBA_TAB_COL_STATISTICS where table_name = 'T' and column_name = 'OBJECT_ID';
TABLE_NAME COLUMN_NAME LOW_VALUE LAST_ANALYZE
------------------------ ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
T OBJECT_ID C103 28-9月 -13
Index Statistics(索引统计)
该索引的统计信息包括有关索引级别数,索引块的数量,索引和数据块之间的关系的信息。优化器使用这些统计数据来确定索引扫描的成本。例如,索引的统计信息存储在DBA_IND_STATISTICS视图效果如下:
Levels:
的BLEVEL列显示了需要去从根块到叶子块的块的数目。B树索引有两种类型的块:分块存储值的搜索和叶块。
Distinct keys:
这列跟踪多个不同的索引值。如果定义了唯一约束,如果没有NOT NULL约束定义,那么这个值等于非空值的数量。
不同键值的叶子块数量
SQL> SELECT INDEX_NAME, BLEVEL, LEAF_BLOCKS AS "LEAFBLK", DISTINCT_KEYS AS "DIST_KEY",
AVG_LEAF_BLOCKS_PER_KEY AS "LEAFBLK_PER_KEY",
AVG_DATA_BLOCKS_PER_KEY AS "DATABLK_PER_KEY"
FROM DBA_IND_STATISTICS where INDEX_NAME = 'IND_OWNER'; 2 3 4
INDEX_NAME BLEVEL LEAFBLK DIST_KEY LEAFBLK_PER_KEY DATABLK_PER_KEY
-------------------- ---------- ---------- ---------- ----------------------------- ---------------
IND_OWNER 1 216 23 9 115
Index Clustering Factor (索引Clustering因子)
在B树索引中有clustering因子来衡量一个索引值行的物理分组(原文:the index clustering factor measures the physical grouping of rows in relation to an index value),例如姓氏(原文:such as last name)。
***************************************************************
Index Clustering Factor 索引聚簇因子
SQL> SELECT INDEX_NAME, CLUSTERING_FACTOR
2 FROM ALL_INDEXES
3 WHERE INDEX_NAME IN ('EMP_NAME_IX','EMP_EMP_ID_PK');
INDEX_NAME CLUSTERING_FACTOR
-------------------- -----------------
EMP_EMP_ID_PK 19
EMP_NAME_IX 2
显然,EMP_NAME_IX索引聚簇因子要小很多,因为相邻的索引KEY之间,存取数据位于同一块数据块(data block)上,
检索数据时IO操作消耗很小,
基本可以忽略不计!! ****************************************************************
聚集因子是一些近似的索引关键字在索引块的数目,这些索引块指向的是物理表中的块和行,如果数据库执行全表扫描,数据库将按索引建排序检索存储磁盘上的索引!聚集因子表示分布在数据库中数据块上的所有索引关键字相近的行。如果数据库执行全表扫描,那么数据库将不能纠正在索引键值中的排序行!
该索引聚集因子有助于优化器决定是否某些查询的索引扫描或全表扫描更高效,聚集因子越小,说明索引扫描越高效
索引的聚集因子十一个特定的索引的属性,不是一个表,如果一个表存在多个index,那么一个索引的聚集因子很大,那么另一个就可能很小,如果重建表,尝试提高第一个索引的聚集因子的的同时,可能回降低其他索引的聚集因子。
例子:查看聚集因子和列值的关系
SQL> SELECT table_name, num_rows, blocks FROM user_tables WHERE table_name='T';
TABLE_NAME NUM_ROWS BLOCKS //blocks是表中块的数目
------------------------------------------------ ---------------------- ----------
T 91876 1434
SQL> select INDEX_NAME, TABLE_NAME, COLUMN_NAME from user_ind_columns where table_name='T';
INDEX_NAME TABLE_NAME COLUMN_NAME
------------------------------- ------------------------------ ------------------------------
IND_OWNER T OWNER
SQL> SELECT index_name, blevel, leaf_blocks, clustering_factor FROM user_indexes WHERE table_name='T' AND index_name= 'IND_OWNER';
INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR //clustering_factor是聚集因子 比上边的表的块数高
---------------------- ------------------ ----------------------- --------------------------------
IND_OWNER 1 216 2650
SQL> CREATE TABLE T1 AS SELECT * FROM T ORDER BY OWNER; //创建一个和t一样的表,按索引列排序
表已创建。
SQL> EXEC DBMS_STATS.GATHER_TABLE_STATS(null,'T1'); //收集和统计T2表的信息,执行GATHER_TABLE_STATS job
PL/SQL 过程已成功完成。
SQL> SELECT table_name, num_rows, blocks FROM user_tables WHERE table_name='T1'; //查看表T1的行数和块数
TABLE_NAME
------------------------------------------------------------
NUM_ROWS BLOCKS
---------- ----------
T1
91876 1434
SQL> CREATE INDEX T1_OWNER ON T1(OWNER);
索引已创建。
SQL> SELECT INDEX_NAME, BLEVEL, LEAF_BLOCKS, CLUSTERING_FACTOR FROM USER_INDEXES WHERE TABLE_NAME = 'T1' AND INDEX_NAME = 'T1_OWNER'; //查看表T1的索引T1_OWNER索引的聚集因子
INDEX_NAME
------------------------------------------------------------
BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR
---------- ----------- -----------------
T1_OWNER
1 216 1434
由此可见表的索引列排序后会降低索引的聚集因子,在T表中行数是 91876块属是1434,索引的聚集因子是2650,在T1表中行数和块数和T表一样都是 91876行1434块,但是按照OWNER排序列分布后,聚集因子确实1434,比T表中的小。
如果聚集因子越大则执行计划越不走索引扫描,如果聚集因子越小则索引扫描越高效
*******************************************oracle官方例子************************************************
-
Start SQL*Plus and connect to a database as
sh, and then query the number of rows and blocks in thesh.customerstable (sample output included):SELECT table_name, num_rows, blocks FROM user_tables WHERE table_name='CUSTOMERS'; TABLE_NAME NUM_ROWS BLOCKS ------------------------------ ---------- ---------- CUSTOMERS 55500 1486
-
Create an index on the
customers.cust_last_namecolumn.For example, execute the following statement:
CREATE INDEX CUSTOMERS_LAST_NAME_IDX ON customers(cust_last_name);
-
Query the index clustering factor of the newly created index.
The following query shows that the
customers_last_name_idxindex has a high clustering factor because the clustering factor is significantly more than the number of blocks in the table:SELECT index_name, blevel, leaf_blocks, clustering_factor FROM user_indexes WHERE table_name='CUSTOMERS' AND index_name= 'CUSTOMERS_LAST_NAME_IDX'; INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR ------------------------------ ---------- ----------- ----------------- CUSTOMERS_LAST_NAME_IDX 1 141 9859 -
Create a new copy of the
customerstable, with rows ordered bycust_last_name.For example, execute the following statements:
DROP TABLE customers3 PURGE; CREATE TABLE customers3 AS SELECT * FROM customers ORDER BY cust_last_name;
-
Gather statistics on the
customers3table.For example, execute the
GATHER_TABLE_STATSprocedure as follows:EXEC DBMS_STATS.GATHER_TABLE_STATS(null,'CUSTOMERS3');
-
Query the number of rows and blocks in the
customers3table .For example, enter the following query (sample output included):
SELECT TABLE_NAME, NUM_ROWS, BLOCKS FROM USER_TABLES WHERE TABLE_NAME='CUSTOMERS3'; TABLE_NAME NUM_ROWS BLOCKS ------------------------------ ---------- ---------- CUSTOMERS3 55500 1485
-
Create an index on the
cust_last_namecolumn ofcustomers3.For example, execute the following statement:
CREATE INDEX CUSTOMERS3_LAST_NAME_IDX ON customers3(cust_last_name);
-
Query the index clustering factor of the
customers3_last_name_idxindex.The following query shows that the
customers3_last_name_idxindex has a lower clustering factor:SELECT INDEX_NAME, BLEVEL, LEAF_BLOCKS, CLUSTERING_FACTOR FROM USER_INDEXES WHERE TABLE_NAME = 'CUSTOMERS3' AND INDEX_NAME = 'CUSTOMERS3_LAST_NAME_IDX'; INDEX_NAME BLEVEL LEAF_BLOCKS CLUSTERING_FACTOR ------------------------------ ---------- ----------- ----------------- CUSTOMERS3_LAST_NAME_IDX 1 141 1455The table
customers3has the same data as the originalcustomerstable, but the index oncustomers3has a much lower clustering factor because the data in the table is ordered by thecust_last_name. The clustering factor is now about 10 times the number of blocks instead of 70 times. -
Query the
customerstable.For example, execute the following query (sample output included):
SELECT cust_first_name, cust_last_name FROM customers WHERE cust_last_name BETWEEN 'Puleo' AND 'Quinn'; CUST_FIRST_NAME CUST_LAST_NAME -------------------- ---------------------------------------- Vida Puleo Harriett Quinlan Madeleine Quinn Caresse Puleo
-
Display the cursor for the query.
For example, execute the following query (partial sample output included):
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR()); ------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)|Time| ------------------------------------------------------------------------------- | 0| SELECT STATEMENT | | | | 405 (100)| | |* 1| TABLE ACCESS STORAGE FULL| CUSTOMERS | 2335|35025| 405 (1)|00:00:01| -------------------------------------------------------------------------------
The preceding plan shows that the optimizer did not use the index on the original
customerstables. -
Query the
customers3table.For example, execute the following query (sample output included):
SELECT cust_first_name, cust_last_name FROM customers3 WHERE cust_last_name BETWEEN 'Puleo' AND 'Quinn'; CUST_FIRST_NAME CUST_LAST_NAME -------------------- ---------------------------------------- Vida Puleo Harriett Quinlan Madeleine Quinn Caresse Puleo
-
Display the cursor for the query.
For example, execute the following query (partial sample output included):
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR()); ------------------------------------------------------------------------------- |Id| Operation | Name |Rows|Bytes|Cost(%CPU)|Time| ------------------------------------------------------------------------------- | 0| SELECT STATEMENT | | | |69(100)| | | 1| TABLE ACCESS BY INDEX ROWID|CUSTOMERS3 |2335|35025|69(0)|00:00:01| |*2| INDEX RANGE SCAN |CUSTOMERS3_LAST_NAME_IDX|2335| 7(0)|00:00:01| -------------------------------------------------------------------------------
The result set is the same, but the optimizer chooses the index. The plan cost is much less than the cost of the plan used on the original
customerstable. -
Query
customerswith a hint that forces the optimizer to use the index.For example, execute the following query (partial sample output included):
SELECT /*+ index (Customers CUSTOMERS_LAST_NAME_IDX) */ cust_first_name, cust_last_name FROM customers WHERE cust_last_name BETWEEN 'Puleo' and 'Quinn'; CUST_FIRST_NAME CUST_LAST_NAME -------------------- ---------------------------------------- Vida Puleo Caresse Puleo Harriett Quinlan Madeleine Quinn -
Display the cursor for the query.
For example, execute the following query (partial sample output included):
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR()); ------------------------------------------------------------------------------- | Id | Operation | Name |Rows|Bytes|Cost (%CPU)|Time| ------------------------------------------------------------------------------- | 0| SELECT STATEMENT | | | |422(100)| | | 1| TABLE ACCESS BY INDEX ROWID|CUSTOMERS |335|35025|422(0)|00:00:01| |*2| INDEX RANGE SCAN |CUSTOMERS_LAST_NAME_IDX|2335| |7(0)|00:00:01| -------------------------------------------------------------------------------
The preceding plan shows that the cost of using the index on
customersis higher than the cost of a full table scan. Thus, using an index does not necessarily improve performance. The index clustering factor is an effective measure of whether an using an index is more effective than a full table scan.
聚集因子对成本的影响
聚集因子可以影响访问成本
如果一个表中有9行数据3个数据块
如果在列col中存在三种值A B C
此表的col1列有一个唯一索引
如下所示:
Block 1 Block 2 Block 3 ------- ------- ------- A A A B B B C C C在此索引中聚集因子将很低
在行中某些索引列的值和表中col1列的数据库中的值一样
如果使用范围扫描A值的行 那么数据库将读取整个block1,不许要读取其他它的block
如果数据分布如下:
Block 1 Block 2 Block 3 ------- ------- ------- A B C A C B B A C索引的聚集因子也相对就高了,只有数据库读完所有的包含A值的block才能返回所有A值的行 代价相对就大了很多
Session-Specific统计全局临时表
全局临时表是一个特殊的表,用于存储为特定的时间中间会话私人数据。该ONCOMMIT子句的CREATEGLOBAL TEMPORARY TABLE指示表是否是特定交易(删除行/DELETE ROWS)或特定会话(保留行/PRESERVE ROWS)。因此,临时表中保存中间结果集的交易或会话的持续时间。
当创建一个全局临时表时,你可用定义所有的会话对它都是可以访问,并且没有分配物理存储,如果你插入第一条数据时,数据库将分配给其物理存储空间,数据在临时表里只有当前的会话可见
在以前的版本中,数据库没有维护全局临时表和非全局临时表不同的统计数据。数据库维护统计所有共享会话的一个版本信息,尽管数据因会话的不同而不同,在12cR1数据库启动时,你可用设置TABLE-LEVEL偏好GLOBAL_TEMP_TABLE_STATS特定会话去共享统计的全局临时表。如果设置为特定会话那么你就可以在这个会话中收集全局临时表,但是统计的信息仅限本次会话使用,于此同时用户可以继续维护一个统计的共享版本,在优化过程中,一个全局临时表的优化首先检查是否有特定会话的统计数据。如果有的话的话就优化使用他们,否则,如果共享统计数据存在,则统计起使用共享的统计数据。
特定会话(Session-specific)统计数据的特点:
字典视图将会在当前会话显示共享统计状态和特定会话两者的状态
在DBA_TAB_STATISTICS, DBA_IND_STATISTICS, DBA_TAB_HISTOGRAMS, and DBA_TAB_COL_STATISTICS这些视图(这些视图都有USER_和ALL_的一些文本),在SCOPE列回显示出特定会话和共享统计。
其他会话将不共享 特定会话的统计信息
在以前的版本中,不同的会话可以共享游标使用不同的统计信息,在同一个会话中可以共享游标使用特定会话的统计信息
挂起的统计数据将不支持特定回话的统计
将GLOBAL_TEMP_TABLE_STATS偏好设置到session后,将立即在会话中终止编译的默认GATHER_TABLE_STATS中相同的游标在相同的会话中,当然在GLOBAL_TEMP_TABLE_STATS的会话中不会终止游标的编译。
DBMS_STATS将变化提交到特定会话的全局临时表,但是不会更新到transaction-specific全局临时表,在以前的版本中,在一个transaction-specific的全局临时表运行DBMS_STATS.GATHER_TABLE_STATS,(ON COMMIT DELETE ROWS)回删除表中的所有行,显示统计表为空,在12cR1中执行下边的过程,这些行不会被清除:
-
GATHER_TABLE_STATS -
DELETE_TABLE_STATS -
DELETE_COLUMN_STATS -
DELETE_INDEX_STATS -
SET_TABLE_STATS -
SET_COLUMN_STATS -
SET_INDEX_STATS -
GET_TABLE_STATS -
GET_COLUMN_STATS -
GET_INDEX_STATS
GLOBAL_TEMP_TABLE_STATS设置为偏好
例如:
如果表的选项(preference)被设置为SHARED,SET_TABLE_STATS设置共享统计,如果表的选项被设置为SESSION,那么SET_TABLE_STATS将被设置为SESSION统计!
System Statistics(系统统计)
系统统计将统计I/O和CPU,以便优化器计算一条语句的i/o和cpu成本,来制定执行计划。
系统统计更新后,数据库将不会废除之前的sql语句的解析,数据库解析新的sql语句的时候将使用新的系统统计。
User-Defined Optimizer Statistics(用户自定义优化统计)
由可扩展优化功能的启用者来自定义和创建索引信息收集统计,优化器将按照成本来选择执行计划,利用cpu和I/O的成本并且整合统计的信息来选择语句的执行计划
用户自定义的收集功能会影响到优化器选择执行计划,如果要使用一个类型的统计,就需要一个绑定到数据库对象的列,独立的功能,对象类型,索引,索引类型,或者包的机制,SQL语句ASSOCIATE STATISTICS将和他们创建关联
用户自定义统计功能在相应的列和索引索引使用标准的SQL数据类型和对象类型,必须结合统计的一个列的类型和index,数据调用DBMS_STATS 来收集和统计数据库对象!
收集模式和表统计
扩展的优化和用户定义的统计
How the Database Gathers Optimizer Statistics(什么是收集数据库优化统计)
动态统计(Dynamic Statistics)
在线分散收集统计(Online Statistics Gathering for Bulk Loads)
DBMS_STATS Package
DBMS_STATS PL / SQL包,收集和管理优化统计。此包可以让你管理和统计 统计管理。包括并行的统计收集,采样方法和在分区表上收集统计的颗粒等!
DBMS_STATS包收集的统计信息需要创建准确的执行计划。例如,使用DBMS_STATS统计收集的包括的行数,块数和平均行长度。
默认情况下,Oracle数据库使用自动优化统计信息收集。如果数据库自动运行使用DBMS_STATS收集优化统计信息,所有其他模式收集的统计数据都会失效。
也可以通过配置DBMS_STATS来手动管理优化统计。
Dynamic Statistics(动态统计)
在默认情况下,数据库自动统计优化或者统计数据时,缺少或者需要新增统计数据,那么数据库回自动进行动态收集和分析统计数据,一个递归语句随机去扫描一个表中的小数据块进行随机采样。动态统计可以统计,如表和索引块数,表和索引(估计的行数),结合列的统计数据,统计和GROUP BY。此信息有助于优化改进方案更好地估计谓词选择性。
以下情况有利于动态统计:
由于复杂谓词造成不理想的执行计划
采样时间是请求执行时间的一小部分
请求多次,将采样时间摊销
Online Statistics Gathering for Bulk Loads(分散统计)
在12cR1 数据库启动时数据库会分散统计自动收集表的一下几种类型:
CREATE TABLE AS SELECT
INSERT INTO ... SELECT直接插入到表中
默认情况下,的并行插入使用直接路径插入。您可以强制使用/ * + APPEND * /提示直接路径插入。
当数据正在插入一个空白的分区表,在插入过程中数据库会收集全局的统计数据,如果运行 INSERT INTO SALES SELECT,如果SALES是一个空的分区表,那么数据库会收集SALES表全局的统计数据,但是不会收集分区级别的统计。
如果将数据插入时加上扩展语法指定分区或者子分区为空,那么数据库在插入的时候回统计收集指定分区或者子分区,如果没有全局级别统计,如果运行INSERT INTO sales PARTITION (sales_q4_2000) SELECT和sales_q4_2000分区表是空的,然后插入(其他分区需要不能为空)时数据库回进行收集和统计。此外,如果启用表的INCREMENTAL,那么数据库还回收集sales_q4_2000的概况(如何启用INCREMENTAL),在insert时立即启用统计,在分散统计中,如果回滚事务,则数据库回自动删除统计数据!
INSERT INTO ... SELECT插入一个非空表或者分区表或者子分区表
这种情况下,OPTIMIZER STATISTICS GATHERING的元数据行出现在执行计划中,不过此源数据行仅仅是一个pass-through(经过),检查字典表看是否有优化统计器统计的信息,在分散统计列的时候有个视图DBA_TAB_COL_STATISTICS记录显示出STATS_ON_LOA的值。
期间收集统计数据的情况,避免了额外的表扫描来收集表的统计信息。
改进的可管理性
没有用户干预的需要来收集统计信息后分散统计。
在线收集统计,数据库不会收集索引统计信息或直方图。如果这些统计数据是必需的,那么oracle建议将DBMS_STATS.GATHER_TABLE_STATS设置为GATHER AUTO运行,然后在批量加载(then Oracle recommends running DBMS_STATS.GATHER_TABLE_STATS with the options parameter set to GATHER AUTO after the bulk load)。这种情况下只有将GATHER_TABLE_STATS丢弃,或者标记为陈旧的统计。
默认情况下数据库回批量加载分散统计数据,不过你可以禁止它用NO_GATHER_OPTIMIZER_STATISTICS参数,也可以启用它用GATHER_OPTIMIZER_STATISTICS,例子:
CREATE TABLE employees2 AS SELECT /*+NO_GATHER_OPTIMIZER_STATISTICS */* FROM employees
目前,下列条件数据库将不统计和收集数据:
它是一个数据库所有者 例如:SYS。
这是一个嵌套表。
这是一个索引组织表(IOT)。
它是一个外部表。
这是一个全局临时表定义为ONCOMMIT DELETE ROWS。
它有虚拟列。
它有一个发布首选项设置为FALSE。
分区表,INCREMENTAL设置为true,并且不使用扩展语法。
例子:
如果你发现DBMS_STATS.SET_TABLE_PREFS(null,'sales', incremental','true'),则数据库不收集和统计INSERT INTO sales SELECT,但是它可以收集统计INSERT INTO sales PARTITION (sales_q4_2000) SELECT.
When the Database Gathers Optimizer Statistics
数据库在不同的时间和不同的来源收集统计信息,它将使用如下来源:DBMS_STATS程序的执行,自动或手动 //DBMS_STATS.GATHER_TABLE_STATS
SQL编译 //运行额为的查询,获得更精确的信息,查询表中有多少行满足WHERE子句谓词的SQL语句
SQL执行 //在执行过程中,数据库可以进一步扩大先前收集的统计数据。在这个过程中,数据库将收集sql语句执行过程中每一个行的源行数,在sql执行结束时,优化器会按照估计的行数和实际返回行数来决定这个统计是否准确,以确保下一个执行计划的正确选择。
SQL配置文件 //SQL配置文件是辅助查询统计的集合。配置文件在数据字典里存储这些辅助统计的。优化器在选择执行计划的时候用这些配置文件以确保选择最优的执行计划。
数据统计存储在数据字典中,这些统计需要随着数据的变更进行更新和替换,可以在数据字典视图查看统计数据
本节包含了以下主题:
SQL的执行计划
数据库的采样数据
什么是数据库的采样数据
SQL Plan Directives(执行计划)
执行计划是由优化器在众多的执行方法中选择出来的最优的执行方案。About SQL Plan Directives
在sql执行期间,如果发生错估现象,数据库将产生执行计划。同时编译SQL, 优化检查查询相应的sql,以确定是否存扩展或直方图(see "Managing Extended Statistics),然后优化器会记录丢失或者陈旧的统计,以后再由DBMS_STATS去统计
优化器使用动态采样时,它没有足够的统计对应的指令。例如,优化器进行动态取样,直到创建列组统计数据,也这一点后发生misestimates时。目前,优化监控仅列组。优化不创建一个扩展表达式。
SQL计划指令是不依赖于一个特定的SQL语句或SQLID。优化器可以使用指令几乎是相同的语句,因为指令被定义查询表达式。
数据库可以自动管理执行计划,数据库回将sql创建到共享池中,并且定期将命令写入SYSAUX表空间,可以用DBMS_SPD包的API指令来管理!
10.4.1.2 How the Optimizer Uses SQL Plan Directives: Example
优化器如何使用优化器来选择执行计划查看优化器估算的行和实际返回的行
SELECT /*+gather_plan_statistics*/ * FROM customers WHERE cust_state_province='CA' AND country_id='US';gather_plan_statistics提示显示从该计划中的每个操作返回的行的实际数目。因此,你可以比较优化器的估算与实际返回的行数。
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'ALLSTATS LAST'));
PLAN_TABLE_OUTPUT
-------------------------------------
SQL_ID b74nw722wjvy3, child number 0
-------------------------------------
select /*+gather_plan_statistics*/ * from customers where
CUST_STATE_PROVINCE='CA' and country_id='US'
Plan hash value: 1683234692
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 29 |00:00:00.01 | 17 | 14 |
|* 1 | TABLE ACCESS FULL| CUSTOMERS | 1 | 8 | 29 |00:00:00.01 | 17 | 14 |
--------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(("CUST_STATE_PROVINCE"='CA' AND "COUNTRY_ID"='US')) The actual number of rows (
A-Rows) returned by each operation in the plan varies greatly from the estimates (
E-Rows). This statement is a candidate for
automatic reoptimization (see "Automatic Reoptimization").
//A-Rows是实际返回的行 E-Rows是估计返回的行
检查客户查询是否可以重新优化。
SELECT SQL_ID, CHILD_NUMBER, SQL_TEXT, IS_REOPTIMIZABLE
FROM V$SQL
WHERE SQL_TEXT LIKE 'SELECT /*+gather_plan_statistics*/%';
SQL_ID CHILD_NUMBER SQL_TEXT I
------------- ------------ ----------- -
b74nw722wjvy3 0 select /*+g Y
ather_plan_
statistics*
/ * from cu
stomers whe
re CUST_STA
TE_PROVINCE
='CA' and c
ountry_id='
US' IS_REOPTIMIZABLE这个的值为Y的时候需要重新优化
显示一个用户已存储的sql的执行计划
EXEC DBMS_SPD.FLUSH_SQL_PLAN_DIRECTIVE;
SELECT TO_CHAR(d.DIRECTIVE_ID) dir_id, o.OWNER, o.OBJECT_NAME,
o.SUBOBJECT_NAME col_name, o.OBJECT_TYPE, d.TYPE, d.STATE, d.REASON
FROM DBA_SQL_PLAN_DIRECTIVES d, DBA_SQL_PLAN_DIR_OBJECTS o
WHERE d.DIRECTIVE_ID=o.DIRECTIVE_ID
AND o.OWNER IN ('SH')
ORDER BY 1,2,3,4,5;
DIR_ID OWNER OBJECT_NAME COL_NAME OBJECT TYPE STATE REASON
----------------------- ----- ------------- ----------- ------ ---------------- ----- ------------------------
1484026771529551585 SH CUSTOMERS COUNTRY_ID COLUMN DYNAMIC_SAMPLING NEW SINGLE TABLE CARDINALITY
MISESTIMATE
1484026771529551585 SH CUSTOMERS CUST_STATE_ COLUMN DYNAMIC_SAMPLING NEW SINGLE TABLE CARDINALITY
PROVINCE MISESTIMATE
1484026771529551585 SH CUSTOMERS TABLE DYNAMIC_SAMPLING NEW SINGLE TABLE CARDINALITY
MISESTIMATE 最初sql的执行计划被存储在内存中,15分钟后写入磁盘(表空间),此处调用
DBMS_SPD.FLUSH_SQL_PLAN_DIRECTIVE存储过程强制数据库SYSAUX表空间!
监控用视图DBA_SQL_PLAN_DIRECTIVES和DBA_SQL_PLAN_DIR_OBJECTS,还有一个是客户表本身和每个相关列,因为客户查询有IS_REOPTIMIZABLE的Y值,如果重新执行该语句,那么数据库将很难解析一遍,然后生成一个计划的基础上先前执行统计。
再次查询客户表
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'ALLSTATS LAST'));
PLAN_TABLE_OUTPUT
-------------------------------------
SQL_ID b74nw722wjvy3, child number 1
-------------------------------------
select /*+gather_plan_statistics*/ * from customers where
CUST_STATE_PROVINCE='CA' and country_id='US'
Plan hash value: 1683234692
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 29 |00:00:00.01 | 17 |
|* 1 | TABLE ACCESS FULL| CUSTOMERS | 1 | 29 | 29 |00:00:00.01 | 17 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(("CUST_STATE_PROVINCE"='CA' AND "COUNTRY_ID"='US'))
Note
-----
- cardinality feedback used for this statement 可见E-Rows已经更改了,上次查询的估算是8,这次是29
再查看是否需要重新优化
SELECT SQL_ID, CHILD_NUMBER, SQL_TEXT, IS_REOPTIMIZABLE
FROM V$SQL
WHERE SQL_TEXT LIKE 'SELECT /*+gather_plan_statistics*/%';
SQL_ID CHILD_NUMBER SQL_TEXT I
------------- ------------ ----------- -
b74nw722wjvy3 0 select /*+g Y
ather_plan_
statistics*
/ * from cu
stomers whe
re CUST_STA
TE_PROVINCE
='CA' and c
ountry_id='
US'
b74nw722wjvy3 1 select /*+g N
ather_plan_
statistics*
/ * from cu
stomers whe
re CUST_STA
TE_PROVINCE
='CA' and c
ountry_id='
US' 可见第二次查询IS_REOPTIMIZABLE的值为N,所以不许要重新优化
存在一个新的计划,为客户查询,也是一个新的子游标。
确认一个SQL计划指令的存在,是用于其他报表
SELECT /*+gather_plan_statistics*/ CUST_EMAIL FROM CUSTOMERS WHERE CUST_STATE_PROVINCE='MA' AND COUNTRY_ID='US';模拟上一个查询,语法相同但是查询的where的条件不同
查看执行计划和估算
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'ALLSTATS LAST'));
PLAN_TABLE_OUTPUT
-------------------------------------
SQL_ID 3tk6hj3nkcs2u, child number 0
-------------------------------------
Select /*+gather_plan_statistics*/ cust_email From customers Where
cust_state_province='MA' And country_id='US'
Plan hash value: 1683234692
-------------------------------------------------------------------------------
|Id | Operation | Name | Starts|E-Rows|A-Rows| A-Time |Buffers|
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 2 |00:00:00.01| 16 |
|*1 | TABLE ACCESS FULL| CUSTOMERS | 1 | 2| 2 |00:00:00.01| 16 |
-----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(("CUST_STATE_PROVINCE"='MA' AND "COUNTRY_ID"='US'))
Note //此处,采用了陈旧的优化
-----
- dynamic sampling used for this statement (level=2)
- 1 Sql Plan Directive used for this statement
The Note section of the plan shows that the optimizer used the SQL directive for this statement, and also used dynamic statistics.
查询指令的状态确定是否已经发生变化
查看数据字典信息的指令,确定优化是否生效
EXEC DBMS_SPD.FLUSH_SQL_PLAN_DIRECTIVE;
SELECT TO_CHAR(d.DIRECTIVE_ID) dir_id, o.OWNER, o.OBJECT_NAME,
o.SUBOBJECT_NAME col_name, o.OBJECT_TYPE, d.TYPE, d.STATE, d.REASON
FROM DBA_SQL_PLAN_DIRECTIVES d, DBA_SQL_PLAN_DIR_OBJECTS o
WHERE d.DIRECTIVE_ID=o.DIRECTIVE_ID
AND o.OWNER IN ('SH')
ORDER BY 1,2,3,4,5;
DIR_ID OW OBJECT_NA COL_NAME OBJECT TYPE STATE REASON
------------------- -- --------- ---------- ------- --------------- ------------- ------------------------
1484026771529551585 SH CUSTOMERS COUNTRY_ID COLUMN DYNAMIC_SAMPLING MISSING_STATS SINGLE TABLE CARDINALITY
MISESTIMATE
1484026771529551585 SH CUSTOMERS CUST_STATE_ COLUMN DYNAMIC_SAMPLING MISSING_STATS SINGLE TABLE CARDINALITY
PROVINCE MISESTIMATE
1484026771529551585 SH CUSTOMERS TABLE DYNAMIC_SAMPLING MISSING_STATS SINGLE TABLE CARDINALITY
MISESTIMATE
SQL计划指令现在有的状态MISSING_STATS。这种状态意味着数据库已经自动确定扩展的统计,
在列组统计的形式,可以解决这个问题。
所以,如果你收集客户表的统计数据,那么你也应该看到一个新的列组会自动创建在cust_state_province两个和COUNTRY_ID列。
********************************************************************************************************************************
See Also:
-
"Managing SQL Plan Directives"
-
Oracle Database Reference to learn about
DBA_SQL_PLAN_DIRECTIVES,V$SQL, and other database views -
Oracle Database Reference to learn about
DBMS_SPD
例子:统计某个用户的某个表此处是(sh.CUSTOMERS)
收集统计sh用户的customers表
BEGIN
DBMS_STATS.GATHER_TABLE_STATS('SH','CUSTOMERS');
END;
/ 查看统计
SELECT TABLE_NAME, EXTENSION_NAME, EXTENSION
FROM DBA_STAT_EXTENSIONS
WHERE OWNER='SH'
AND TABLE_NAME='CUSTOMERS';
TABLE_NAM EXTENSION_NAME EXTENSION
--------- ------------------------------ -----------------------------------
CUSTOMERS SYS_STU#S#WF25Z#QAHIHE#MOFFMM_ ("CUST_STATE_PROVINCE","COUNTRY_ID")
查询SQL计划指令的状态。
EXEC DBMS_SPD.FLUSH_SQL_PLAN_DIRECTIVE;
SELECT TO_CHAR(d.DIRECTIVE_ID) dir_id, o.OWNER, o.OBJECT_NAME,
o.SUBOBJECT_NAME col_name, o.OBJECT_TYPE, d.TYPE, d.STATE, d.REASON
FROM DBA_SQL_PLAN_DIRECTIVES d, DBA_SQL_PLAN_DIR_OBJECTS o
WHERE d.DIRECTIVE_ID=o.DIRECTIVE_ID
AND o.OWNER IN ('SH')
ORDER BY 1,2,3,4,5;
DIR_ID OWN OBJECT_NA COL_NAME OBJECT TYPE STATE REASON
------------------- --- --------- ---------- ------- ---------------- ------------- --------------------
1484026771529551585 SH CUSTOMERS COUNTRY_ID COLUMN DYNAMIC_SAMPLING MISSING_STATS SINGLE TABLE CARDINALITY
MISESTIMATE
1484026771529551585 SH CUSTOMERS CUST_STATE_ COLUMN DYNAMIC_SAMPLING MISSING_STATS SINGLE TABLE CARDINALITY
PROVINCE MISESTIMATE
1484026771529551585 SH CUSTOMERS TABLE DYNAMIC_SAMPLING MISSING_STATS SINGLE TABLE CARDINALITY
MISESTIMATE
列组统计虽然存在,该指令有的MISSING_STATS状态,因为该数据库尚未重新编译的语句,随后统计器验证统计数据是否准确,
如果它们是准确的,则状态的指令更改HAS_STATS。随后的编译使用的统计数据,而不用SQL。
查询sh.customers表
SELECT /*+gather_plan_statistics*/ * FROM customers WHERE cust_state_province='CA' AND country_id='US';查看计划
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'ALLSTATS LAST'));
PLAN_TABLE_OUTPUT
-------------------------------------
SQL_ID b74nw722wjvy3, child number 0
-------------------------------------
select /*+gather_plan_statistics*/ * from customers where
CUST_STATE_PROVINCE='CA' and country_id='US'
Plan hash value: 1683234692
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 29 |00:00:00.01 | 16 |
|* 1 | TABLE ACCESS FULL| CUSTOMERS | 1 | 29 | 29 |00:00:00.01 | 16 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(("CUST_STATE_PROVINCE"='CA' AND "COUNTRY_ID"='US'))
Note
-----
- dynamic sampling used for this statement (level=2)
- 1 Sql Plan Directive used for this statement
查看状态
EXEC DBMS_SPD.FLUSH_SQL_PLAN_DIRECTIVE;
SELECT TO_CHAR(d.DIRECTIVE_ID) dir_id, o.OWNER, o.OBJECT_NAME,
o.SUBOBJECT_NAME col_name, o.OBJECT_TYPE, d.TYPE, d.STATE, d.REASON
FROM DBA_SQL_PLAN_DIRECTIVES d, DBA_SQL_PLAN_DIR_OBJECTS o
WHERE d.DIRECTIVE_ID=o.DIRECTIVE_ID
AND o.OWNER IN ('SH')
ORDER BY 1,2,3,4,5;
DIR_ID OWN OBJECT_NAME COL_NAME OBJECT TYPE STATE REASON
------------------- --- ----------- ---------- ------- ---------------- --------- ------------------------
1484026771529551585 SH CUSTOMERS COUNTRY_ID COLUMN DYNAMIC_SAMPLING HAS_STATS SINGLE TABLE CARDINALITY
MISESTIMATE
1484026771529551585 SH CUSTOMERS CUST_STATE_ COLUMN DYNAMIC_SAMPLING HAS_STATS SINGLE TABLE CARDINALITY
PROVINCE MISESTIMATE
1484026771529551585 SH CUSTOMERS TABLE DYNAMIC_SAMPLING HAS_STATS SINGLE TABLE CARDINALITY
MISESTIMATE 状态已经是HAS_STATS
永不同的语句再次查询sh.customers表
SELECT /*+gather_plan_statistics*/ /* force reparse */ * FROM customers WHERE cust_state_province='CA' AND country_id='US';
查看游标计划
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR(FORMAT=>'ALLSTATS LAST'));
PLAN_TABLE_OUTPUT
-------------------------------------
SQL_ID b74nw722wjvy3, child number 0
-------------------------------------
select /*+gather_plan_statistics*/ * from customers where
CUST_STATE_PROVINCE='CA' and country_id='US'
Plan hash value: 1683234692
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 29 |00:00:00.01 | 17 |
|* 1 | TABLE ACCESS FULL| CUSTOMERS | 1 | 29 | 29 |00:00:00.01 | 17 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(("CUST_STATE_PROVINCE"='CA' AND "COUNTRY_ID"='US'))
19 rows selected.
The absence of a Note shows that the optimizer used the extended statistics instead of the SQL plan directive. If the directive is not used for 53 weeks, then the database automatically purges it.
//如果编译的游标53周内不再使用,那么数据库将自动清除这个游标。
********************************************************************************************************************************
See Also:
-
"Managing SQL Plan Directives"
-
Oracle Database Reference to learn about
DBA_SQL_PLAN_DIRECTIVES,V$SQL, and other database views -
Oracle Database Reference to learn about
DBMS_SPD
When the Database Samples Data(数据库采样数据)
在以前的版本中,数据库总是收集动态统计(以前称为动态采样)在优化过程中,只有当表中查询有没有这方面的统计数字。在Oracle数据库12c的第1版(12.1)开始,数据库会决定是否是有用的动态统计和统计级别的所有sql。
决定使用动态统计的首要因素是是否可用统计足以产生一个最优计划。如果统计是不够的,那么优化器使用动态统计。
任何下列条件时是真实的启用自动动态统计:
该初始化参数OPTIMIZER_DYNAMIC_SAMPLING使用它的默认值这意味着它没有明确设置。
OPTIMIZER_DYNAMIC_SAMPLING初始化参数被设置为11。
您调用的动态统计通过一个SQL指定解释“控制动态统计”的收集。
在一般情况下,在优化器将使用默认统计数据而不是动态统计数据表,索引和列优化过程中需要计算统计。优化器决定是否使用动态统计基于几个因素。例如,数据库在下列情况下使用自动动态统计:
-
The SQL statement uses parallel execution.
-
A SQL plan directive exists.
-
The SQL statement is known to the database, which means that it was captured in SQL Plan Management or Automatic Workload Repository, or is currently in the shared SQL area.
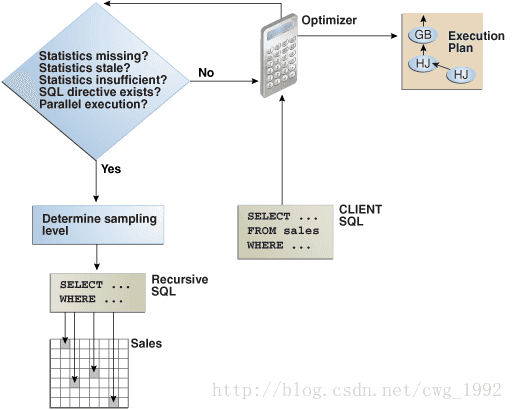
如图10-2所示,优化自动收集动态统计,在下列情况下:
缺少的统计信息
当查询表中没有统计,优化优化前收集的基本统计资料,对这些表。统计可以缺少,因为应用程序创建新的对象,没有了后续的呼叫DBMS_STATS来收集统计信息,或由于统计对象上锁定前收集统计。
在这种情况下,统计数据不作为高品质的或完整的,因为收集的统计信息使用DBMS_STATS程序包。这种权衡作出限制语句的编译时间上的影响。
陈旧的统计
DBMS_STATS收集的统计信息,可以成为日期。通常情况下,统计数据是陈旧的,当10 %或更多的表中的行已经改变了自从上一次统计收集。
统计数据不足
可统计不足时,优化器估计谓词的选择性(过滤器或连接)或GROUP BY子句中的列,列数据分布偏斜,统计表达式之间没有考虑到帐户关联,等等。
扩展的统计信息,帮助优化器获得准确的基数估计复杂谓词表达式(请参阅“关于列组统计” ) 。优化器可以使用动态的统计,以弥补缺乏扩展的统计信息,或当它不能使用扩展的统计信息,例如,非平等谓词。
********************************************************************************************************************************
Note:
The database does not use dynamic statistics for queries that contain theAS OF clause.
See Also:
Oracle Database Reference to learn about theOPTIMIZER_DYNAMIC_SAMPLING initialization parameter
********************************************************************************************************************************
How the Database Samples Data(数据库的样本数据)
在优化开始时,决定表是否是一个候选的动态统计,优化检查是否存在持久的SQL计划指令表(见图10-2 ) 。 对于每一个指令,优化登记统计表达式优化计算时,它必须确定涉及的表的谓词的选择性。
当采样是必要的,数据库必须确定样本的大小(见图10-2 ) 。 在Oracle数据库12c的第1版(12.1)开始, ,如果OPTIMIZER_DYNAMIC_SAMPLING初始化参数没有明确设置为11以外的值,那么优化器会自动决定是否使用动态统计和使用水平。
在图10-2中,数据库发出一个递归的SQL语句来扫描一个小的随机抽样表块。 数据库应用相关的单表谓词和联接谓词的选择性估计。
该数据库仍然存在共享统计数据的动态统计的结果。 该数据库可以共享的结果,在相同的查询重新编译一个查询的SQL编译。 该数据库也可以重复使用为具有相同的模式的查询的结果。 如果没有行被插入,删除或更新表中被采样,然后利用动态统计数据是重复的。
###########################
迷途小运维翻译,E文不好,如有错误请不吝赐教
作者:john
转载请注明出处