hadoop 2.7.1命令示例
hadoop可以运行很多命令,如下为收集到一些命令。
一、用户命令
1、archive命令
(1).什么是Hadoop archives?
Hadoop archives是特殊的档案格式。一个Hadoop archive对应一个文件系统目录。 Hadoop archive的扩展名是*.har。Hadoop archive包含元数据(形式是_index和_masterindx)和数据文件(part-*)。_index文件包含了档案中的文件的文件名和位置信息。
(2).如何创建archive?
用法:hadoop archive -archiveName NAME
命令选项:
-archiveName NAME 要创建的档案的名字。
src 源文件系统的路径名。
dest 保存档案文件的目标目录。
范例:
例1.将/user/hadoop/dir1和/user/hadoop/dir2归档到/user/zoo/文件系统目录下–/user/zoo/foo.har。
hadoop@ubuntu:~/ hadoop archive -archiveName foo.har /user/hadoop/dir1 /user/hadoop/dir2 /user/zoo/
当创建archive时,源文件foo.har不会被更改或删除。
(3).如何查看archives中的文件?
archive作为文件系统层暴露给外界。所以所有的fs shell命令都能在archive上运行,但是要使用不同的URI。另外,archive是不可改变的。所以创建、重命名和删除都会返回错误。Hadoop Archives的URI是har://scheme-hostname:port/archivepath/fileinarchive。
如果没提供scheme-hostname,它会使用默认的文件系统。这种情况下URI是这种形式har:///archivepath/fileinarchive。
范例:
例1.archive的输入是/dir,该dir目录包含文件filea和fileb,现把/dir归档到/user/hadoop/foo.bar。
hadoop@ubuntu:~/ hadoop archive -archiveName foo.har /dir /user/hadoop
例2.获得创建的archive中的文件列表
hadoop@ubuntu:~/hadoop dfs -lsr har:///user/hadoop/foo.har
例3.查看archive中的filea文件
hadoop@ubuntu:~/hadoop dfs -cat har:///user/hadoop/foo.har/dir/filea
2、distcp
说明:用于集群内部或者集群之间拷贝数据的常用命令(顾名思义: dist即分布式,分布式拷贝是也。)。
用法:hadoop distcp [选项] src_url dest_url
命令选项:
-m 表示启用多少map
-delete 删除已经存在的目标文件,不会删除源文件。这个删除是通过FS Shell实现的。所以如果垃圾回收机制启动的话,删除的目标文件会进入trash。
-i 忽略失败。这个选项会比默认情况提供关于拷贝的更精确的统计,同时它还将保留失败拷贝操作的日志,这些日志信息可以用于调试。最后,如果一个map失败了,但并没完成所有分块任务的尝试,这不会导致整个作业的失败。
-overwrite 覆盖目标。如果一个map失败并且没有使用-i选项,不仅仅那些拷贝失败的文件,这个分块任务中的所有文件都会被重新拷贝。 所以这就是为什么要使用-i参数。
范例:
例1.
hadoop@ubuntu:~/ hadoop distcp "hdfs://A:8020/user/foo/bar" "hdfs://B:8020/user/foo/baz"
3、fs
说明:运行一个常规的文件系统客户端。
用法:hadoop fs [GENERIC_OPTIONS] [COMMAND_OPTIONS]
各种命令选项可以参考HDFS Shell指南。
所有的FS shell命令带有URIs路径参数。The URI 格式是://authority/path。对 HDFS文件系统,scheme是hdfs。其中scheme和 authority参数都是可选的
如果没有指定,在文件中使用默认scheme.一个hdfs文件或则目录比如 /parent/child,可以是 hdfs://namenodehost/parent/child 或则简化为/parent/child(默认配置设置成指向hdfs://namenodehost).大多数FS shell命令对应 Unix 命令.每个命令都有不同的描述。将错误信息发送到标准错误输出和输出发送到stdout。
appendToFile【添加文件】
用法: hadoop fs -appendToFile
- hadoop fs -appendToFile localfile /user/hadoop/hadoopfile
- hadoop fs -appendToFile localfile1 localfile2 /user/hadoop/hadoopfile
- hadoop fs -appendToFile localfile hdfs://nn.example.com/hadoop/hadoopfile
- hadoop fs -appendToFile - hdfs://nn.example.com/hadoop/hadoopfile Reads the input from stdin.
返回 0成功返回 1 错误
cat
用法: hadoop fs -cat URI [URI ...]
将路径指定文件的内容输出到stdout
例子:
- hadoop fs -cat hdfs://nn1.example.com/file1 hdfs://nn2.example.com/file2
- hadoop fs -cat file:///file3 /user/hadoop/file4
返回 0成功返回 1 错误
checksum
用法: hadoop fs -checksum URI
返回 checksum 文件信息
例子:
- hadoop fs -checksum hdfs://nn1.example.com/file1
- hadoop fs -checksum file:///etc/hosts
chgrp
用法: hadoop fs -chgrp [-R] GROUP URI [URI ...]
改变文件所属组. 必须是文件所有者或则超级用户. 更多信息在 Permissions Guide.
选项
- 使用-R 将使改变在目录结构下递归进行
chmod
用法: hadoop fs -chmod [-R]
更改文件的权限. 使用-R 将使改变在目录结构下递归进行。 必须是文件所有者或则超级用户. 更多信息在 Permissions Guide.
选项
- 使用-R 将使改变在目录结构下递归进行。
chown
用法: hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
更改文件的所有者. 使用-R 将使改变在目录结构下递归进行。 必须是文件所有者或则超级用户. 更多信息在 Permissions Guide.
选项
- 使用-R 将使改变在目录结构下递归进行。
copyFromLocal
用法: hadoop fs -copyFromLocal
类似put命令, 需要指出的是这个限制是本地文件
选项:
- -f 选项会重写已存在的目标文件
copyToLocal
用法: hadoop fs -copyToLocal [-ignorecrc] [-crc] URI
与get命令类似, 除了限定目标路径是一个本地文件外。
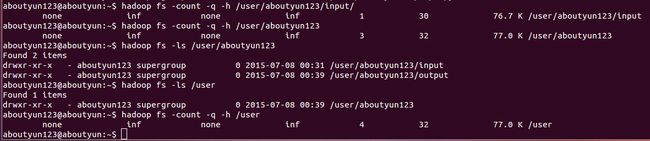
count
用法: hadoop fs -count [-q] [-h] [-v]
【目录个数,文件个数,总大小,路径名称】
输出列带有 -count -q 是: QUOTA, REMAINING_QUATA, SPACE_QUOTA, REMAINING_SPACE_QUOTA, DIR_COUNT, FILE_COUNT, CONTENT_SIZE, PATHNAME
【配置,其余指标,空间配额,剩余空间定额,目录个数,文件个数,总大小,路径名称】
The -h 选项,size可读模式.
The -v 选项显示一个标题行。
Example:
- hadoop fs -count hdfs://nn1.example.com/file1 hdfs://nn2.example.com/file2
- hadoop fs -count -q hdfs://nn1.example.com/file1
- hadoop fs -count -q -h hdfs://nn1.example.com/file1
- hdfs dfs -count -q -h -v hdfs://nn1.example.com/file1
返回 0成功返回 1 错误
cp
用法: hadoop fs -cp [-f] [-p | -p[topax]] URI [URI ...]
‘raw.*’ 命名空间扩展属性被保留
(1)源文件和目标文件支持他们(仅hdfs)
(2)所有的源文件和目标文件路径在 /.reserved/raw目录结构下。
决定是否使用 raw.*命名空间扩展属性依赖于-P选项
选项:
- -f 选项如果文件已经存在将会被重写.
- -p 选项保存文件属性 [topx] (timestamps, ownership, permission, ACL, XAttr). 如果指定 -p没有参数, 保存timestamps, ownership, permission. 如果指定 -pa, 保留权限 因为ACL是一个权限的超级组。确定是否保存raw命名空间属性取决于是否使用-p决定
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
返回 0成功返回 1 错误
createSnapshot
查看 HDFS Snapshots Guide.
deleteSnapshot
查看 HDFS Snapshots Guide.
df【查看还剩多少hdfs空间】
用法: hadoop fs -df [-h] URI [URI ...]
显示剩余空间
选项:
- -h 选项会让人更加易读 (比如 64.0m代替 67108864)
- hadoop dfs -df /user/hadoop/dir1

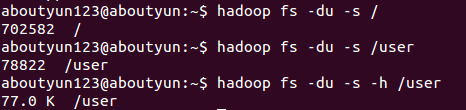
du
用法: hadoop fs -du [-s] [-h] URI [URI ...]显示给定目录的文件大小及包含的目录,如果只有文件只显示文件的大小
选项:
- -s 选项汇总文件的长度,而不是现实单个文件.
- -h 选项显示格式更加易读 (例如 64.0m代替67108864)
- hadoop fs -du /user/hadoop/dir1 /user/hadoop/file1 hdfs://nn.example.com/user/hadoop/dir1
返回 0成功返回 1 错误
dus
用法: hadoop fs -dus
显示统计文件长度
注意:这个命令已被启用, hadoop fs -du -s即可
expunge
用法: hadoop fs -expunge
清空垃圾回收站. 涉及 HDFS Architecture Guide 更多信息查看回收站特点
find
用法: hadoop fs -find
下面主要表达式:
- -name 模式
-iname 模式
值为TRUE如果文件基本名匹配模式使用标准的文件系统组合。如果使用-iname匹配不区分大小写。
- -print
-print0Always
值为TRUE. 当前路径被写至标准输出。如果使用 -print0 表达式, ASCII NULL 字符是追加的.
- expression -a expression
expression -and expression
expression expression
例子:
hadoop fs -find / -name test -print
返回代码:
返回 0成功返回 1 错误

get
用法: hadoop fs -get [-ignorecrc] [-crc]
复制文件到本地文件系统. 【CRC校验失败的文件复制带有-ignorecrc选项(如翻译有误欢迎指正)】
Files that fail the CRC check may be copied with the -ignorecrc option.
文件CRC可以复制使用CRC选项。
例子:
- hadoop fs -get /user/hadoop/file localfile
- hadoop fs -get hdfs://nn.example.com/user/hadoop/file localfile
返回 0成功返回 1 错误
4、fsck
说明:用来检查整个文件系统的健康状况,但是要注意它不会主动恢复备份缺失的block,这个是由NameNode单独的线程异步处理的。
用法:hadoop fsck [GENERIC_OPTIONS] [-move|-delete|-openforwrite] [-files [-blocks [-locations | -racks]]]
参数选项:
-move 破损的文件移至/lost+found目录
-delete 删除破损的文件
-openforwrite 打印正在打开写操作的文件
-files 打印正在check的文件名
-blocks 打印block报告(需要和-files参数一起使用)
-locations 打印每个block的位置信息(需要和-files参数一起使用)
-racks 打印位置信息的网络拓扑图(需要和-files参数一起使用)
范例:
例1.
hadoop@ubuntu:~/hadoop-1.1.1/bin$ hadoop fsck /
Warning: $HADOOP_HOME is deprecated.
FSCK started by hadoop from /192.168.11.156 for path / at Sat Dec 29 19:33:40 PST 2012
.Status: HEALTHY
Total size: 4 B
Total dirs: 9
Total files: 1
Total blocks (validated): 1 (avg. block size 4 B)
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 1 #缺省的备份参数1
Average block replication: 1.0
Corrupt blocks: 0 #破损的block数0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 1
Number of racks: 1
FSCK ended at Sat Dec 29 19:33:40 PST 2012 in 4 milliseconds
The filesystem under path '/' is HEALTHY
hadoop@ubuntu:~/hadoop-1.1.1/bin$
5、jar
说明:运行jar文件。用户可以把他们的Map Reduce代码捆绑到jar文件中,使用这个命令执行。
用法:hadoop jar
范例:
例1.在集群上运行Map Reduce程序,以WordCount程序为例
hadoop jar /home/hadoop/hadoop-1.1.1/hadoop-examples.jar wordcount input output
描述:
hadoop jar:执行jar命令
/home/hadoop/hadoop-1.1.1/hadoop-examples.jar: WordCount所在jar
wordcount:程序主类名
input output:输入输出文件夹
6、job
说明:用于和Map Reduce作业交互和命令。
用法:hadoop job [GENERIC_OPTIONS] [-submit ] | [-status ] | [-counter ] | [-kill ] | [-events <#-of-events>] | [-history [all] ] | [-list [all]] | [-kill-task ] | [-fail-task ]
参数选项:
-submit
-status
-counter
-kill
-events
-history [all] :-history 打印作业的细节、失败及被杀死原因的细节。更多的关于一个作业的细节比如成功的任务,做过的任务尝试等信息可以通过指定[all]选项查看。
-list [all]:-list all显示所有作业。-list只显示将要完成的作业。
-kill-task
-fail-task
7、pipes
说明:运行pipes作业。
用法:hadoop pipes [-conf ] [-jobconf , , ...] [-input ] [-output ] [-jar ] [-inputformat ] [-map ] [-partitioner ] [-reduce ] [-writer ] [-program ] [-reduces ]
参数选项:
-conf
-jobconf
-input
-output
-jar
-inputformat
-map
-partitioner
-reduce
-writer
-program
-reduces
8、version
说明:打印版本信息。
用法:hadoop version
9、CLASSNAME
说明:hadoop脚本可用于调用任何类。
用法:hadoop CLASSNAME
描述:运行名字为CLASSNAME的类。
二、管理命令
hadoop集群管理员常用的命令。
1、balancer
说明:运行集群平衡工具。管理员可以简单的按Ctrl-C来停止平衡过程。
用法:hadoop balancer [-threshold ]
参数选项:
-threshold
2、daemonlog
说明:获取或设置每个守护进程的日志级别。
用法:hadoop daemonlog -getlevel
用法:hadoop daemonlog -setlevel
参数选项:
-getlevel
-setlevel
3、datanode
说明:运行一个HDFS的datanode。
用法:hadoop datanode [-rollback]
参数选项:
-rollback:将datanode回滚到前一个版本。这需要在停止datanode,分发老的hadoop版本之后使用。
4、dfsadmin
说明:运行一个HDFS的dfsadmin客户端。
用法:hadoop dfsadmin [GENERIC_OPTIONS] [-report] [-safemode enter | leave | get | wait] [-refreshNodes] [-finalizeUpgrade] [-upgradeProgress status | details | force] [-metasave filename] [-setQuota ...] [-clrQuota ...] [-help [cmd]]
参数选项:
-report:报告文件系统的基本信息和统计信息。
…
5、jobtracker
说明:运行MapReduce job Tracker节点。
用法:hadoop jobtracker
6、namenode
说明:运行namenode。
用法:hadoop namenode [-format] | [-upgrade] | [-rollback] | [-finalize] | [-importCheckpoint]
参数选项:
-format:格式化namenode。它启动namenode,格式化namenode,之后关闭namenode。
-upgrade:分发新版本的hadoop后,namenode应以upgrade选项启动。
-rollback:将namenode回滚到前一版本。这个选项要在停止集群,分发老的hadoop版本后使用。
-finalize:finalize会删除文件系统的前一状态。最近的升级会被持久化,rollback选项将再不可用,升级终结操作之后,它会停掉namenode。
-importCheckpoint 从检查点目录装载镜像并保存到当前检查点目录,检查点目录由fs.checkpoint.dir指定。
7、secondarynamenode
说明:运行HDFS的secondary namenode。
用法:hadoop secondarynamenode [-checkpoint [force]] | [-geteditsize]
参数选项:
-checkpoint [force]:如果EditLog的大小 >= fs.checkpoint.size,启动Secondary namenode的检查点过程。 如果使用了-force,将不考虑EditLog的大小。
-geteditsize:打印EditLog大小。
8、tasktracker
说明:运行MapReduce的task Tracker节点。
用法:hadoop tasktracker