多线程爬取 unsplash 图库

题图:by nasa from Instagram

我公众号文章的封面配图都在 Unsplash 上找的。因为 Unsplash 是一个完全免费的、无版权的高清图片资源网站。
所谓的「无版权」是指这个网站上的图片由创作者自愿分享出来,完全免费提供给任何人作为任何用途使用。Unsplash 的原话是「do whatever you want」,进一步说明是「你可以免费对图片进行复制、修改、分发,包括用作商业目的,无需经过允许即可使用」。
自己发现之前在寻找图片上还是挺花费时间的。先在 Unsplash 上浏览图片,当发现觉得还不错的图片就会下载下来。另外,下载图片还需要自己点击下载按钮。这确实挺花费时间。现在自己学会了网络爬虫,是时候改善下情况。
分析
Unsplash 网站采用瀑布流样式来呈现图片。首页以开始只会呈现一部分图片,当我们滑动滚动条到底部时,网页才会继续加载部分图片。这网站经常使用 Ajax 技术来加载图片。针对动态渲染网页,我会选择 Selenium 来爬取。但是,我这次为了追求高效率下载图片,势必要使用多线程。因此,只能放弃使用 Selenium,转而通过抓包方式来分析网站。
我使用浏览器的开发者工具来查看网络请求。
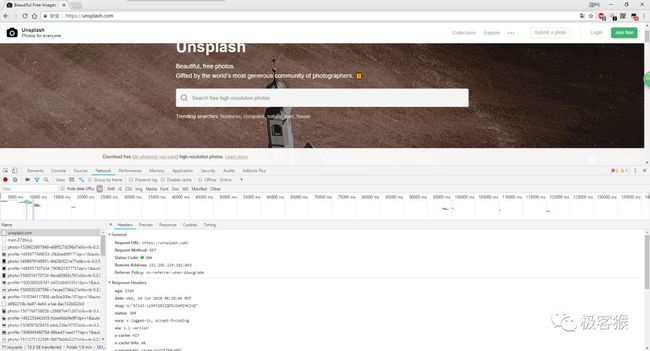
接着, 自己满怀期待查看 main.js 文件。因为名字的原因,所以自己怀疑这个 js 文件的作用是发起请求网络。自己只要在代码中搜索下 http 字样,说不定还有意外的收获。
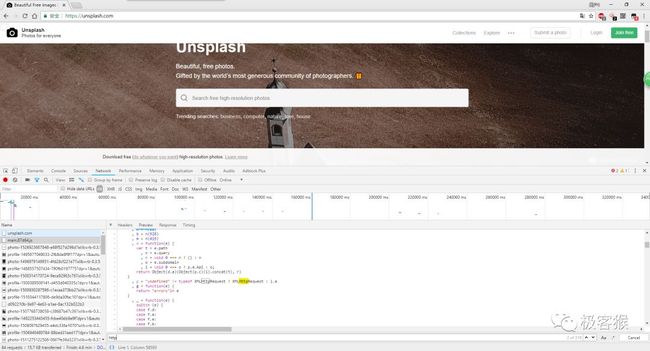
经过一番漫长的分析之后,最后发现两个很有价值的信息。
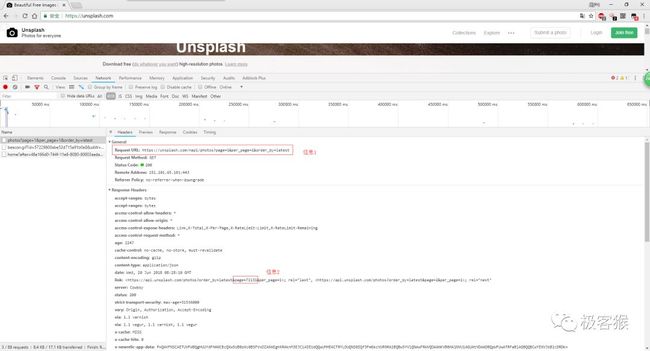
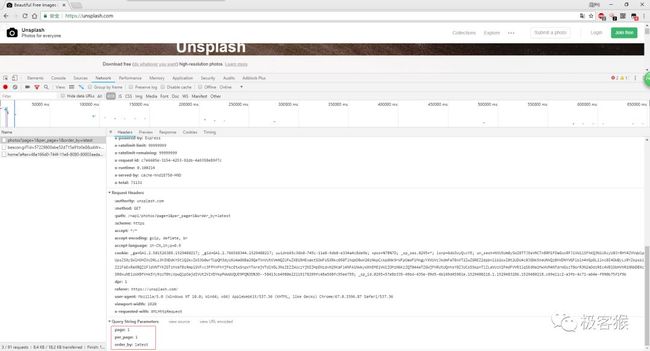
这个 url 地址十有八九是图片的请求地址。
自己使用浏览器访问这个地址,证实自己的猜想是正确的。

根据英语单词,可以推断出各个参数的意思。page 表示页数, 从前面的信息得知目前一共有 71131 个页面;per_page 表示每页拉去的图片数, order_by 表示按时间从现在到以前的顺序来拉取图片。
我自己使用 Requests 库编写一段简单的请求代码。目的是验证网站是否有反爬虫机制,结果发现没有。
爬取思路
因为多线程需要考虑线程安全的问题,所以我决定使用 Queue 队列模块来存储所有的的 url 地址。Queue 模块中提供了同步的、线程安全的队列类,其中就有 FIFO(先入先出)队列 Queue。Queue 内部实现了锁原语,帮我们实现加锁和释放锁的操作。因此,我们能够在多线程中直接使用。
最终的思路是:
代码实现
先定义一些常量, 方便后续操作。
# 使用队列保存存放图片 url 地址, 确保线程同步
url_queue = Queue()
# 线程总数
THREAD_SUM = 5
# 存储图片的位置
IMAGE_SRC = 'D://Unsplash/'
计算出所有的 url 地址, 然后存放到 url_queue 队列中。
def get_all_url():
""" 循环计算出所有的 url 地址, 存放到队列中 """
base_url = 'https://unsplash.com/napi/photos?page={}&per_page=1&order_by=latest'
page = 1
max_page = 71131
while page <= max_page:
url = base_url.format(page)
url_queue.put(url)
page += 1
print('计划下载', url_queue.qsize(), '张图片')
创建多个线程,然后逐个启动。
if __name__ == '__main__':
get_all_url()
for i in range(THREAD_SUM):
unsplash = Unsplash(i+1)
unsplash.start()
原生的 Thread 类无法满足场景的需求。我新建一个名为 Unsplash 的类,该类继承threading.Thread 来自定义线程类,接着重写 run 方法。
class Unsplash(threading.Thread):
NOT_EXIST = 0
def __init__(self, thread_id):
threading.Thread.__init__(self)
self.thread_id = thread_id
def run(self):
while not self.NOT_EXIST:
# 队列为空, 结束线程
if url_queue.empty():
NOT_EXIST = 1
break
url = url_queue.get()
self.get_data(url)
time.sleep(random.randint(3, 5))
def get_data(self, url):
""" 根据 url 获取 JSON 格式的图片数据"""
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.3964.2 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'referer': 'https://unsplash.com/',
'path': url.split('com')[1],
'authority': 'unsplash.com',
'viewport-width': '1920',
}
response = requests.get(url, headers=headers)
print('请求第[ ' + url + ' ], 状态码为 ', response.status_code)
self.get_image_url(response.text)
def get_image_url(self, response):
"""
使用 json.loads(response) 将其转化为字典类型, 以便采用 key-value 形式获取值
raw:包含Exif信息的全尺寸原图,此类图片的容量很大
full:全尺寸分辨率的图片,去除了Exif信息并且对内容进行了压缩,图片容量适中
normal:普通尺寸的图片,去除了Exif信息,并且对分辨率和内容进行了压缩,图片容量较小;
"""
image_url = json.loads(response)[0]['urls']['full']
self.save_img(image_url)
def save_img(self, image_url):
print('线程', self.thread_id, ' | 正在下载', image_url)
try:
if not os.path.exists(IMAGE_SRC):
os.mkdir(IMAGE_SRC)
filename = IMAGE_SRC + image_url.split('com')[1].split('?')[0] + '.jpg'
# 下载图片,并保存到文件夹中
urllib.request.urlretrieve(image_url, filename=filename)
except IOError as e:
print('保存图片出现异常失败', e)
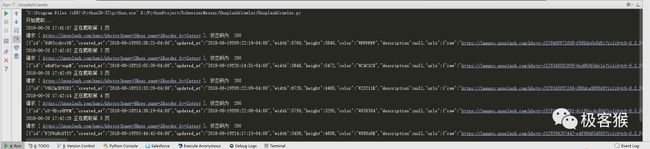
爬取结果
按照计划,执行完一次程序代码。硬盘的 D 盘目录中会有一个 Unsplash 的文件夹,里面会有 71131 张图片。我是将爬虫程序运行在云主机上,所以就只显示本地爬取的 100 多张图片。

温馨提示
点击『阅读原文』,查阅项目的源代码
推荐阅读:
Python 多进程与多线程
爬取《Five Hundred Miles》在网易云音乐的所有评论
爬取网易云音乐精彩评论
我爬取豆瓣影评,告诉你《复仇者联盟3》在讲什么?
基础知识 | 使用 Python 将数据写到 CSV 文件
爬虫实战一:爬取当当网所有 Python 书籍
爬虫实战二:爬取电影天堂的最新电影
学会运用爬虫框架 Scrapy (四) —— 高效下载图片
Python 爬虫入门
END
不积跬步,无以至千里

如果你觉得文章还不错,请大家点赞分享下。
你的肯定是我最大的鼓励和支持。