Redis基础及集群部署
Redis基础及集群部署
系统:windows10 内容:redis应用及相关概念
Redis数据类型
相关命令api
redis安装
基础命令
keys *
exists key #key是否存在
ttl key #查看剩余时间
expire key second #-1永久有效,-2失效
del key #删除key
persist key #取消过去时间
perxpire key millisecond #修改key的过期时间为毫秒
select #选择数据库
move key dbindex #将当前数据中的key转移到其他数据库
randomkey #随机返回一个key
rename key key2 #重命名key
dbsize #数据数量
type key #查看数据类型
String
- 封锁IP地址。Incrby命令
- 1、保存单个字符串或json字符串数据
- 2、二进制安全,图片文件
- 3、计数器(微博数,粉丝数)
String
setnx key value #如果key存在,不赋值,返回0,不存在则赋值,返回1 (分布式锁解决方案之一)
setex key second value #设置过期时间,ex expired
setrange key range value # 替换range位置的字符串为value
getrange key start end #获取范围之间的key,包括start和end位置的值
getset key value #获取原值赋新值value
strlen key #value长度
mset k1 v1 k2 v2 #批量写
mget k1 k2 #批量读
原子操作,加锁操作
incr key #自增
decr key #自减
incrby key #增值
decrby key #减值
Hash
- 存储用户信息[id,name,age]
- Hset(key,field,value)
- hash适合存储对象
- String存对象:反序列化消耗,内存占用
- k-v 模式不变,但v是一个键值对
hset key field value #存储对象
hget key field #获取对象值
hmset key field1 value1 field2 value2 #设置多个字段 hmget user:1 id name age
hmget key field1 field2 #获取多个字段的值
hgetall key # 获取对象所有属性值
hexists key # 对象字段个数
hkeys key # 查看所有字段名
hvals key # 查看所有字段值
hdel key field # 删除字段
hlen key # 字段个数
hsetnx key field value # 不存在则设值
hincrby key field increment # 自增
hincrbyfloat key field float # 加浮点值
hexists key field # 字段是否存在
List
- 实现最新消息的排行
- 利用List的push命令,将任务的存在集合中,用pop取出
- 可以用来模拟消息队列【秒杀案例】
// 赋值
lpush l1 a b c d e #结果e d c b a 入栈
rpush l2 1 2 3 4 5 #结果 1 2 3 4 5 队列
lpushx key val #头部插入,key不存在,插入无效
rpushx key val #尾部插入,key不存在,插入无效
// 取值
llen key #查看list长度
lindex l1 0 #查看对应下表的元素 -1代表倒数第一个,以此类推
lrang l1 0 -1 # 查看list 0开始,-1代表倒数第一个
// 删除
lpop key #头部删除, 栈顶删除
rpop key #尾部删除, 队列删除
blpop key timeout #阻塞删除,没有key则阻塞等待,timeout 时间秒
brpop key timeout
ltrim key start stop #截取数据
// 修改
lset key index value # 指定下标修改
linsert key before|after word value #在列表前后插入,指定word
// 高级命令
rpoplpush key1 key2 # key1尾部添加到key2头部
rpoplpush key1 key1 # 循环列表
Set
- 可以自动排重
- 微博中将每个人的好友存在集合(Set)中,求两个人的共同好友,取交集集合。
sadd setKey 1 1 2 2 3 3 # set去重存入,结果1 2 3
smembers setKey # 查看set内容
sismemer setKey 1 # 是否存在元素1
scard setKey # 获取元素个数
srem setKey 1 #删除元素
srandmember setKey #随机选几个元素,默认一个,不删除元素
spop setKey # 随机出栈,出完删除
smove setKey setKey2 # setKey中的值移到setKey2
// 数学集合类
sdiff set01 set02 #求set02不包含set01的元素
sinter set01 set02 #交集
sunion set01 set02 #并集
Zset
- 有序不重复集合sorter set
- 以某一个条件为权重进行排序
- 做排行榜,商品详情综合排名,筛选排名
- 按时间排序,时间作为score
- 学生成绩排序
- 权重排序,重要消息
zadd key score1 val1 score2 val2 score3 val3 score4 val4 score5 val5 # 添加元素,在set基础上,加一个score值
zrange key 0 -1 # 查看值v1 v2 v3 v4 v5
zrange key 0 -1 withscores # 查看值和分数
zrevrange key 0 -1 # 倒序查看
zrevrangebyscore key score2 score1 # 倒序查看分数范围的
zrangebyscore key score1 socre2 # 开始score 结束socre 分数范围的值 v1 v2 v3 v4
zrangebyscore key (score1 (socre2 # 加左括号,不包含
zrangebyscore key score1 socre2 limit 2 2 # 比较后的结果加limit,做截取第一个下标(从0开始),第二个个数
zrangebylex key - + # 获取所有元素val
zrem key val # 删除对应的val的元素
zremrangebyrank key index1 index #根据下标删除
zremrangebyscore key score1 score2 # 删除分数范围内的元素
zcard key # 查看元素个数
zcount key score1 score2 # 统计分数范围内元素个数
zrank key val # 取对应元素下标
zscore key val # 取对应元素分数
zrevrank key val # 倒序下标值
zincrby key score val # 增加分数
HyperLoglog
-
用来做基数统计,基数估算算法
-
数据量大的,占用空间很小,矩阵
-
统计注册的ip数
-
统计在线用户数
-
统计页面实时uv数
-
统计每日访问ip数
-
统计真实文章阅读数
-
统计用户每天搜索不同词条的个数
-
只记录数量
pfadd key 1 2 3 4 4 6 6 3 # 结果
pfcount key #返回给定的基数个数
pfmerge key3 key1 key2 #合并key1 ,key2的基数赋给key3
Jedis/Lettuce
redisTemplate
发布/订阅
-
消息通信(一般用socket,不用redis的发布订阅)
-
频道
-
实时聊天系统,群聊
-
公众号,微博,新闻
subscribe channel1 channel2... # 订阅一个或多个频道
psubscribe pattern #订阅一个或多个符合给定模式的频道
unsubscribe channel1 # 退订给定的频道
punsubscribe pattern 退订所有给定模式的频道
publish channel1 message # 发布消息
多数据库
- 分别存放测试和正式数据
- 多服务的数据存储
select index # 选择数据库
move key index # 移动到其他库
flushdb # 清空当前数据库
flushall # 清空所有数据库
事务
-
多命令按顺序依次执行
-
开启事务
-
命令入队
-
执行事务
DISCARD
:取消事务,放弃执行事务块内的所有命令
EXEC
:执行所有事务块内的命令
MULTI
:标记一个事务块的开始
UNWATCH
:取消WATCH命令对所有key的监视
WATCH key [key...]
:监视一个或多个key,如果在事务执行之前这个或这些key被其他命令所改动,那么事务将被打断
A向B转帐50元
set account:a 100
set account:a 12
multi
decrby account:a 50
incrby account:b 50
exec
错误处理
- 错误的命令不会执行,其他命令会执行,且不会回滚
multi
set aa hello
get aa
incr aa
exec
- 命令报告错误,事务会取消
multi
set bb hello
get bb
asdfasd
exec
监视事务
- 当某个账户在事务内进行操作,提交事务前,另一个线程对该账户进行操作,事务会被取消
watch a
multi
incr a
incr a
exec
案例
- 商品秒杀,14:00 秒杀100台手机(特价:半价)
key:存入100手机 编号:list
秒杀流程:
一个用户只能抢一台手机
如果抢成功:用户名存入,抢成功的手机编号,移除抢到的手机编号
持久化
- 内存的数据写到磁盘中,防止服务宕机了内存数据丢失
默认RDB
- rdbSave(生成RDB文件)/rdbLoad(从文件加载内存)
- 快照的方式
- 保存、还原数据快、适用于灾难备份
- 占内存,小内存机器不适合使用
- 快照满足条件
- save 900 1 #每900秒至少一个key发生编号,产生快照
AOF
- RDB会丢失最后一次快照后的所有修改,如果要求不丢失任何修改的话,可以采用aof持久化方式
- Append-only file
- redis会将每一个收到的写命令通过write函数追加到文件(appendonly.aof)中。当redis重启时会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。
- WRITE:根据条件,将aof_buf中的缓存写入到aof文件
- SAVE:根据条件,调用fsync或fdatasync函数,将aof文件保存到磁盘中
- 问题
- 持久化文件会越来越大
redis缓存与数据库的一致性
-
实时同步
-
异步
- 定时任务
- 异步队列
- 消息队列,生产/消费
- 消息高可靠性
- 高可用、高性能、高并发
- rabbitmq、rocketmq、kafka
- kafka消息顺序io存在硬盘中
- 中间件:解决方案
-
Canal
- 主从复制-读写分离-选举机制
- mysql内部实现机制:主表修改记录binlog(二进制日志文件),从表读取日志进行复制
-
udf
总结
穿透
- 访问一个不存在的key,缓存不起作用,请求会穿透到DB,流量大时DB会挂掉。
- key是否存在,key不存在去查询数据库,数据库数据也为空,redis没起作用
- 解决方案:先查询key是否为空(或设为null),如果为空(null)直接返回空
- 数据库插入数据时,给redis重新赋一次key
- 给key加密,如果后台不存在解密失败直接返回错误
- 布隆过滤器
击穿
- 一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增。
雪崩
- 缓存大部分失效,请求大量查询数据库,导致数据库压力,引发数据库宕机
- 缓存失效时间均匀分布
- 加锁排队、限流
- 数据预热
- 缓存失效时间均匀分布
热点key
- 热点key:某个key访问非常频繁,当key失效的时候有大量线程来构建缓存,导致负载增加,系统崩溃。
- 解决方案:
- 使用锁、单机用synchronized、lock等,分布式用分布式锁
- 缓存过期时间不设置,而是设置在key对应的value里。如果监测到存的时间超过过期时间则异步更新缓存。
- 在value设置一个比过期时间t0小的过期时间t1,当t1过期时,延长t1时间并做更新缓存操作。
- 设置标签缓存,标签缓存设置过期时间,标签缓存过期后,需异步地更新实际缓存。
加锁
- 方法加synchronized
- 双重校验
public User selectById(String id){
User user = (User)hash.get("user",id);
if(null == user){
sychronized(this){
user = (User)hash.get("user",id);
if(null == user){
user = userMapper.selectById(id);
hash.put("user",id,user);
}
}
}
return user;
}
高并发
- 垂直扩展
- 多核
- 水平扩展
- 集群
- 主从复制、读写分离
--port 6380 # 从服务器的端口号
--slaveof 127.0.0.1 6379 # 指定主服务器
redis-cli 6380 -a user
- 哨兵模式
- 监测心跳,心跳机制
- 无中心调用,3台主,3台从(区块链)
- 网络抖动
搭建集群
# linux使用
redis-cli --cluster create -a test123 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1
# windows使用,需要下载redis-trib.rb文件
ruby redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
# 自动分配槽点
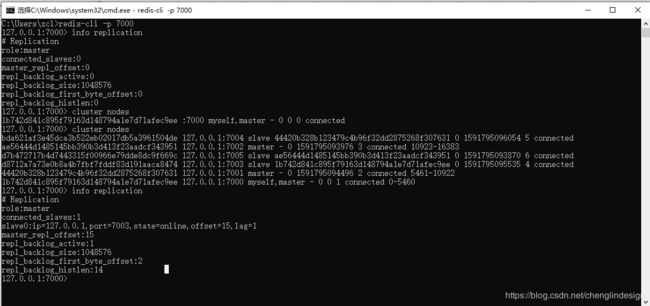
redis-cli -p 7000
info replication
cluster nodes
- 配置
port 7000
cluster-enabled yes
cluster-config-file nodes-7000.conf
cluster-node-timeout 5000
appendonly yes # 不加这条启动报You can't have keys in a DB different than DB 0 when in Cluster mode. Exitin
- 脚本启动
redis-server D:\tools\redis_cluster\7000\redis.windows.conf
redis-cli -c -h 127.0.0.1 -p 7000 shutdown # shutdown关闭集群 -c 集群模式 -a 服务端密码