UON:《Detecting Unexpected Obstacles for Self-Driving Cars...》论文阅读与总结
UON : Detecting Unexpected Obstacles for Self-Driving Cars: Fusing Deep Learning and Geometric Modeling
1. 总览
这篇文章是发表在Intelligent Vehicles Symposium (IV), 2017 IEEE上的一篇文章,也是我看的上一篇文章《LostAndFound》相同的研究人员的一篇学术文章,在障碍物检测上得到了很好的效果,比他们前期的工作提升了50%的效果,并在50m的范围内可以达到90%的精确度。
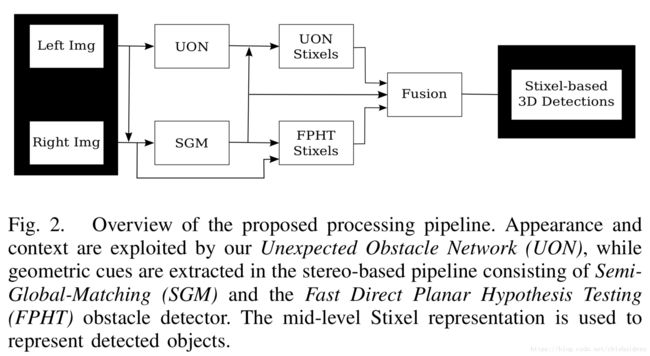
在本文中作者利用在《LostAndFound》中提出的FPHT方法利用多视角几何信息提取障碍物Stixel,同时利用基于GoogleNet的UON(Unexpected Obstacles Networks)进行场景的语义分割,分割出Obstacle,freespace和background三种区域,并将障碍物区域转化为Stixel表示。接着作者利用贝叶斯框架,融合这两种特征的多种置信信息,判断最终障碍物的位置。
2. 相关工作
作者介绍了多篇文章的相关工作,这还是比较重要的。
首先是基于传统几何视觉的方法:
- Z. Zhang等人在1997年发表在TPAMI上的工作,将自由空间或地面建模为单个平面表面,并通过其地面高度来表征障碍物
- H. S. Sawhney等人在1994年发表在CVPR上的工作中,参考平面的几何偏差是从图像数据中直接估算出来的。
- 或者是通过多尺度上的v-视差直方图的模式提取来估算,如S. Kramm在2012年发表在IV上的文章。
- 为了应对与平面世界假设的偏差,有的方法引入了更复杂的地面轮廓模型,例如《Real Time Obstacle Detection in Stereovision on Non Flat Road Geometry Through ”V-
disparity” Representation》和《B-Spline Modeling of Road Surfaces with an Application to Free Space Estimation》 - 近期的一篇文章《Real-Time Obstacle Detection using Stereo Vision for Autonomous Ground Vehicles: A Survey》对几种基于双目视觉的障碍物检测方法做了介绍,其中介绍了几种很有效的方法:
- Stixels,该方法被作为本文的对比方法。
- Digital Elevation Maps
- geometric point clusters
上面的方法都需要使用双目视差图。接下来作者详细介绍了三篇文章的工作,我感觉这些工作非常重要。
- 首先是本文基于《LostAndFound》中的FPHT方法,在文章《High-Performance Long Range Obstacle Detection Using Stereo Vision》表示了FPHT方法在远距离物体的检测上有很高的精确度。但是这个方法需要知道图中障碍物的最小像素高度。
- 然后作者介绍了一篇基于RBM进行道路检测的文章,这篇文章在我之前的博文中讲解过,通过RBM神经网络,恢复出地面的patch,然后用恢复地面的图和原图相减,得到最终的障碍物图像,想法非常clever。但是这篇文章貌似没有提供代码。
- 《Learning Long-Range Vision for Autonomous Off-Road Driving》提出了一种方法,将深层次网络提取的特征和实时的在线分类器结合起来,以预测越野环境中的可前进性。 这项工作使用近距离立体视觉系统来自动收集地面真实数据,以便使在线分类器适应移动机器人前方自由空间的变化。
- 《Free-Space Detection with Self-Supervised and Online Trained Fully Convolutional Networks》文中使用半监督学习且在线学习的FCN网络去对场景进行分割,对道路进行检测。
本文的目标在于提供深入的基于学习的识别系统,能够在测试时检测到之前未训练的类。
3. 本文的方法
作者使用了两个方法,分别使用几何特征和外观特征得到障碍物的几何概率和语义信息,然后将这两个channel融合进基于概率的贝叶斯框架,得到最终的障碍物。
1. UON基于外观的语义检测-障碍物网络
这是两个障碍物检测方法中的第一个,对单独的一张图进行semantic labeling。通过深度学习,利用视觉外观信息以及上下文,为一张图片中的每个像素分配他们的类别。作者将一张图片上的像素分成三类,道路,障碍物和背景。
背景是指与本文任务目标不相关的物体区域,比方说建筑物和天空,在这个类别中也包含所有城市场景下的通用障碍物,比如汽车和行人,那么这些其实都可以用一些通用的感知算法来进行识别。
A. 网络的改造与训练
依照之前那篇FCN的文章,作者将GoogleNet最后的全连接层替换掉了,并且加入了跳跃层和反卷积层,且加入了二元权重过滤器以此适配输出图像的大小。最终的FCN会输出一张概率图(probability map)或者称为热力图(heat map),在这张图中会给每个像素点赋予一个类别,即semantic labeling。这张图是通过softmax标准化层和argmax层得到的。
作者使用两个数据集对这个FCN网络进行训练,Lost And Found 和 CityScape,这两个数据集,一个是具有路上的小型障碍物,一个是城市场景下的各种复杂道路情况,他们之间互有补偿。为了补偿所描述的数据集组合中每个类别的像素的不平衡,作者在softmax分类器的交叉熵损失内包括道路上的意外障碍类别的加权因子。 这对于实现真实检测与误报之间的理想平衡至关重要。
B.UON-Stixel生成
UON的Stixel使用FCN网络的输出生成,所以需要将FCN网络的输出和Stixel的宽度对齐,然后计算Stixel一行内每个类别的中位数。对齐的详细做法主要是,将argmax输出的图像水平降采样一个因子,使其宽度和预定义的Stixel宽度相同。如果在argmax图像中出现障碍物的label,则生成一个Stixel。 Stixel垂直方向扩展,直到label在列内发生变化。 以这种方式,即使是在很远的距离处(例如,图像中只有几个像素高度)的小障碍物,也可以考虑Stixels。 为了给每个生成的Stixel分配一个3D位置,作者实现了一个实时的半全局匹配(SGM)的视差图输出中平均了潜在的差异。
2.基于几何的方法检测障碍物:FPHT
FPHT是本文系统的第二个部分,它是由作者在2016年的IROS上发表的Lost And Found一文中实现的基于双目深度图的障碍物检测方法。该方法是基于两个相机拍摄的双目视察图像,用假设检验的方式,将道路空间作为零假设,障碍物区域作为备择假设,利用三维空间中局部三维平面模型的方向的约束,检测空间中每个局部的平面。通过优化视差空间中的假设模型参数来制定和解广义似然比检验,最后通过确定合适的阈值,确定障碍点在3维空间中的位置。
作者在使用FPHT的时候,就直接将上一篇文章的结果拿过来用了,没有做任何的修改。
3.外观与几何信息融合进行障碍物检测
前两个部分使用UON提取出UON-Stixel并使用FPHT提取出FPHT-Stixel,那么这一步就需要将两者进行结合并检测障碍物了。
A. 与或融合
作者用简单的“与”操作符和“或”操作符作为参照,来估计最优化的误检率和检测率。与操作符就是说两个Stixel都在此处表示了障碍物,或操作符就是说,两个Stixel中有一个在此处表示了障碍物。对应的Stixel至少有50%的重叠才会被确定。在这里作者没有去做更加精细化的Stixel的处理。
B. 概率融合
本文的多信息融合基于概率框架,作者用贝叶斯框架来估计障碍物的Stixel。(作者将Stixel的存在概率称为置信度)置信度的计算从或操作符的Stixel列表开始,共计算三种信息的置信度。
- UON的置信度
- FPHT的置信度
- 视差图的置信度
- 其实FPHT图就是由视差图计算得到的,但是为什么还要单独把视差图拿出来做置信度的计算呢,作者提出,因为视差图只是作为一个粗糙的初始信息来进行FPHT的假设计算。言下之意就是说,实际上视差图还有很多信息还未使用,比方说视差图对于地面区域的检测非常可靠,并且计算速度快。
通过下面的相乘公式,这三种置信度融合成该Stixel的置信度
- p(SUON) p ( S U O N ) 是UON的置信度
- p(SFPHT) p ( S F P H T ) 是FPHT的置信度
- p(D) p ( D ) 是视差图的置信度
- N N 是标准化项
这三个置信度被适当的归一化,得到了一个有意义的概率,其中N的计算公式如下:
其中经验值 pUOpr=0.5 p U O p r = 0.5 ,但是在Lost And Found数据集上,统计数据表明 pUOpr<0.01 p U O p r < 0.01 。
接下来分别对这三种置信度的计算进行讲解。
1) UON-Stixel置信度:
SUON=∑i∈S(pi(障碍物)+pi(背景))hS S U O N = ∑ i ∈ S ( p i ( 障 碍 物 ) + p i ( 背 景 ) ) h S
其中 hS h S 是Stixel的高度, i i 是像素的下标, p p 是概率
求得的是每个像素属于非道路区域的概率之和,作者认为不能直接使用障碍物的概率,因为在这个数据集中有很多未被标记为障碍物的非道路区域也是需要检测出来的,所以结合了障碍物和背景的像素概率。
2) FPHT-Stixel置信度(这一段作者描述的不是特别清晰):
p(SFPHT)=11+e(lavg,FPHT) p ( S F P H T ) = 1 1 + e ( l a v g , F P H T )
其中 lavg,FPHT l a v g , F P H T 表示可用似然比,对所有对Stixel有贡献的点假设进行平均,然后转变为置信度。
对于小Stixel来说,它使得同样具有很多障碍点的大小Stixels产生相似的概率。 为了结合来自FPHT聚类步骤的先前信息,作者收集了真假正向Stixels的障碍假设的高度和数量统计。 比较Lost and Found数据集上产生的概率密度函数,作者观察到重叠低于50%,即合理的分离,并且以每个Stixel 10个障碍点和10cm高度作为检测成功的Stixel比误检Stixel获得更高概率的转折点。这个先验值乘以 p(SFPHT) p ( S F P H T ) ,用类似于《A multi-cue approach for stereo-based object confidence estimation》的Sigmoid函数建模。
3) 视差图置信度:
视差图置信度的计算遵循了假设检验的方法。因为同一个障碍物的平面距离相机的距离都是相同的,所以不会像道路平面那样,每个点距离相机平面的距离都不同,在这里我们可以把视差值当做是深度图,障碍物平面上每个点的视差值基本是相同的,但是道路上的每个点的视差值均不相同,所以障碍物平面上视差值的方差较小,而道路上的则较大。作者比较障碍物假设的能量与道路假设的能量,在这里能量指的是同一个Stixel中其他视差值到平均视差值的偏差,其实这就是类似于方差。(作者没有介绍的特别清楚,这里是我自己的理解)两种能量分别用下面的公式进行表示:
- eo,ef e o , e f 表示的分别是障碍物和道路的能量
- di d i 是Stixel S的视差值
- rctr r c t r 是某一Stixel的中心行
- r r 是 di d i 的行下标
- Δd=BH Δ d = B H 是从基线B和相机到地面高度H计算的道路的预期视差倾斜度。
然后用下面的公式求出视差置信度
在这里视差方差被假定为1一个像素,常量视差的patch被赋予高置信度,而道路上的patch则被赋予了低置信度。
4) 信息融合
最终通过对融合的Stixel置信度划分阈值来确定障碍物的位置。
如果UON-Stixel不存在于考虑到的位置,就根据上文提到的 SUON S U O N 的求解方式求解UON的置信度,因为这个信息最好的反映了障碍物是否存在,也就是说作者认为UON的输出值最为准确。
如果不存在FPHT-Stixel,那么返回去求 p(FPHT)=0.5 p ( F P H T ) = 0.5
信息融合的主要框架写在下面了:
