apache atlas 2.0 详细安装手册
1.1 atlas编译打包
l 首先,在官网下载源码包
http://atlas.apache.org/
l 上传到linux,解压
[root@h2 ~]# tar -zxf apache-atlas-2.0.0-sources.tar.gz -C /opt/app/
l [可选]步骤:为maven配置添加国内下载镜像
vi $M2_HOME/conf/settings.xml
alimaven
aliyun maven
http://maven.aliyun.com/nexus/content/groups/public/
central
l [可选]步骤:修改atlas源码工程的pom.xml,将hbase zookeeper hive等依赖的版本修改成自己环境中一致的版本
父工程pom文件
3.4.14
2.2.2
7.7.2
distro工程pom****文件
<hbase.tar>http://mirrors.tuna.tsinghua.edu.cn/apache/hbase/${hbase.version}/hbase-${hbase.version}-bin.tar.gz</hbase.tar>
<solr.tar>http://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/${solr.version}/solr-${solr.version}.tgz</solr.tar>

l 执行maven编译打包
注意,atlas可以使用内嵌的hbase-solr作为底层索引存储和搜索组件,也可以使用外置的hbase和solr
如果要使用内嵌的hbase-solr,则使用如下命令进行编译打包
cd /opt/atlas2.0
export MAVEN_OPTS="-Xms2g -Xmx2g"
mvn clean -DskipTests package -Pdist,embedded-hbase-solr
视网络速度,耐心等待,并且可能要反复重试几次,最好是能开一个速度不错的
编译完成之后,会产生打包结果,所在位置是:源码目录中的新出现的distro/target目录
1.2 atlas安装配置
1.2.1 安装步骤
1.2.1.1 安装zookeeper(内嵌版不需要安装)
1.2.1.2 安装kafka(内嵌版不需要安装)
1.2.1.3 安装hbase(内嵌版不需要安装)
1.2.1.4 安装solr(内嵌版不需要安装)
1.2.1.5 配置及启动atlas
- 挪出或上传atlas编译好之后的安装包
mv distro/target/apache-atlas-2.0.0/ /opt/app/
- 修改配置文件
vi atlas-env.sh
export JAVA_HOME=/opt/app/jdk1.8.0_191/
export MANAGE_LOCAL_HBASE=true (如果要使用外部的zk和hbase,则改为false)
export MANAGE_LOCAL_SOLR=true (如果要是用外部的solr,则改为false)
vi atlas-application.properties
# Hbase地址(对应的zk地址)配置(自带hbase会根据此端口启动一个zk实例)
atlas.graph.storage.hostname=localhost:2181 # 如果使用外部hbase,则填写外部zookeeper地址
# Solr地址配置
atlas.graph.index.search.solr.http-urls=http://localhost:8984/solr(solr服务地址)
# Kafka相关配置
atlas.notification.embedded=true # 如果要使用外部的kafka,则改为false
# 内嵌kafka会根据此端口启动一个zk实例
atlas.kafka.zookeeper.connect=localhost:9026 # 如果使用外部kafka,则填写外部zookeeper地址
atlas.kafka.bootstrap.servers=localhost:9027 # 如果使用外部kafka,则填写外部broker server地址
- 手动启动hbase
# 进入atlas自带的hbase目录
cd $ATLAS_HOME/hbase
bin/start-hbase.sh
- 手动启动solr,为solr创建初始化index库
# 进入atlas自带的solr目录
cd $ATLAS_HOME/solr
# 启动solr
bin/solr start -c -z localhost:2181 -p 8984 -force #启动solr
# 创建初始化collections
bin/solr create -c vertex_index -shards 1 -replicationFactor 1 -force
bin/solr create -c edge_index -shards 1 -replicationFactor 1 -force
bin/solr create -c fulltext_index -shards 1 -replicationFactor 1 -force
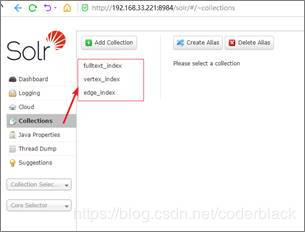
然后打开浏览器访问solr的web服务如下,则solr启动成功
- 启动atlas
cd /opt/app/apache-atlas-2.0.0/
bin/atlas_start.py
- 检查启动结果
启动后,相关服务进程如下:

监听端口如下:
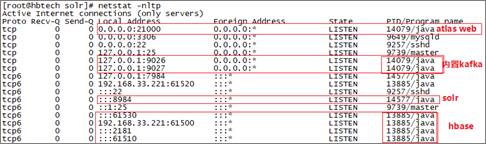
如果有上述进程和所监听端口,则说明atlas安装启动成功
可以打开atlas的web界面

以后再启动atlas,不需要再手动启动hbase和solr了
直接执行atlas启动脚本即可
踩坑后记:
内嵌kafka-hbase-solr安装方式下,kafka使用了它内置的zookeeper,占用端口9026;
hbase也启动了一个zookeeper,占用端口2181;
所以在使用自带hbase和solr的场景中,切不可把kafka和hbase的zookeeper配置成相同的端口:2181
1.2.2 hive-hook配置
配置了hive的钩子后,在hive中做任何操作,都会被钩子所感应到,并生成相应的事件发往atlas所订阅的kafka,再由atlas进行元数据生成和存储管理;
修改hive-env.sh
export HIVE_AUX_JARS_PATH=/opt/app/apache-atlas-2.0.0/hook/hive
修改hive-site.xml
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
同步配置修改
拷贝atlas配置文件atlas-application.properties到hive配置目录
添加两行配置:
atlas.hook.hive.synchronous=true # [可选]
atlas.rest.address=http://localhost:21000 # [atlas服务所在地址]
1.2.3 hook同步测试
启动hive,创建一个库
hive> create database atlasdemo;
OK
Time taken: 0.267 seconds
在atlas上搜索刚刚创建的库
完美!atlas部署成功
1.2.4 批量导入测试
在atlas安装之前,hive中已存在的表,钩子是不会自动生成相关元数据的;
可以通过atlas的一个工具,来对已存在的hive库或表进行元数据导入;
Usage 1: <atlas package>/hook-bin/import-hive.sh
Usage 2: <atlas package>/hook-bin/import-hive.sh [-d <database regex> OR --database <database regex>] [-t <table regex> OR --table <table regex>]
Usage 3: <atlas package>/hook-bin/import-hive.sh [-f <filename>]
