知识图谱学习与实践(7)——网页数据抽取(包装器的使用)
互联网中蕴含着大量的数据资源,这些数据存在于html的代码之中,如何从浩瀚的代码中提取有效的数据,针对不同的情况,可以采用多种方法来实现网页数据的提取。
1 手工方法
网页呈现数据的方式,一般都是按照导航页、列表页、详情页进行设计,这就会使得数据展示存在一定的规律,我们找出这种规律,就可以制定相应的规则,来获取数据。比如。京东商城中笔记本的列表页面。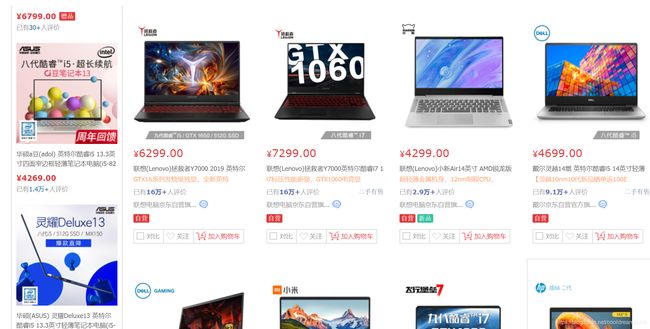
我们想要在该页面提取笔记本的价格数据,则需要对页面的html代码进行分析,获取其html代码,如下所示:

1.1 利用XPath语言
利用其html代码进行数据提取,可以采用XPath语言,XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。XPath被开发者采用来当作小型查询语言。
价格信息的Xpath代码为:
//*[@id=”plist”]/ul/li[5]/div/div[3]/strong
1.2 利用CSS选择器
与之类似的,也可以采用CSS选择器来进行定位笔记本价格,把html代码看作是一个dom树,按照树的层次结构,利用CSS选择器来一层层的定位到价格。该笔记本价格信息的CSS选择器的表达式为:
#plist>ul>li:nth-child(5)>div>div.p-price>strong
2包装器归纳
包装器就是将数据从网页中抽取出来,并将数据还原为结构化数据。包装器归纳是基于有监督学习的,它从标注好的训练样例集合中学习数据抽取规则,用于从其它相同标记或相同网页模板中抽取目标数据。
包装器归纳主要包括网页清洗、网页标注、包装器空间生成、包装器评估、包装器归纳结果等步骤。
2.1 网页清洗
网页清洗主要解决网页代码不规范的问题,比如网页中的标签没有闭合,个别标签使用不规范等,网页结构代码不严谨,就会导致在抽取过程中的噪声,使用一些工具比如Tidy,对网页进行规范化处理,可以在后期的抽取过程中减少噪声的影响。
2.2 网页标注
网页标注就是在网页上标注所需要抽取的数据,标注的过程可以是在需要抽取的数据位置上打上特殊的标签,表示这个数据是需要抽取的。比如,我们前面抽取的笔记本的价格数据,就可以在价格标签上打上特殊符号,将价格信息标记为抽取数据。
2.3 包装器空间的生成
对标注的数据生成XPath集合空间,对生成的集合进行归纳,形成若干个子集。归纳的规则是在子集中的XPath能够覆盖多个标注的数据项,具有一定的泛化能力。
2.4 包装器评估
对包装器进行评估,需要采用一定的标准,主要有两个标准,准确率和召回率。
准确率。将筛选出来的包装器对原先训练的网页进行标注,统计与人工标注的相同项的数量,除以当前标注的总数量。准确率越高评分越高。
召回率。将筛选出来的包装器对原先训练的网页进行标注,统计与人工标注的相同项的数量,除以人工标注的总数量。召回率越高评分越高。
经过前面一系列的步骤之后,得到包装器归纳结果,也就是笔记本最后搜索页面价格信息的XPath路径。
2.5 包装器归纳的简单举例
假如我们的标注信息,同时标注了n1,n2。它们的XPath分别是:
n1的XPath:/html[1]/body[1]/table[1]/tbody[1]/tr[2]/td[1]
n2的XPath:/html[1]/body[1]/table[1]/tbody[1]/tr[3]/td[1]
将其归纳到一个集合,然后泛化后得到的XPath可能有两个:
A: /html[1]/body[1]/table[1]/tbody[1]/tr[3]/td[1];B: //*/td
进行包装器评估:
准确率:包装器A的准确率高于包装器B,则A优于B
召回率:包装器A的召回率和包装器B的召回率一样,则A等于B
综上两个标准比较,选择包装器A。
3 自动抽取
首先来说,网站的数据自动抽取是可行的,因为网站中的数据通常是用很少的一些模板来编码的,通过挖掘多个数据记录中的重复模式来寻找这些模板是可能。其次,自动抽取也能够克服手工方法和包装器归纳的缺陷。手工方法,仅适用于那些较简单网站,工作量不大的情况。有监督的包装器则维护开销会很大,比如网站改变了以后的模板,之前生成的包装器就需要相应的进行修改,才能使用。
网页数据自动抽取的流程如下所示:

对于需要抽取数据的网页,需要进行预处理,也就是网页清洗工作,规范网页代码结构和标签的使用,然后对网页进行聚类处理,通过一定的聚类算法,将特征相近的网页归为一组,然后,根据不同组的聚类网页,训练生成相应的包装器模板,使得每组相似的网页获得一个包装器模板,分别使用不同的包装器模板,对相应的网页进行信息抽取,获取网页中的目标数据,最后,将得到的数据保存到数据库中。
网页信息自动抽取的一个代表就是RoadRunner,它是自动抽取网页数据的包装器,通过比较同类网页的两个样本页面,然后分析两个页面的相似性和不同性,归纳出一个正则文法,然后根据正则文法生成一个网页所包含的数据模式,最后抽取网页的数据。
4 三类网页数据抽取方法的比较
| 手工方法 |
包装器归纳 |
自动抽取 |
|
| 优点 |
1 对于任何一个网页都是通用的,简单快捷; 2 能抽取到用户感兴趣的数据。 |
1 需要人工标注训练集; 2 能抽取到用户高兴取得数据; 3 可以运用到规模不大网站的信息抽取。 |
1 无监督的方法,无需人工进行数据的标注; 2 可以运用到大规模网站的信息抽取。 |
| 缺点 |
1 需要对网页数据进行标注,耗费大量的人力 2 维护成本高; 3 无法处理大量站点的情况。 |
1 可维护性比较差; 2 需要投入大量的人力去做标注。 |
1需要相似的网页作为输入; 2 抽取的内容可能无法达到预期,会有一些无关信息。 |
5 结语
网页信息抽取除了使用包装器的方法,目前,使用爬虫技术对网页信息进行爬取也很普遍,这些技术并不是单一的一个技术,都有很多技术点组成,存在着一定的交叉。在实际的使用中,大家可以根据具体的情况,采用相应的技术,或者是多项技术的融合,来达到获取网页信息数据的目的。
本文主要参考王昊奋老师的知识图谱讲座中,关于信息抽取和发掘部分内容进行的整理。