Python算法总结(三)决策树分类(附手写python实现代码)
(决策树既可以做分类也可以做回归,本篇侧重决策树分类)
一、算法类型
有监督的分类算法
二、算法原理
决策树本质上是一种图结构,由根节点、内部节点、叶节点组成。根节点&内部节点是决定性特征feature,用于分支决策;叶节点用于分类决策。决策树天生过拟合,为提高模型的精度,减少模型的复杂度,往往需要剪枝处理。
算法要解决三个核心问题,如何分支?如何剪枝?如何给出类别判定?为回答核心问题,算法给出三个核心策略,一是分支策略,二是剪枝策略,三是分类策略。
关于分支策略的几个重要指标
- 信息量(不纯度)衡量方法一:Entropy

注:ID3算法、C4.5算法用该度量指标。 - 信息量(不纯度)衡量方法二:Gini

注:CART算法用该度量指标。 - I(child) 子节点总不纯度

- 分支的特征选择策略一:Information Gain 信息增益
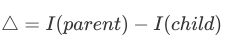
选取IG值最大的特征进行分支
注:ID3算法用该度量指标。 - Information Value 分支度

- 分支的特征选择策略二:Gain Ratio 增益率

选取GR值最大的特征进行分支
注:C4.5算法、CART算法用该度量指标。
三、算法演进(ID3 vs C4.5 vs CART)
ID3算法的局限性:
1、不能处理连续型变量
2、分支度越高的离散变量往往子节点的总信息熵会更小
3、对缺失值敏感,需提前对处理缺失值问题
4、没有剪枝设置,容易过拟合
C4.5算法的优势:
1、连续型变量特征的处理。(该方法辅助用于连续型变量分箱)
2、改用Gain Ratio作为分支策略的指标
3、提出了剪枝策略
CART算法说明:
1、CART算法构建决策树的流程与C4.5算法一致
2、CART算法构建的决策树是二元分类回归树
3、CART算法的减枝需用验证集配合进行
四、算法特点
- 非参数方法
不要求任何先验假设,不假定类和其他属性服从一定的概率分布 - 执行效率高
决策树是一种空间搜索方法,也快速建立模型,并快速对未知样本分类 - 异常值忍耐度高
异常值在剪枝过程中被裁剪,对建模基本没有影响 - 模型入口极宽
模型可同时处理离散型变量和连续型变量,且不需要对异常值进行数据清洗 - 可解释性强
可输出特征的重要性,在实际工作中有重要指导意义 - 集成性强
可集成为随机森林,解决系统性问题
五、算法流程
构建决策树的流程
第一步:准备已处理好的已知样本集Data(N个样本,M个特征,1列标签);
第二步:计算Data的总信息量,总样本集是父节点;(注:父节点与子节点是相对概念,不是绝对概念)
第三步:计算每个特征的总信息量,进而计算每个特征的信息增益;
第四步:选取信息增益量最大的特征进行分支,分支后的sub_Data子样本集是子节点(至少2个)。若子样本集的信息量为零,则停止分支,该节点即为叶节点。若子样本集的信息量不为零,则可继续分支。分支参考第二、三、四步,逐步迭代,最终构建一颗决策树。
剪枝的流程
(遗留问题:如何实现剪枝?)
预测新样本new-sample标签的流程
(遗留问题:如何预测新样本的标签?)
六、手写C4.5算法代码
-暂不涉及剪枝策略
-暂不涉及连续型特征处理
-暂不涉及新样本的标签预测
def i_entropy(dataset):
'''
函数功能:
计算数据集的信息量(不纯度)
参数说明:
dataset:带有标签的数据集,最后一列是标签,df格式或array格式
return:
entropy:用entropy方法计算数据集的信息量
'''
N,M=dataset.shape
target_names_counts=dataset.iloc[:,-1].value_counts() #计算数据集标签的分布
p=target_names_counts / N
entropy=(-p*np.log2(p)).sum() #计算信息熵
return entropy
def i_gini(dataset):
'''
函数功能:
计算数据集的信息量(不纯度)
参数说明:
dataset:带有标签的数据集,最后一列是标签,df格式或array格式
return:
gini:用gini方法计算数据集的信息量
'''
N,M=dataset.shape
target_names_counts=dataset.iloc[:,-1].value_counts() #计算数据集标签的分布
p=target_names_counts / N
gini=1-np.power(p,2).sum() #计算gini系数
return gini
def information_value(dataset,f=0):
'''
函数功能:
计算f列特征的分支度
参数说明:
dataset:带有标签的数据集,最后一列是标签,df格式
f:整数,f要小于M
return:
infor_value:分支度
'''
N,M=dataset.shape
#feature_f_index=dataset.iloc[:,f].value_counts().index #第f列特征的类别
feature_f_counts=dataset.iloc[:,f].value_counts() #第f列特征的类别分布
p=feature_f_counts / N
infor_value=(-p*np.log2(p)).sum() #计算分支度
return infor_value
def node_split(dataset):
'''
函数功能:实现分支,生成子节点
参数说明:
dataset:带有标签的数据集,最后一列是标签,df格式
return:
gr:增益率。输出每个特征gain ratio,保存在列表中。此处采用entropy计算信息量
nd:子节点的数据集
'''
N,M=dataset.shape
#计算数据集每个特征的增益率gain ratio
gr=np.array([])
for m in range(M-1):
#获取第m特征的分支数据子集,并计算每个子节点的信息熵
sub_m_dataset=[] #存放数据子集
m_entropy=[] #存放数据子集的信息熵
feature_m_category=dataset.iloc[:,m].value_counts().index #第m列特征的类别
for j in feature_m_category:
sub_m_dataset.append(dataset[dataset.iloc[:,m]==j])
for sub_dataset in sub_m_dataset:
m_entropy.append(i_entropy(sub_dataset))
#计算每个特征的总信息量,进而计算每个特征的信息增益
feature_m_counts=dataset.iloc[:,m].value_counts() #第m列特征的类别分布
p=feature_m_counts / N
m_entropy=np.array(m_entropy)
p=np.array(p)
all_m_entropy=np.sum(m_entropy*p)
infor_gain=i_entropy(dataset)-all_m_entropy
infor_value_m=information_value(dataset,f=m)
#计算增益率gr
gr=np.append(gr,infor_gain/infor_value_m)
#生成子节点数据集,由元素为数据子集组成的列表
nd=[] #用于存放子节点的数据集
feature_index=np.where(gr==gr.max())[0][0] #分支的特征索引
feature_category=dataset.iloc[:,feature_index].value_counts().index
for j in feature_category:
nd.append(dataset[dataset.iloc[:,feature_index]==j])
for z in nd:
del z[z.columns[feature_index]]
return gr,nd
def treegrowth(dataset):
'''
函数功能:生产决策树
return:
leaf_node:各叶节点的数据子集
'''
N,M=dataset.shape
leaf_node=[dataset] #初始化,最终将叶节点的数据子集保存在列表中
condition=True
while condition:
len_a=len(leaf_node)
for i in range(len_a):
if leaf_node[i].shape[1]>1: #如果有特征(除标签),则分支
gr,nd=node_split(leaf_node[i])
if gr.min()>0: #说明该数据集是不纯的,则分支是有效的。否则,上两行代码的分支是无效的。
del(leaf_node[i])
leaf_node.extend(nd) #删除父节点数据集,保存子节点数据集
len_b=len(leaf_node)
condition=not (len_a==len_b) #如果为false,说明leaf_node所有数据集都不可再分支
return leaf_node
七、Python调包实现
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import DecisionTreeRegressor
八、参数调优
1、网格搜索
2、用grahpiz画决策树
九、附调用手写函数




十、决策树回归
参考视频:https://www.bilibili.com/video/BV1ug4y1z7VG?from=search&seid=15400236844706130643
决策树回归,与决策树分类相似,差异点在于:
1、信息量(不纯度)衡量指标,不用entropy或给i你,改为用SSE
2、分支的特征选择衡量指标,不用information gain,改为用SSE gain,同样地,选取SSE gain最大的特征进行分支
3、取叶子节点决策空间的标签均值作为预测值