Python爬取的微信好友信息里我看到了自律 | CSDN博文精选

作者 | 吴小鹏
来源 | 数据札记倌(ID:Data_Groom)
"stay hungry, stay foolish"
"不舍爱与自由"
"自律"

爬取大家的签名后发现大家对生活都是积极向上的,希望每个人都能成为
更好的自己!
沉迷于造轮子。。。
无法自拔
简述
微信是我们每天都会使用的社交工具,不同的人群会有不一样的朋友圈。
可能是微信不到百人的彭磊
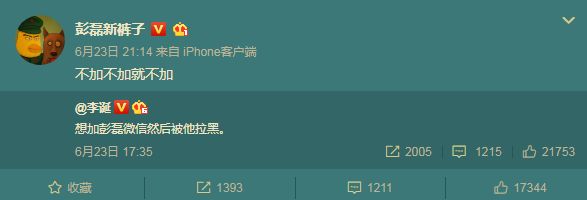
就是这个小眼睛男人
也可能是直逼好友上限的大佬

吓得我赶紧看了一下我的好友列表,迅速拉到最底端,算了一下还有四千多个位置。
没有体验过这种优秀的烦恼,所以我去搜了一下微信好友上限是一种什么体验:
大概是这样的吧!

或者是这样的?

接下来我会使用「itchat」(开源的微信个人接口)来获取一些公开的好友信息,使用itchat.get_friends(),我们可以获取微信好友头像、性别、省份、城市、年龄等具体信息。
爬取这些信息后做一些统计分布的分析。
好友头像
我们先拉取好友头像试一下,「itchat」里的get_head_img可以获取每个好友的头像:
def headImg():
itchat.login()
friends = itchat.get_friends(update= True)
# itchat.get_head_img() 获取到头像二进制,并写入文件,保存每张头像
for count, f in enumerate(friends):
# 根据userName获取头像
img = itchat.get_head_img(userName=f[ "UserName"])
imgFile = open( "photo/" + str(count) + ".jpg", "wb")
imgFile.write(img)
imgFile.close()
itchat.login()
friends = itchat.get_friends(update= True)
# itchat.get_head_img() 获取到头像二进制,并写入文件,保存每张头像
for count, f in enumerate(friends):
# 根据userName获取头像
img = itchat.get_head_img(userName=f[ "UserName"])
imgFile = open( "photo/" + str(count) + ".jpg", "wb")
imgFile.write(img)
imgFile.close()
photo文件夹
用于保存头像图片,遍历好友列表,根据下标命名头像,到这里可以看到文件夹里已经保存了所有好友的头像。
头像信息比较隐私,就不公布啦~
性别分布
当我们使用「itchat」的get_friends()函数可以获取很多好友信息,包括性别,所以这里只需要将获取到的好友性别信息提取出来制图就可以:
def analysisSex():
itchat.login()
friends = itchat.get_friends()
sex_count = dict()
for f in friends:
if f[ "Sex"] == 1: # man
sex_count[ "man"] = sex_count.get( "man", 0) + 1
elif f[ "Sex"] == 2: # women
sex_count[ "women"] = sex_count.get( "women", 0) + 1
else: # unknown
sex_count[ "unknown"] = sex_count.get( "unknown", 0) + 1
# 柱状图展示
for i, key in enumerate(sex_count):
plt.bar(key, sex_count[key])
plt.savefig( "analysisSex.png") #保存图片
plt.ion()
plt.close()
itchat.login()
friends = itchat.get_friends()
sex_count = dict()
for f in friends:
if f[ "Sex"] == 1: # man
sex_count[ "man"] = sex_count.get( "man", 0) + 1
elif f[ "Sex"] == 2: # women
sex_count[ "women"] = sex_count.get( "women", 0) + 1
else: # unknown
sex_count[ "unknown"] = sex_count.get( "unknown", 0) + 1
# 柱状图展示
for i, key in enumerate(sex_count):
plt.bar(key, sex_count[key])
plt.savefig( "analysisSex.png") #保存图片
plt.ion()
plt.close()
结果如下:

个性签名
在获取的好友信息中Signature字段对应着好友的签名,
我们直接获取这部分信息,然后保存下来,处理过表情等特殊字符,然后制作词云图。
def AnalysisSignature():
itchat.login()
friends = itchat.get_friends(update= True)
file = open( 'AnalysisSignature.txt', 'a', encoding= 'utf-8')
for f in friends:
signature = f[ "Signature"].strip().replace( "emoji", "").replace( "span", "").replace( "class", "")
# 正则匹配
rec = re.compile( "1f\d+\w*|[<>/=]")
signature = rec.sub( "", signature)
file.write(signature + "\n")
itchat.login()
friends = itchat.get_friends(update= True)
file = open( 'AnalysisSignature.txt', 'a', encoding= 'utf-8')
for f in friends:
signature = f[ "Signature"].strip().replace( "emoji", "").replace( "span", "").replace( "class", "")
# 正则匹配
rec = re.compile( "1f\d+\w*|[<>/=]")
signature = rec.sub( "", signature)
file.write(signature + "\n")
"stay hungry, stay foolish"
"不舍爱与自由"
大家对生活都是积极向上的,希望每个人都能成为更好的自己!
地区分布
为了统计好友的地区分布,所以要用到好友信息的province字段,直接对province进行统计,然后可视化出来得到。
# 省份分析
def analysisProvince():
friends_info = get_friends_info()
df = pd.DataFrame(friends_info)
province_count = df.groupby( 'province', as_index= True)[ 'province'].count().sort_values()
temp = list(map( lambda x: x if x != '' else '未知', list(province_count.index)))
# 画图
page = Page()
style = Style(width= 1100, height= 600)
style_middle = Style(width= 900, height= 500)
attr, value = temp, list(province_count)
chart1 = Map( '好友分布(中国地图)', **style.init_style)
chart1.add( '', attr, value, is_label_show= True, is_visualmap= True, visual_text_color= '#000')
page.add(chart1)
chart2 = Bar( '好友分布柱状图', **style_middle.init_style)
chart2.add( '', attr, value, is_stack= True, is_convert= True,
label_pos= 'inside', is_legend_show= True, is_label_show= True)
page.add(chart2)
page.render( 'analysisProvince.html')
def analysisProvince():
friends_info = get_friends_info()
df = pd.DataFrame(friends_info)
province_count = df.groupby( 'province', as_index= True)[ 'province'].count().sort_values()
temp = list(map( lambda x: x if x != '' else '未知', list(province_count.index)))
# 画图
page = Page()
style = Style(width= 1100, height= 600)
style_middle = Style(width= 900, height= 500)
attr, value = temp, list(province_count)
chart1 = Map( '好友分布(中国地图)', **style.init_style)
chart1.add( '', attr, value, is_label_show= True, is_visualmap= True, visual_text_color= '#000')
page.add(chart1)
chart2 = Bar( '好友分布柱状图', **style_middle.init_style)
chart2.add( '', attr, value, is_stack= True, is_convert= True,
label_pos= 'inside', is_legend_show= True, is_label_show= True)
page.add(chart2)
page.render( 'analysisProvince.html')
比较明显的一个点是,我们的好友大多来自我们生活过的地方,安徽和上海这两个地区好友数量都明显高于其他省份。

号主户籍安徽,利用城市信息看一下我的朋友都在哪里。
从下面的好友数量来看,号主明显是个安庆人。

你们可以直接修改源码的省份参数,获取你想了解的省份的好友分布。
源码下载:
https://pan.baidu.com/s/1jjcFC1dHQkU3r5LmUj7LIQ
密码:0eco
扫码查看原文
▼▼▼

(*本文为AI科技大本营转载文章,转载请联系作者)
◆
精彩推荐
◆
11.11惠不可挡!
BDTC 2019双十一豪礼大放送,凡11.11当天购买大会“单人票”,即可额外获得价值298元CSDN VIP年卡!(VIP年卡特权:全站免广告+600个资源免积分下载+学院千门课程免费看+购课9折)~
扫描下图二维码或点击阅读原文,领取你的VIP吧!