超清还不够,商汤插帧算法让视频顺滑如丝 | NeurIPS 2019 Spotlight论文

自相机被发明以来,人们对更高画质视频的追求就没有停止过。
分辨率从480p,720p,再到1080p,现在有了2K、4K;帧率也从25FPS到 60FPS,再到240FPS,960FPS甚至更高……
如果仅靠相机的硬件迭代来提升帧率,存在局限性,因为相机传感器在单位时间内捕捉到的光有局限。而且相机硬件迭代的周期长,成本高。
最近,商汤移动智能研究总监孙文秀的团队,提出了一种可以感知视频中运动加速度的视频插帧算法(Quadratic Video Interpolation),打破了之前插帧方法的线性模型,将二次方光流预测和深度卷积网络进行融合,让你的视频顺滑如丝。
这种方法有多厉害?来看一个对比:
如果把视频放慢就能明显感觉到,未经过插帧的慢放视频(左)会明显卡顿,而经过商汤Quadratic(二次方)视频插帧方法处理的视频(右)播放流畅。
这个方法的论文被NeurIPS 2019接受为Spotlight论文,该方法还在ICCV AIM 2019 VideoTemporal Super-Resolution Challenge比赛中获得了冠军。
之前的视频插帧方法(包括Phase[1]、DVF[2]、SepConv[3]和SuperSloMo[4]等)是假设相邻帧之间的运动是匀速的,即沿直线以恒定速度移动。然而,真实场景中的运动通常是复杂的、非线性的,传统线性模型会导致插帧的结果不准确。
以抛橄榄球的运动视频为例(如下图1),真实运动中的轨迹是一条抛物线,如果在第0帧和第1帧之间进行插帧,线性模型方法模拟出来轨迹是线性轨迹(右二),与真实运动轨迹(右三)相差较大。

图1 传统线性模型与商汤二次方视频插帧结果对比
但通过商汤二次方视频插帧模型模拟出来的运动轨迹是抛物线形(图1右一),更逼近真实轨迹。也就是说,它能够更准确地估计视频相邻帧之间的运动并合成中间帧,从而获得更精准的插帧结果。
二次方插帧是怎样“炼”成的?
商汤研究团队构建了一个可以感知视频运动加速度的网络模型。与传统线性插帧模型利用两帧输入不同,它利用了相邻四帧图像来预测输入帧到中间帧的光流,简易的流程图如下:

图2 二次方插帧模型的流程
![]() 是输入视频连续的四帧。给定任意时刻t(0
是输入视频连续的四帧。给定任意时刻t(0![]() ,就需要更深入了解其中的两个关键技术:二次方光流预测和光流逆转。
,就需要更深入了解其中的两个关键技术:二次方光流预测和光流逆转。
其中,二次方光流预测,就是中学物里面常讲到的求匀变速运动位移的过程:假设在[-1, 1]时刻的运动是匀加速运动,那么可以利用位移推测出0时刻的速度和区间内的加速度,即可以计算出0时刻到任意t时刻的位移:
![]()
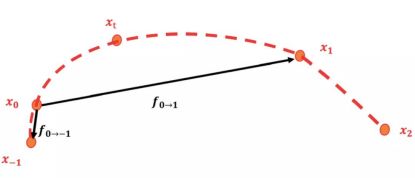
图3:视频中物体运动的示意图

通过以上方法,对称地我们可以计算出![]() 。此时,我们得到了含有加速度信息
。此时,我们得到了含有加速度信息![]() 和
和![]() 。
。
为了生成高质量的中间帧,我们需要得到反向光流![]() 和
和![]() 。
。
为此商汤研究团队提出一个可微分的“光流逆转层”来预测![]() 和
和![]() 。通过以下转换公式可以高效地将
。通过以下转换公式可以高效地将![]() 和
和![]() 转化为
转化为![]() 和
和![]() ,但是可能会造成逆转的光流在运动边界处出现强烈的振铃效应(见图4)。
,但是可能会造成逆转的光流在运动边界处出现强烈的振铃效应(见图4)。

为了消除这些强烈震荡的部分,商汤研究团队提出了一种基于深度神经网络的、能够对逆转后光流进行自适应采样的滤波器(Adaptive Flow Filter)。
![]()
实验证明,自适应滤波器(ada.)能够明显削弱光流逆转造成的振铃效应,从而改善最终合成帧的质量。

图4 自适应滤波器能够改善逆转的光流和合成的中间帧的质量
实验结果
商汤研究团队在GOPRO、Adobe240、UCF101和DAVIS四个知名视频数据集上对提出的方法进行测评,并与业界前沿的插帧方法Phase、DVF、SepConv和SuperSloMo进行比较。在每个数据集上,商汤二次视频插针方法都大幅超过现有的方法(见表1、表2)。

表1 商汤提出的方法和业界前沿方法在GOPRO和Adobe240数据集上的比较

表2 商汤提出的方法和业界前沿方法在UCF101和DAVIS数据集上的比较
除此之外,商汤研究团队还对各种方法生成中间帧进行了关键点跟踪并进行可视化,从图5中两个案例的视频运动轨迹可以看出,用真实慢动作相机采集的中间帧(GT)的运动轨迹是曲线的。线性模型(SepConv、SuperSloMo、Oursw/o qua)生成的中间帧的运动轨迹都是直线,相反,商汤的模型(Ours)能够更精准的预测出非线性轨迹,获得更好的插帧结果。
图5 对不同方法的插帧结果进行可视化。第一行和第三行是每种方法的插帧结果和真实图像中间帧(GT)的平均。第二行和第四行对每种方法的插帧结果进行关键点跟踪。
综上,商汤提出的能够感知视频中运动加速度的插帧方法相比已有的线性插帧算法,能够过更好地预测中间帧。
[1] S.Meyer, O.Wang, H. Zimmer, M. Grosse, and A. Sorkine-Hornung. Phase-based frameinterpolation forvideo.In CVPR, 2015
[2]Z. Liu,R. Yeh, X. Tang, Y. Liu, and A. Agarwala. Video frame synthesis using deepvoxel flow. In ICCV,2017.
[3] S. Niklaus, L. Mai, and F. Liu. Video frame interpolationvia adaptive separable convolution. In ICCV,2017
[4] H.Jiang, D. Sun, V. Jampani, M. Yang, E. G. Learned-Miller, and J. Kautz. Superslomo: High quality estimationof multiple intermediate frames for video interpolation. In CVPR, 2018.
(*本文为AI科技大本营投稿文章,转载请微信联系 1092722531)
◆
精彩公开课
◆

推荐阅读
GitHub宝藏项目标星1.6w+,编程新手有福了
芬兰开放“线上AI速成班”课程,全球网民均可免费观看
英特尔首推异构编程神器 oneAPI,可让程序员少加班!
该如何缓解网卡的普遍问题?
英特尔首推异构编程神器 oneAPI,可让程序员少加班!
马云穿布鞋演讲,任正非打的出行,盘点科技大佬们令人发指的节俭生活
行!人工智能玩大了!程序员:太牛!你怎么看?
2019 区块链大事记 | Libra 横空出世,莱特币减产,美国放行 Bakkt……这一年太精彩!
谁是蒋涛?

你点的每个“在看”,我都认真当成了AI