图像语义分割入门:FCN/U-Net网络解析

向AI转型的程序员都关注了这个号????????????
机器学习AI算法工程 公众号:datayx
图像语义分割(Semantic Segmentation)是图像处理和是机器视觉技术中关于图像理解的重要一环,也是 AI 领域中一个重要的分支。语义分割即是对图像中每一个像素点进行分类,确定每个点的类别(如属于背景、人或车等),从而进行区域划分。目前,语义分割已经被广泛应用于自动驾驶、无人机落点判定等场景中。

而截止目前,CNN已经在图像分类分方面取得了巨大的成就,涌现出如VGG和Resnet等网络结构,并在ImageNet中取得了好成绩。CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:
较浅的卷积层感知域较小,学习到一些局部区域的特征;
较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。
这些抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于分类性能的提高。这些抽象的特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体。图像分类是图像级别的!

与分类不同的是,语义分割需要判断图像每个像素点的类别,进行精确分割。图像语义分割是像素级别的!但是由于CNN在进行convolution和pooling过程中丢失了图像细节,即feature map size逐渐变小,所以不能很好地指出物体的具体轮廓、指出每个像素具体属于哪个物体,无法做到精确的分割。
针对这个问题,Jonathan Long等人提出了Fully Convolutional Networks(FCN)用于图像语义分割。自从提出后,FCN已经成为语义分割的基本框架,后续算法其实都是在这个框架中改进而来。
FCN论文地址:FCN paper
https://arxiv.org/abs/1411.4038
FCN原作代码:FCN github
https://github.com/shelhamer/fcn.berkeleyvision.org
1 FCN改变了什么?
对于一般的分类CNN网络,如VGG和Resnet,都会在网络的最后加入一些全连接层,经过softmax后就可以获得类别概率信息。但是这个概率信息是1维的,即只能标识整个图片的类别,不能标识每个像素点的类别,所以这种全连接方法不适用于图像分割。
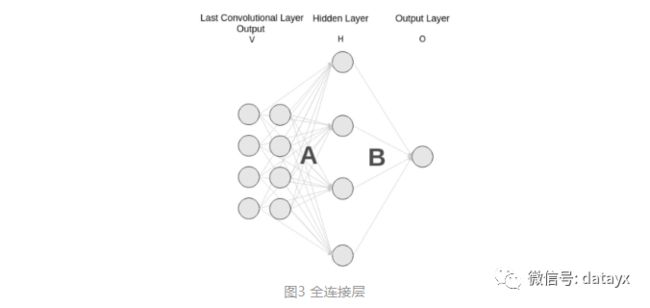
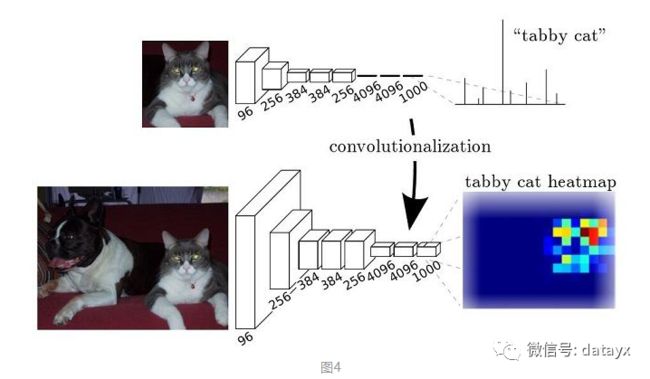
而FCN提出可以把后面几个全连接都换成卷积,这样就可以获得一张2维的feature map,后接softmax获得每个像素点的分类信息,从而解决了分割问题,如图4。
2 FCN结构
整个FCN网络基本原理如图5(只是原理示意图):
image经过多个conv和+一个max pooling变为pool1 feature,宽高变为1/2
pool1 feature再经过多个conv+一个max pooling变为pool2 feature,宽高变为1/4
pool2 feature再经过多个conv+一个max pooling变为pool3 feature,宽高变为1/8
......
直到pool5 feature,宽高变为1/32。
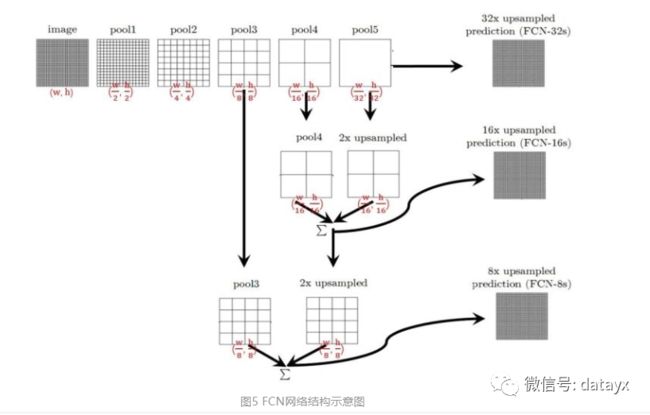
那么:
对于FCN-32s,直接对pool5 feature进行32倍上采样获得32x upsampled feature,再对32x upsampled feature每个点做softmax prediction获得32x upsampled feature prediction(即分割图)。
对于FCN-16s,首先对pool5 feature进行2倍上采样获得2x upsampled feature,再把pool4 feature和2x upsampled feature逐点相加,然后对相加的feature进行16倍上采样,并softmax prediction,获得16x upsampled feature prediction。
对于FCN-8s,首先进行pool4+2x upsampled feature逐点相加,然后又进行pool3+2x upsampled逐点相加,即进行更多次特征融合。具体过程与16s类似,不再赘述。
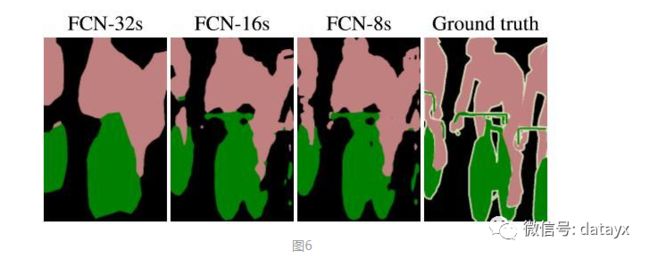
作者在原文种给出3种网络结果对比,明显可以看出效果:FCN-32s < FCN-16s < FCN-8s,即使用多层feature融合有利于提高分割准确性。
3 什么是上采样?
说了半天,到底什么是上采样?
实际上,上采样(upsampling)一般包括2种方式:
Resize,如双线性插值直接缩放,类似于图像缩放(这种方法在原文中提到)
Deconvolution,也叫Transposed Convolution
什么是Resize就不多说了,这里解释一下Deconvolution。
对于一般卷积,输入蓝色4x4矩阵,卷积核大小3x3。当设置卷积参数pad=0,stride=1时,卷积输出绿色2x2矩阵,如图6。
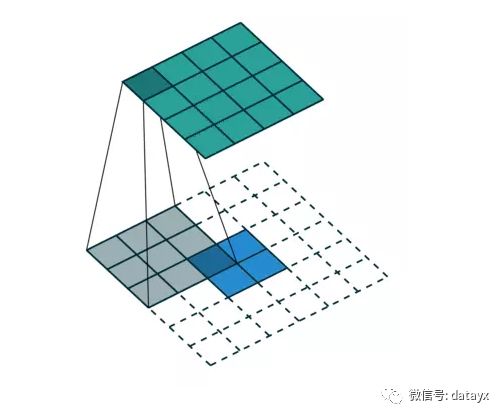
而对于反卷积,相当于把普通卷积反过来,输入蓝色2x2矩阵,卷积核大小还是3x3。当设置反卷积参数pad=0,stride=1时输出绿色4x4矩阵,如图7,这相当于完全将图4倒过来(其他更多卷积示意图点这里)。
https://github.com/vdumoulin/conv_arithmetic
传统的网络是subsampling的,对应的输出尺寸会降低;upsampling的意义在于将小尺寸的高维度feature map恢复回去,以便做pixelwise prediction,获得每个点的分类信息。
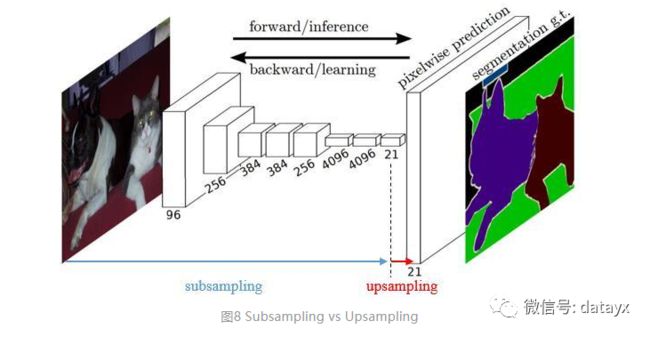
上采样在FCN网络中的作用如图8,明显可以看到经过上采样后恢复了较大的pixelwise feature map(其中最后一个层21-dim是因为PACSAL数据集有20个类别+Background)。这其实相当于一个Encode-Decode的过程。
具体的FCN网络结构,可以在fcn caffe prototext (https://github.com/shelhamer/fcn.berkeleyvision.org/blob/master/pascalcontext-fcn8s/train.prototxt )中查到,建议使用Netscope查看网络结构。这里解释里面的难点:
为了解决图像过小后 1/32 下采样后输出feature map太小情况,FCN原作者在第一个卷积层conv1_1加入pad=100。






4 U-Net
U-Net原作者官网
https://link.zhihu.com/?target=https%3A//lmb.informatik.uni-freiburg.de/Publications/2015/RFB15a/
U-Net是原作者参加ISBI Challenge提出的一种分割网络,能够适应很小的训练集(大约30张图)。U-Net与FCN都是很小的分割网络,既没有使用空洞卷积,也没有后接CRF,结构简单。
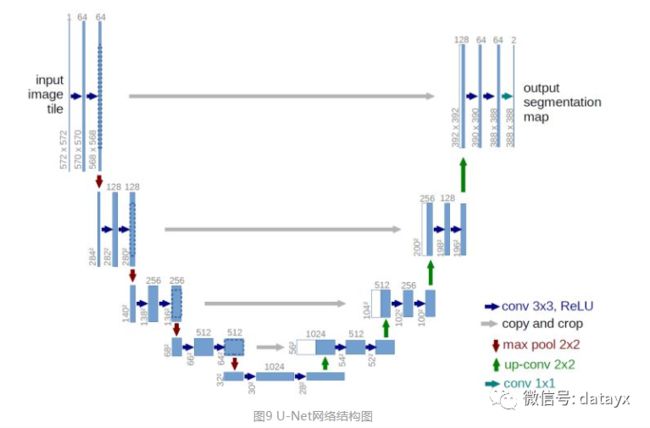
整个U-Net网络结构如图9,类似于一个大大的U字母:首先进行Conv+Pooling下采样;然后Deconv反卷积进行上采样,crop之前的低层feature map,进行融合;然后再次上采样。重复这个过程,直到获得输出388x388x2的feature map,最后经过softmax获得output segment map。总体来说与FCN思路非常类似。
为何要提起U-Net?是因为U-Net采用了与FCN完全不同的特征融合方式:拼接!
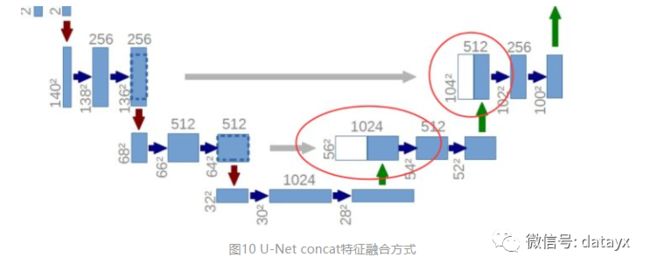
与FCN逐点相加不同,U-Net采用将特征在channel维度拼接在一起,形成更“厚”的特征。所以:
语义分割网络在特征融合时也有2种办法:
FCN式的逐点相加,对应caffe的EltwiseLayer层,对应tensorflow的tf.add()
U-Net式的channel维度拼接融合,对应caffe的ConcatLayer层,对应tensorflow的tf.concat()
记得划重点哦。
相比其他大型网络,FCN/U-Net还是蛮简单的,就不多废话了。
总结一下,CNN图像语义分割也就基本上是这个套路:
下采样+上采样:Convlution + Deconvlution/Resize
多尺度特征融合:特征逐点相加/特征channel维度拼接
获得像素级别的segement map:对每一个像素点进行判断类别
看,即使是更复杂的DeepLab v3+依然也是这个基本套路(至于DeepLab以后再说)。
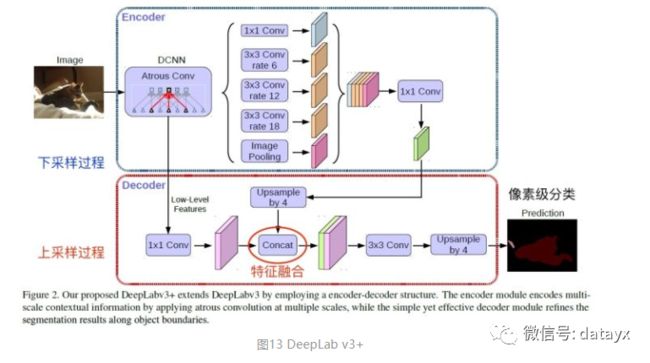
所以作为一篇入门文章,读完后如果可以理解这3个方面,也就可以了;当然CNN图像语义分割也算入门了。
参考链接 https://zhuanlan.zhihu.com/p/22976342
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《基于深度学习的自然语言处理》中/英PDF
Deep Learning 中文版初版-周志华团队
【全套视频课】最全的目标检测算法系列讲解,通俗易懂!
《美团机器学习实践》_美团算法团队.pdf
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
特征提取与图像处理(第二版).pdf
python就业班学习视频,从入门到实战项目
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

机大数据技术与机器学习工程
搜索公众号添加: datanlp

长按图片,识别二维码