Word Embedding学习笔记
在NLP中,对文本的表示方法:
- bag-of-words:基于one-hot、tf-idf、textrank等
- 主题模型:LSA(SVD)、pLSA、LDA;
- 基于词向量的固定表征:word2vec、fastText、GloVe;
- 基于词向量的动态表征:elmo、GPT、bert
上面这个分类还有再查一下
各种词向量的特点:
- One-hot:维度灾难 和 语义鸿沟
- 矩阵分解(LSA):利用全局语料特征,但SVD求解计算复杂度大
- 基于NNLM / RNNLM的词向量:词向量为副产物,存在效率不高等问题
- word2vec、fastText:优化效率高,但基于局部语料
- glove:结合了LSA和word2vec的优点,基于全局语料
- elmo、GPT、bert:动态特征
tf-idf是什么?
tf(Term Frequency)即 词频,指某个词在文章中出现的次数。这个数字通常会被归一化(词频 / 文章总词数),以防止它偏向长的文章。
idf(inverse Document Frequency)逆文档频率:即 log(语料库文档总数 / 包含该词的文档)
特点:1)tf-idf可用某篇文章中出现次数多但在其他文章中出现次数少的词来作为该文章的特征词。2)使罕见单词更加突出且有效忽略了常用单词。
缺点:1)因为是词袋模型,没有考虑词的位置,但其实词的位置是有一定含义的。2)并不能反映单词的重要程度和特征词的分布情况。
与之类似的one-hot独热编码形式,即一个词占一维向量。也有两个缺点:
1)不考虑词与词之间的顺序(文本中词的顺序也很重要,例如小明在揍我 和 我在揍小明 是完全不一样的意思)
2)假设词是独立的。但不同词之前猫和狗、床和沙发,词之间原本是有不同的亲疏远近关系的
3)得到的特征是稀疏的。如果所有的词各占一维,那么这个向量会过于稀疏,甚至造成维度灾难。
之后又衍生出了word class的概念,即把不同的词分为不同的类别。但这样仍然会有一些信息无法表达,例如class1和class3都是生物,class2是class1可以完成的动作而class3不能完成。
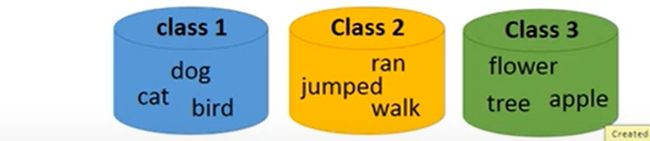
于是又衍生出了word embedding。
例如下图,x轴代表生物词汇和非生物词汇的区别,y轴代表动和不动的词汇区别。

word embedding(词嵌入),即将高维词向量嵌入到一个低维空间,其实就是把词用数学形式表示出来。是非监督学习。
从建模的角度来讲,这个也叫做distributed representation(代表了词用vector表示,词含义分散在每个维度上,反面是one-hot vector,即只有一个离散的值)
Word Embedding有两种方法:
1)count based method 2)prediction based
1. count based
PMI matrix
如果两个词汇 w1 和 w2 经常一起出现,那么V(w1) 和 V(w2) 会比较接近
例如 glove vector
V(w1) · V(w2) (inner product) <--> N1,2 (表示w1 和 w2在同一个文章中出现的次数)
我们希望这两个结果越接近越好
2. prediction based
通过训练,将每个词映射到较短的词向量上(实际中,较难对较短词向量的每个维度做很好解释)。较短词向量的维度,一般训练时自己指定。
映射需满足:1)这个映射是单设;2)映射后向量不会丢失所含的信息。
这个映射过程也就是降维,嵌入的训练过程会引入词的上下文。感觉更像是CNN中channel数的变换。
有了这种表示的较短词向量,可以更容易分析词之间的关系。例如vec(King) - vec(Man) + vec(Woman) = vec(Queen)

predictive methods中比较常用的两个方法是word2vec和GloVe(global vector for word representation)
2.1)word2vec
word2vec从原始文本(raw text)中学习单词表示的效率高。
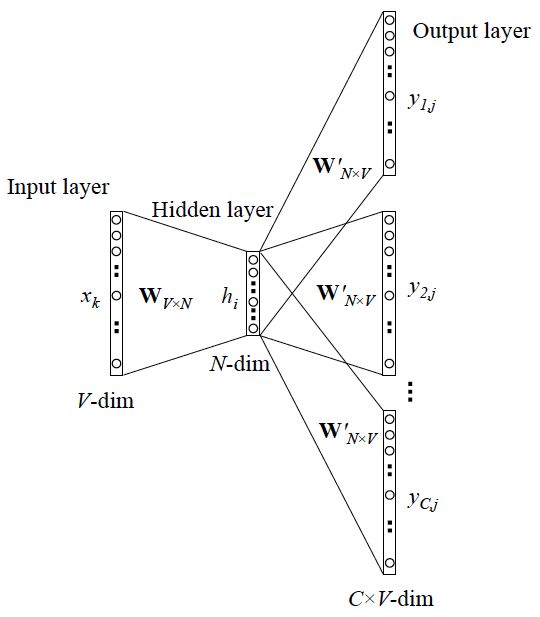
这个语言模型,本质上就是一个简化的神经网络
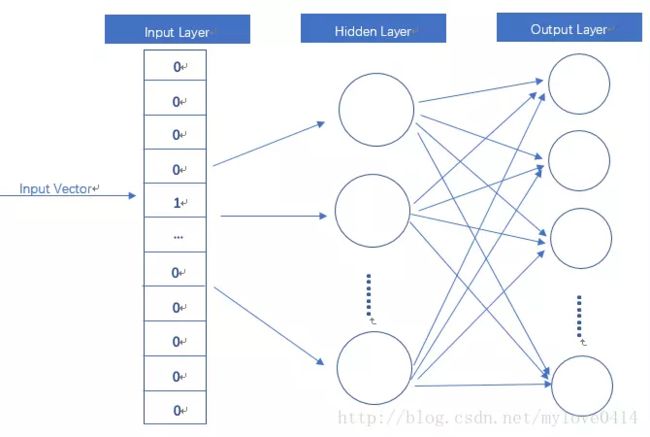
input layer输入向量是onehot形式。hidden layer没有激活函数,是线性单元。output layer维度与input layer维度一样,使用softmax。
而当用这个模型训练好后,我们真正需要的是这个模型通过训练学得的参数,即隐层权重矩阵。
word2vec中具体的语言模型分为两种,CBOW(Continuous Bag-of-Words)与Skip-Gram。
Skip-gram 是预测一个词的上下文,而 CBOW 是用上下文预测这个词
2.1.1)CBOW
通过上下文预测这个词

输入层:
上下文单词的onehot作为输入。其中上下文单词数量为C,C这个由超参window size决定,如果window size=2 表示取target word的前两个单词和后两个单词作为input词,此时C=4。一般input 10个words。每个单词的向量dim为V。
所有onehot分别乘以共享的输入权重矩阵WV*N,其中N为降维后的维度——超参。这里的WV*N 就是我们最终想要的。
所得的向量相加求平均作为输入给隐层向量,得到的shape为 1*N
输入词向量分别乘以W再相加求平均 和 输入词向量相加求平均再乘以W是一样的。
在实作时,如何保证WV*N是sharing parameters呢?
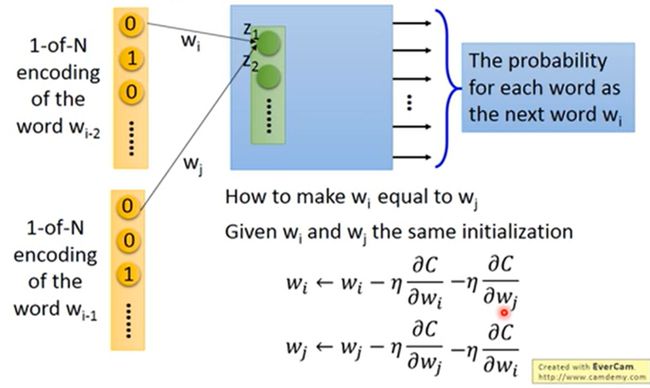
答案是 1)一开始初始化时给wi 和 wj 相同的初始值。2)更新参数时,除了自身的梯度,也减去其他w的梯度。以保持梯度的更新也都是一样的。
隐藏层:
输入的向量乘以输出权重矩阵W'N*V ,得到的shape为 1*V。
输出层:
再经过softmax激活函数处理,得到 V 维的概率分布(还原成原来的输入维度),每维代表一个单词。
概率最大的单词即为预测出的target word(中间词)。将target word与true label的onehot比较,误差越小越好。一般使用交叉熵代价函数。
根据此误差再更新权重矩阵。采用梯度下降法、反向传播来更新W和W'。
训练完成后,W 这个矩阵就是所有单词的word embedding,也叫look up table。有了W,任一单词的onehot乘以W这个矩阵都将得到自己的词向量(word embedding)了。乘以这个矩阵其实就相当于在查表。
那 W ‘ 不需要了吗?
是的不需要了。因为本质上就是想降维。W其实就是我们需要的降维转换表。乘以 W后,得到的dim更小了,降维了的同时还保留了原来的信息。W ' 是将降了维的向量可以再复原成原来的onehot向量,所以就不需要了。
2.1.2)Skip-Gram
通过输入词,预测词典中其他每个词与输入词同时出现的概率。
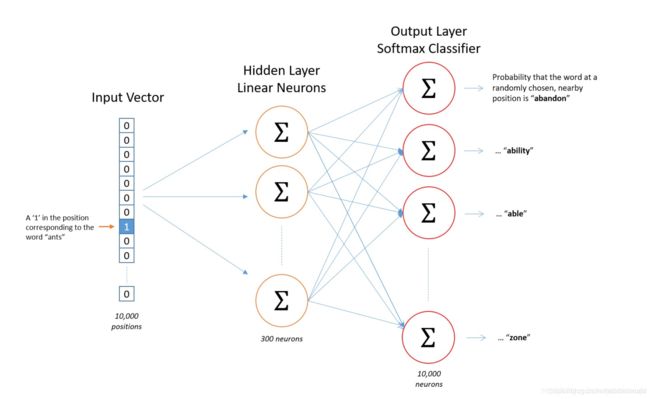
Skip-gram的cost function是单个cost function取log后的累加
input word:输入词。
skip-window:代表从input word左右两边选词的数量
num-skips:代表选多少个词作为output word
例如句子:
“The quick brown fox jumps over lazy dog”
蓝色方框代表input word。window_size=2,左右各选2个词
Training samples即(输入,输出),此处列出的是window size中包含的所有可能。
如果限制num_skips=2,则只会取前两个。例如quick为input word时,只会选择(quick, the)和(quick,brown)。
(quick, the)和(quick,brown)分别送入input layer进行训练,会分别输出词汇表中每个单词是 the 和 brown的概率。模型的输出概率代表词典中每个词有多大可能与input word同时出现。

2.1.3)CBOW 和Skip-gram对比
CBOW对小型语料比较合适,Skip-Gram在大型语料中表现更好。
看到很多博客都写了上面这句话,但是为什么呢?
查了资料后我感觉按上面这么说并不十分准确,很容易引起我这种初学者的误解。
CBOW训练时有一个target word和许多context words。Skip-gram训练时,一个context word和许多target word。也就是说CBOW多对一,Skip-gram一对多。所以CBOW需要更大的数据集。
而CBOW在训练时,在同一上下文中需要为句子中每个target word都计算一遍这些上下文的average。所以更适合短的句子。Skip-gram相反。
总结来说,就是:
CBOW 更适合 短句子,多数据量
Skip-gram 更适合 长句子,小数据量
可参考https://stackoverflow.com/questions/39224236/word2vec-cbow-skip-gram-performance-wrt-training-dataset-size
Skip-Gram比CBOW更适合非常见词汇
因为在CBOW中,输入向量由context words做平均后再用于预测target word。而skip-gram中没有这一步骤。不让非常见词汇和周围的context words做平均,可以让模型对这个非常见词的表达学的更好。
举例来说:
yesterday was really [...] day. CBOW模型会认为target word更可能是beautiful、nice之类的词。而像delightful这样的词的概率会小很多。因为CBOW被设计为预测最可能出现的词。非常见词汇的概率比常见词汇出现的概率小很多。
而Skip-gram被设计为预测内容。给到delightful这个词时,skip-gram不会试图和beautiful这个词battle,而是会给出类似yesterday was really [...] day这样的预测内容。因为它是从非常见词汇的这个词汇出发。
可参考:https://stats.stackexchange.com/questions/180548/why-is-skip-gram-better-for-infrequent-words-than-cbow
Cbow比Skip-gram更快
因为Cbow用周围词预测target word,只需要把窗口内其他词相加一次作为输入来预测target word。不论窗口多大,只需要一次运算。而skip-gram直接受窗口影响,窗口越大,需要预测的周围词越多。
2.1.4)word2vec的训练trick
使用训练技巧是因为,word2vec本质是语言模型,其输出节点数是V个,对应了V个词语,本质上是一个多分类问题。而在实际中,词典V的个数非常多,会给计算造成很多困难,需用一些trick来加速训练。
hierarchical softmax
是softmax的一种近似形式。本质上把N分类问题变为log(N)次二分类
negative sampling
本质是预测总体类别的一个子集
word2vec并非效果最好的word embedding的工具,最明显的缺点是word2vec没有考虑语序,会有训练效果损失。但因为训练速度快,使用的人很多。训练快是因为word2vec中都是线性的计算,而且源码中有一些提速的trick,再而且采用一次计算,以后查表,减去了大量重复计算。
2.1.5)word2vec的训练参数
示例:


1 from gensim.models import word2vec 2 3 # train model 4 def train_word2vec(x): 5 # 训练word to vector 的 word embedding 6 model = word2vec.Word2Vec(x, size=250, window=5, min_count=5, workers=12, iter=10, sg=1) 7 return model 8 9 # save model 10 model = train_word2vec(train_x + train_x_no_label + test_x)#传入所有可能会遇见的词 11 model.save(os.path.join(path_prefix, 'w2v_all.model')) 12 13 # load model 14 model = Word2Vec.load("w2v_all.model") 15 print(model.similarity('Chinese', 'China'))
具体训练参数如下:
- sentences=None:可以是一个list。对于大语料库,建议使用brownCorpus、Text8Corpus或lineSentence构建
- size=100:特征向量的维度
- alpha=0.025:初始学习率,训练过程中会线性递减到min_alpha
- window=5:窗口大小,表示当前词与预测词在一个句子中最大距离是多少
- min_count=5:对字典做过滤,词频小于min_count的单词会被舍弃
- max_vocab_size=None:设置词向量构建期间RAM限制,None表示没有限制
- sample=1e-3:高频词随机降采样的配置阈值,范围(0, 1e-5)
- seed=1:随机数发生器,与词向量初始化有关
- workers=3:用于控制训练的并行数
- min_alpha=0.001:学习率最小值
- sg=0:设置训练算法。0--CBOW, 1--Skip-gram
- hs=0:设置训练技巧。0--negative sampling, 1--hierarchica softmax
- negative=5:设置多少个noise words。如果>0,则采用negative sampling,一般是5-20.
- cbow_mean=1:采用上下文词向量的均值,如果设置为0,表示采用上下文词向量的和。只有使用CBOW时才起作用
- hashfxn=hash:hash函数来初始化权重
- iter=5:迭代次数
- trim_rule=None:设置词汇表整理规则,指定哪些单词留下,哪些删除。设置为None时,min_count会被使用
- sorted_vocab=1:分配word index时按单词词频降序排序
- batch_words=10000:每一批传递给线程的单词的数量
参数选择
skip-gram训练速度慢,对罕见字表现更好。CBOW训练速度更快。一般用skip-gram
hierachical softmax对罕见字更有利,nagative sampling对常见字和低维向量更有利
欠采样频繁词可以提高结构的准确性和速度(1e-3 ~ 1e-5)
skip-gram的window一般选10左右,CBOW通常选5左右
待补充glove。。。。
记录学习用,大多整理自以下参考博客。
参考博客:
https://www.jianshu.com/p/471d9bfbd72f
https://zhuanlan.zhihu.com/p/26306795
https://www.cnblogs.com/peghoty/p/3857839.html
https://towardsdatascience.com/word-embeddings-for-sentence-classification-c8cb664c5029
https://zhuanlan.zhihu.com/p/29364112
https://www.zhihu.com/search?type=content&q=glove