a、status=408什么也没有操作
b、status=201微信扫了码但是没有点击确认
c、status=200代表扫码成功并确认登陆
前端是当页面加载完成才弄下一次请求,利用ajax请求,当status=408时,一直在加载请求,当status=201时,获取用户头像一直加载请求,直到status=200才跳转到另一个页面,涉及到登陆记得加cookie
1、请求登陆的地址,请求登陆的 时候会有上面说的三种状态,分别判断
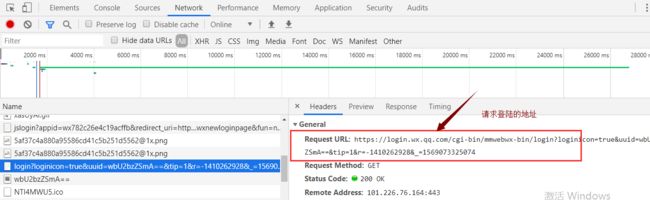
2、如果是确认扫码登陆了,会返回一个redirect_uri地址,这个地址用来请求获取用户的信息ticket,返回的地址与页面请求返回的少了"&fun=new&version=v2&lang=zh_CN",得加上这个才能获取ticket
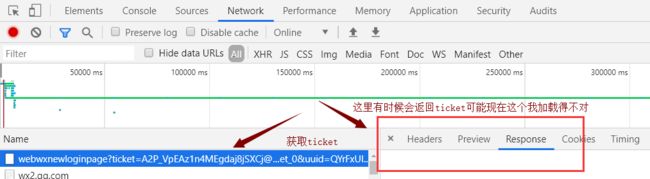
返回的ticket如下:
0
@crypt_dd043c47_d6303d6aed797c295a21960d9c2d729c hYiHcYEqVMC4Kim9 795592819 aNUg%2B%2FHFbBavV3w9ndTBh8hjSErIhrkBBGVl0PV F%2B9lQhFi5KtGYjlWCv2%2FoBrQf
1
3、url地址,webchat/urls.py
path('polling/', views.long_pooling, name="long_pooling"),
4、前端页面,templates/webch.html
Wechat

5、后台登陆的三种状态判断,web/views.py
# Create your views here.
from django.shortcuts import render
from django.shortcuts import HttpResponse
import requests
import re
import time
import json
from bs4 import BeautifulSoup
VERIFY_TIME =None
verifi_uuid =None
LOGIN_COOKIE_DICT = {}
TICKET_COOKIE_DICT= {}
TICKET_DATA_DICT = {}
TIPS=1
def long_pooling(request):
"""二维码长轮询获取登陆"""
"""
1、status=408什么也没有操作
2、status=201微信扫了码但是没有操作
3、status=200代表扫码成功并确认登陆
"""
#返回的json状态和数据
ret = {"status":408,"data":None}
#二维码长轮询url
try:
#TIPS=0是没有过于频繁的轮询.刚开始是为1
global TIPS
#请求的地址,uuid=verifi_uuid,后面那个值是随机生产时间戳
base_pooling_url = "https://login.wx.qq.com/cgi-bin/mmwebwx-bin/login?loginicon=true&uuid={0}&tip={1}&r=-1322669031&={2}"
pooling_url= base_pooling_url.format(verifi_uuid,TIPS,VERIFY_TIME)
reponse_login = requests.get(url=pooling_url)
#print("pooling_reponse.text",pooling_reponse.text)
#扫码一直没有点击登陆,状态码是201,获取返回头像数据
if "window.code=201" in reponse_login.text:
#获取头像图片地址
TIPS = 0
#获取图片地址
avatar = re.findall("userAvatar = '(.*)';",reponse_login.text)[0]
#print("avatar",avatar)
#更新状态和内容
ret["status"] = 201
ret["data"] = avatar
#print("reponse_login",reponse_login.text)
elif "window.code=200" in reponse_login.text:
#登陆时候获取的cookies
LOGIN_COOKIE_DICT.update(reponse_login.cookies.get_dict())
#登陆成功返回一个重定向地址,这个地址请求可以获取用户信息ticket
redirect_uri = re.findall('redirect_uri="(.*)";',reponse_login.text)[0]
redirect_uri+="&fun=new&version=v2&lang=zh_CN"
#print("redirect_uri",redirect_uri)
#获取ticket和添加ticket的cookie
reponse_ticket = requests.get(url=redirect_uri,cookies=LOGIN_COOKIE_DICT)
TICKET_COOKIE_DICT.update(reponse_ticket.cookies.get_dict())
#print("reponse_ticket:",reponse_ticket.text)
#找出ticket里的值
soup=BeautifulSoup(reponse_ticket.text,"html.parser")
for tag in soup.find():
#print(tag.name,tag.string)
#把数据存入到dict中,为了下次请求的时候使用
TICKET_DATA_DICT[tag.name]=tag.string
#print("TICKET_DATA_DICT",TICKET_DATA_DICT)
ret["status"] = 200
except Exception as e:
print(e)
return HttpResponse(json.dumps(ret))
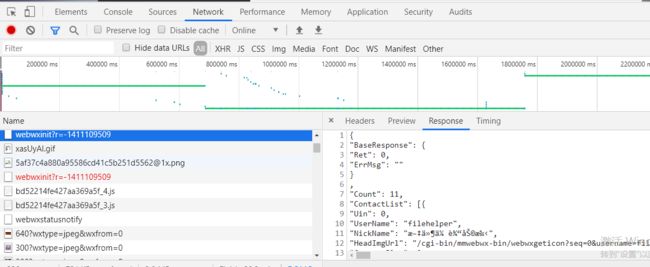
微信登陆的页面初始化,获取用户的基本信息
找到获取用户信息请求地址

返回的用户信息
path('index/', views.index, name="index"),
后台的请求获取用户信息,web/views.py
def index(request):
"""微信登陆的页面初始化,获取用户的基本信息"""
user_init_url = "https://wx2.qq.com/cgi-bin/mmwebwx-bin/webwxinit?r=-1332226764"
payload_data = {
"DeviceID":"e379444626462097",
"Sid":TICKET_DATA_DICT["wxsid"],
"Skey":TICKET_DATA_DICT["skey"],
"Uin":TICKET_DATA_DICT["wxuin"]
}
cookie_all = {}
#因为不知道用哪个cookie所以上面两个都给加上了
cookie_all.update(LOGIN_COOKIE_DICT)
cookie_all.update(TICKET_COOKIE_DICT)
#返回的内容是用户的信息
reponse_init=requests.post(url=user_init_url,json=payload_data,cookies=cookie_all)
print("reponse_init",reponse_init)
return render(request,"index.html",{"data":reponse_init.text,})注:因为之前是图片加载完成就发送请求,造成前端status不等于200就不断轮询pedding,然后使django的wsgi引发错误(太多的请求,wsgi不知获取那个信息):
self.status.split(' ',1)[0], self.bytes_sent AttributeError: 'NoneType' object has no attribute 'split'解决:是等页面加载完再轮询,当刚开始请求时候刚开始url的tip=1,当status=201的时候tip=0。,这样他就不会不断的轮询,