知识图谱与智能问答基础理解
什么是知识图谱?
知识图谱本质上是语义网络,是一种基于图的数据结构,由节点(Point)和边(Edge)组成。在知识图谱里,每个节点表示现实世界中存在的“实体”,每条边为实体与实体之间的“关系”。知识图谱是关系的最有效的表示方式。通俗地讲,知识图谱就是把所有不同种类的信息(Heterogeneous Information)连接在一起而得到的一个关系网络。知识图谱提供了从“关系”的角度去分析问题的能力。

image.png
知识图谱这个概念最早由Google提出,主要是用来优化现有的搜索引擎。不同于基于关键词搜索的传统搜索引擎,知识图谱可用来更好地查询复杂的关联信息,从语义层面理解用户意图,改进搜索质量。比如在Google的搜索框里输入Bill Gates的时候,搜索结果页面的右侧还会出现Bill Gates相关的信息比如出生年月,家庭情况等等。
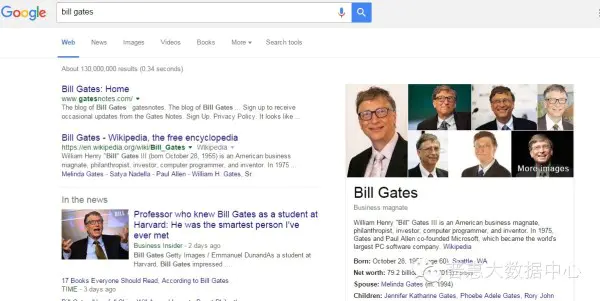
image.png
上面提到的知识图谱都是属于比较宽泛的范畴,在通用领域里解决搜索引擎优化和问答系统(Question-Answering)等方面的问题。接下来我们看一下特定领域里的 (Domain-Specific) 知识图谱表示方式和应用,这也是工业界比较关心的话题。
知识图谱的表示
假设我们用知识图谱来描述一个事实(Fact) - “张三是李四的父亲”。这里的实体是张三和李四,关系是“父亲”(is_father_of)。当然,张三和李四也可能会跟其他人存在着某种类型的关系(暂时不考虑)。当我们把电话号码也作为节点加入到知识图谱以后(电话号码也是实体),人和电话之间也可以定义一种关系叫 has_phone,就是说某个电话号码是属于某个人。下面的图就展示了这两种不同的关系。
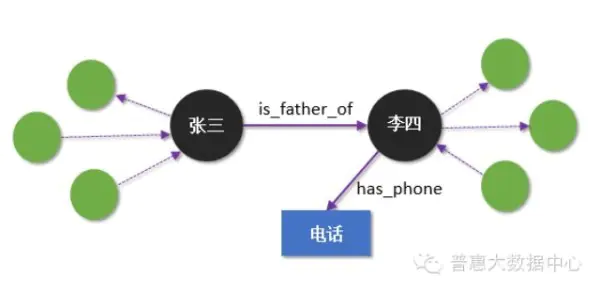
image.png
另外,我们可以把时间作为属性(Property)添加到 has_phone 关系里来表示开通电话号码的时间。这种属性不仅可以加到关系里,还可以加到实体当中,当我们把所有这些信息作为关系或者实体的属性添加后,所得到的图谱称之为属性图 (Property Graph)。属性图和传统的RDF格式都可以作为知识图谱的表示和存储方式,但二者还是有区别的,这将在后面章节做简单说明。
知识图谱的存储
知识图谱是基于图的数据结构,它的存储方式主要有两种形式:RDF存储格式和图数据库(Graph Database)。至于它们有哪些区别,请参考【1】。下面的曲线表示各种数据存储类型在最近几年的发展情况。从这里我们可以明显地看到基于图的存储方式在整个数据库存储领域的飞速发展。
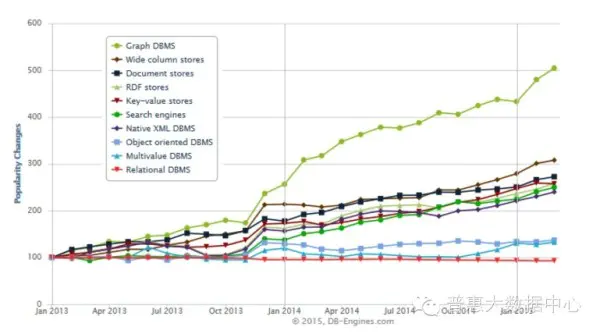
image.png
下面的列表表示的是目前比较流行的基于图存储的数据库排名。从这个排名中可以看出neo4j在整个图存储领域里占据着NO.1的地位,而且在RDF领域里Jena还是目前为止最为流行的存储框架。
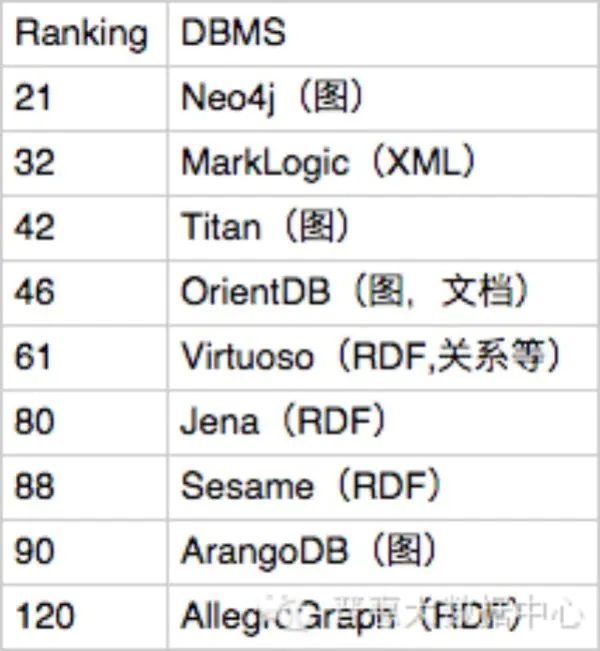
image.png
当然,如果需要设计的知识图谱非常简单,而且查询也不会涉及到1度以上的关联查询,我们也可以选择用关系型数据存储格式来保存知识图谱。但对那些稍微复杂的关系网络(现实生活中的实体和关系普遍都比较复杂),知识图谱的优点还是非常明显的。首先,在关联查询的效率上会比传统的存储方式有显著的提高。当我们涉及到2,3度的关联查询,基于知识图谱的查询效率会高出几千倍甚至几百万倍。其次,基于图的存储在设计上会非常灵活,一般只需要局部的改动即可。比如我们有一个新的数据源,我们只需要在已有的图谱上插入就可以。于此相反,关系型存储方式灵活性方面比较差,它所有的Schema都是提前定义好的,如果后续要改变,它的代价是非常高的。最后,把实体和关系存储在图数据结构是一种符合整个故事逻辑的最好的方式。
什么是知识库
“奥巴马出生在火奴鲁鲁。”
“姚明是中国人。”
“谢霆锋的爸爸是谢贤。”
这些就是一条条知识,而把大量的知识汇聚起来就成为了知识库。我们可以在wiki百科,百度百科等百科全书查阅到大量的知识。然而,这些百科全书的知识组建形式是非结构化的自然语言,这样的组织方式很适合人们阅读但并不适合计算机去处理。为了方便计算机的处理和理解,我们需要更加形式化、简洁化的方式去表示知识,那就是三元组(triple)。
“奥巴马出生在火奴鲁鲁。” 可以用三元组表示为 (BarackObama, PlaceOfBirth, Honolulu)。
这里我们可以简单的把三元组理解为 (实体entity,实体关系relation,实体entity),进一步的,如果我们把实体看作是结点,把实体关系(包括属性,类别等等)看作是一条边,那么包含了大量三元组的知识库就成为了一个庞大的知识图。
知识库可以分为两种类型,一种是以Freebase,Yago2为代表的Curated KBs,它们从维基百科和WordNet等知识库中抽取大量的实体及实体关系,可以把它们理解为是一种结构化的维基百科,被google收购的Freebase中包含了上千万个实体,共计19亿条triple。
值得一提的是,有时候会把一些实体称为topic,如Justin Bieber。实体关系也可分为两种,一种是属性property,一种是关系relation。如下图所示,属性和关系的最大区别在于,属性所在的三元组对应的两个实体,常常是一个topic和一个字符串,如属性Type/Gender,对应的三元组(Justin Bieber, Type, Person),而关系所在的三元组所对应的两个实体,常常是两个topic。如关系Place_of_Brith,对应的三元组(Justin Bieber, Place_of_brith,London)。
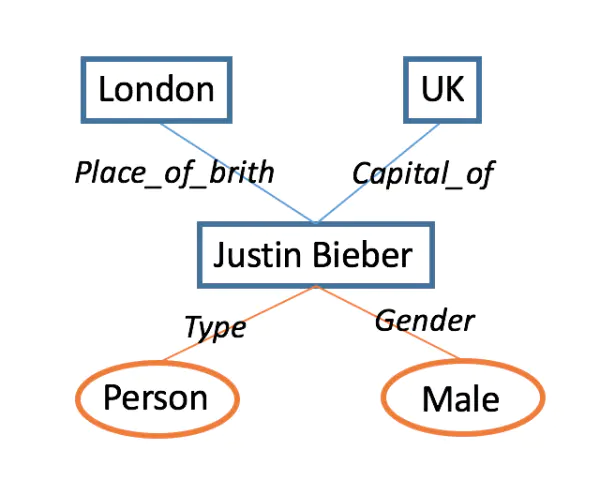
image.png
(图中蓝色方块表示topic,橙色椭圆包括属性值,它们都属于知识库的实体,蓝色直线表示关系,橙色直线表示属性,它们都统称为知识库的实体关系,都可以用三元组刻画实体关系和实体)
但是,像维基百科这样的知识库,与整个互联网相比,仍只能算沧海一粟。知识库的另外一种类型,则是以Open Information Extraction (Open IE), Never-Ending Language Learning (NELL) 为代表的Extracted KBs,它们直接从上亿个网页中抽取实体关系三元组。与Freebase相比,这样得到的知识更加具有多样性,而它们的实体关系和实体更多的则是自然语言的形式,如“奥巴马出生在火奴鲁鲁。” 可以被表示为(“Obama”, “was also born in”, “* Honolulu”),*当然,直接从网页中抽取出来的知识,也会存在一定的noisy,其精确度要低于Curated KBs。
Extracted KBs 知识库涉及到的两大关键技术是:
- 实体链指(Entity linking) ,即将文档中的实体名字链接到知识库中特定的实体上。它主要涉及自然语言处理领域的两个经典问题实体识别 (Entity Recognition) 与实体消歧 (Entity Disambiguation),简单地来说,就是要从文档中识别出人名、地名、机构名、电影等命名实体。并且,在不同环境下同一实体名称可能存在歧义,如苹果,我们需要根据上下文环境进行消歧。
- 关系抽取 (Relation extraction),即将文档中的实体关系抽取出来,主要涉及到的技术有词性标注 (Part-of-Speech tagging, POS),语法分析,依存关系树 (dependency tree) 以及构建SVM、最大熵模型等分类器进行关系分类等。
什么是知识库问答
知识库问答(knowledge base question answering,KB-QA)即给定自然语言问题,通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案。如下图所示:
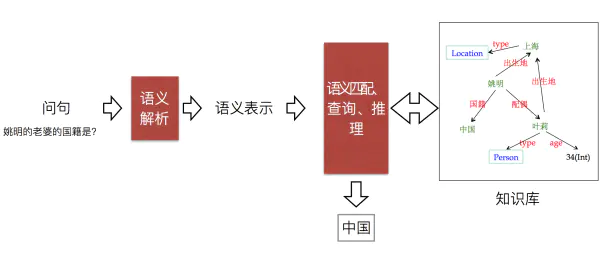
image.png
与对话系统、对话机器人的交互式对话不同,KB-QA具有以下特点:
- 答案:回答的答案是知识库中的实体或实体关系,或者no-answer(即该问题在KB中找不到答案),当然这里答案不一定唯一,比如 中国的城市有哪些 。而对话系统则回复的是自然语言句子,有时甚至需要考虑上下文语境。
- 评价标准:召回率 (Recall),精确率 (Precision) ,F1-Score。而对话系统的评价标准以人工评价为主,以及BLEU和Perplexity。
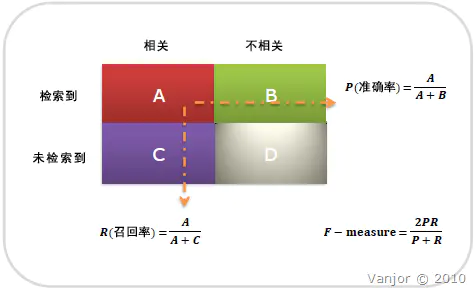
image.png
知识库问答的主流方法
- 语义解析(Semantic Parsing):该方法是一种偏linguistic的方法,主体思想是将自然语言转化为一系列形式化的逻辑形式(logic form),通过对逻辑形式进行自底向上的解析,得到一种可以表达整个问题语义的逻辑形式,通过相应的查询语句(类似lambda-Caculus)在知识库中进行查询,从而得出答案。下图红色部分即逻辑形式,绿色部分where was Obama born 为自然语言问题,蓝色部分为语义解析进行的相关操作,而形成的语义解析树的根节点则是最终的语义解析结果,可以通过查询语句直接在知识库中查询最终答案。
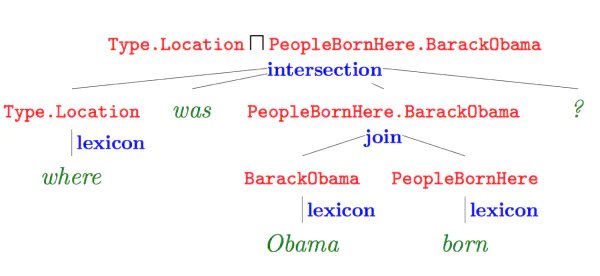
image.png
-
信息抽取(Information Extraction):该类方法通过提取问题中的实体,通过在知识库中查询该实体可以得到以该实体节点为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案,通过观察问题依据某些规则或模板进行信息抽取,得到问题特征向量,建立分类器通过输入问题特征向量对候选答案进行筛选,从而得出最终答案。
-
向量建模(Vector Modeling): 该方法思想和信息抽取的思想比较接近,根据问题得出候选答案,把问题和候选答案都映射为分布式表达(Distributed Embedding),通过训练数据对该分布式表达进行训练,使得问题和正确答案的向量表达的得分(通常以点乘为形式)尽量高,如下图所示。模型训练完成后则可根据候选答案的向量表达和问题表达的得分进行筛选,得出最终答案。
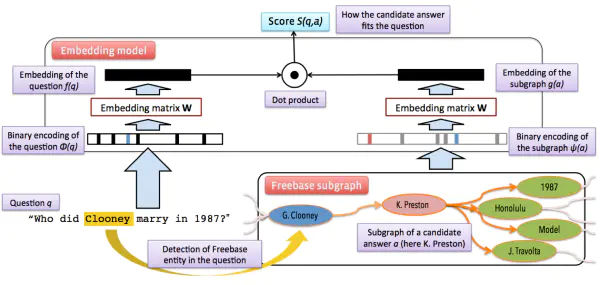
image.png
随着深度学习(Deep Learning)在自然语言处理领域的飞速发展,从15年开始,开始涌现出一系列基于深度学习的KB-QA文章,通过深度学习对传统的方法进行提升,取得了较好的效果,比如:
使用卷积神经网络对向量建模方法进行提升:
Dong L, Wei F, Zhou M, et al. Question Answering over Freebase with Multi-Column Convolutional Neural Networks[C]//ACL (1). 2015: 260-269.
使用卷积神经网络对语义解析方法进行提升:
Yih S W, Chang M W, He X, et al. Semantic parsing via staged query graph generation: Question answering with knowledge base[J]. 2015.
(注 该paper来自微软,是ACL 2015年的Outstanding paper,也是目前KB-QA效果最好的paper之一)
使用长短时记忆网络(Long Short-Term Memory,LSTM),卷积神经网络(Convolutional Neural Networks,CNNs)进行实体关系分类:
Xu Y, Mou L, Li G, et al. Classifying Relations via Long Short Term Memory Networks along Shortest Dependency Paths[C]//EMNLP. 2015: 1785-1794.
Zeng D, Liu K, Lai S, et al. Relation Classification via Convolutional Deep Neural Network[C]//COLING. 2014: 2335-2344.(Best paper)
Zeng D, Liu K, Chen Y, et al. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks[C]//EMNLP. 2015: 1753-1762.
使用记忆网络(Memory Networks),注意力机制(Attention Mechanism)进行KB-QA:
Bordes A, Usunier N, Chopra S, et al. Large-scale simple question answering with memory networks[J]. arXiv preprint arXiv:1506.02075, 2015.
Zhang Y, Liu K, He S, et al. Question Answering over Knowledge Base with Neural Attention Combining Global Knowledge Information[J]. arXiv preprint arXiv:1606.00979, 2016.
以上论文几乎都使用了Freebase作为knowledge base,并且在WebQuestion数据集上进行过测试,这里给出各种方法的效果对比图,给大家一个更加直观的感受。

image.png
知识库问答的数据集
最后,我们再简单地介绍一下KB-QA问题的Benchmark数据集——WebQuestion。
该数据集由Berant J, Chou A, Frostig R, et al.在13年的论文Semantic Parsing on Freebase from Question-Answer Pairs中公开。
作者首先使用Google Suggest API获取以wh-word(what,who,why,where,whose...)为开头且只包含一个实体的问题,以“where was Barack Obama born?”作为问题图谱的起始节点,以Google Suggest API给出的建议作为新的问题,通过宽度优先搜索获取问题。具体来讲,对于每一个队列中的问题,通过对它删去实体,删去实体之前的短语,删去实体之后的短语形成3个新的query,将这三个新query放到google suggest中,每个query将生成5个候选问题,加入搜索队列,直到1M个问题被访问完。如下图所示:
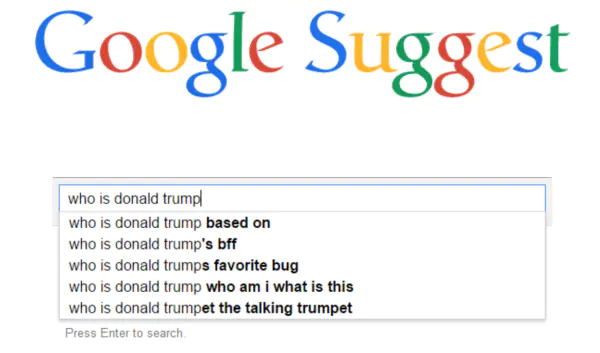
image.png
获取完问题后,随机选取100K个问题交给Amazon Mechanical Turk (AMT)的工人,让工人回答答案。注意,这里对答案进行了限制,让AMT的工人只能把答案设置为Freebase上的实体(entity),实体列表,值(value)或者no-answer。
最终,得到了5,810组问题答案对,其词汇表包含了4,525个词。并且,WebQuestion还提供了每个答案对应知识库的主题节点(topic node)。
可以看出WebQuestion的问题与freebase是不相关的,更加偏向自然语言,也更多样化。这里给出一些例子
“What is James Madison most famous for?”
“What movies does Taylor Lautner play in?”
“What music did Beethoven compose?”
“What kind of system of government does the United States have?”
除了该数据集,这里再补充一些其他数据集的信息,如下图所示:
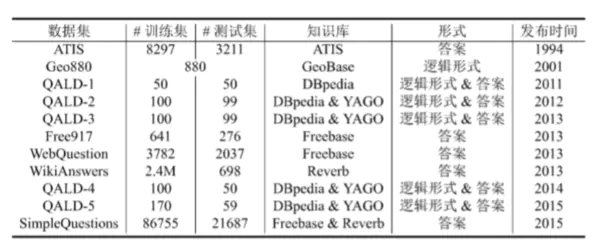
image.png
附: 知识图谱从0级到10级简化版 (For Developer)
0级:掌握正则表达式、SQL、JSON和一门支持if-then-else的高级语言 —— 是的,这些不是知识图谱技术,但是这些可以解决问题。我们要的是解决问题,不是吗?
1级:学会ER建模(对,就是数据库里的ER建模),理解实体(Entity)和关系(Relation)的概念。这个可能比你想象得难很多。学会更复杂的SQL,能熟练掌握至少一种主流的关系数据库,至少学会一种语言的数据库操作。
2级:学会两种给实体命名的方法:数据库里的主键,Web上的URI。理解分类树。这时候可以学下RDF了,掌握Turtle和JSON-LD两种语法。会用Java或者Python操作RDF。(小白一般到这里就开始大批阵亡)
3级:如果还未阵亡,可能发现RDF数据库不是太好用,需要学会一个图数据库(如Neo4j或OrientDB)或者支持JSON的关系数据库(如PostgreSQL)。学会用这些数据库表达关系-实体,和表达分类树。这可以保证以后可以活得再久一点。
4级:这时候作为一名老兵,你可能已经学会了查询语言SPARQL、Cypher或Gremlin。然后你发现查询语言可以用来写!规!则!天啊,天堂的大门已经打开了。
5级:你会发现把智能放在数据里要远远好于放在代码里。你会开始鄙视在代码里写大量if-then-else的伪知识图谱爱好者。而且你开始不满足用查询语言客串规则(如用SPIN)。你需要一些真正的推理规则。你开始对OWL感兴趣……然后彻底被搞晕了。
6级:你发现OWL很强大但是也很难理解,它背后的描述逻辑如同三体人一样充满敌意。然后你发现其实if-then-else也蛮不错的,而且有一个更容易理解的规则语言:logic program。然后你突然发现SQL其实就是一种LP啊(Datalog)!突然一下世界豁然开朗,喜悦充满全身,圣洁的阳光从天上映下。
7级:在各种奇怪的规则语言中游弋:RIF-BLD,RIF-PRD,SWRL,RuleML,JESS,DLV,XSB,Prolog。发现世界的各种东西都可以按此建模。理解各种推理机的性能。谙熟各种知识建模套路。
8级:从头到尾设计过一个完整的语义或知识应用,经历落地过程种种工程的巨大陷阱,入坑、爬出来,再入坑、再爬出来,再再入坑……直到爬不出来。
9级:开始思考人性问题。从认知的角度、社会的角度、组织的角度、经济的角度思考什么是知识,怎么才能真正实施知识系统。
10级:综合运用正则表达式、SQL、JSON和一门支持if-then-else的高级语言 ,举重若轻解决以上1-9级中遇到的的各种问题。其实你设计出了自己的知识表现语言。
作者:郭少悲
链接:https://www.jianshu.com/p/9a68a9f98e12
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。