Yoshua Bengio等图神经网络的新基准Benchmarking Graph Neural Networks(代码已开源)
最近GNN备受关注,相信大家也都能感受到。但是,一旦我们开始阅读相关论文,开展相关的实验时,会发现一些问题。
我们一般会从节点分类数据集cora, citeseer, pubmed,图分类数据集PROTEINS, NCI1, NCI109等入手,这些数据集相对都比较小,数据集小不是什么问题,问题是当我们复现已提出的相关模型并进行训练和测试时,发现这些模型并没有太大的差别,换句话说有些模型是150分的水平,有模型是98分的水平,放在100分的卷子里面,都是优秀的模型;再者说我们用微积分(复杂的模型)虽然也能解决三角形面积问题,但是显得过于复杂,那么让微积分解决曲面面积(较复杂的网络)优势就突出来了。除了数据集,我们再来看看实验,在一些论文里面,实验的数据的分割方式很独特,训练方式,超参数,损失函数,学习率的变化等与对比基准模型完全不同,或者没有提到,看到源码时采发现,但是作者们竟然直接比较了起来,然后还发表了。。。总结一下大概有两点:目前存在的问题有数据集小,模型表现差异性小;实验对比不规范。
今天介绍的这篇论文题目为Benchmarking Graph Neural Networks ,在2020年3月2日由 Vijay Prakash Dwivedi,Chaitanya K. Joshi, Thomas Laurent,Yoshua Bengio, Xavier Bresson等人发布在arxiv上。

下面先看看摘要
摘要:图神经网络(GNN)已成为分析和学习图数据的标准工具包。它们已成功应用于很多领域,包括化学,物理,社会科学,知识图谱,推荐系统和神经科学。随着领域的发展,识别跨图大小通用的体系结构和机制变得至关重要,这使我们能够处理更大,更复杂的数据集和领域。不幸的是,在缺乏统一的实验设置和大型数据集的情况下,衡量新GNN的有效性和比较模型的难度越来越大。在本文中,我们提出了一个可复现的GNN基准框架,为研究人员提供了添加新数据集和模型的便利。我们将此基准框架应用于数学建模,计算机视觉,化学和组合问题等新颖的中型图形数据集,以在设计有效的GNN时建立关键操作。精确地,图卷积,各向异性扩散,残差连接和规范化层是用于开发健壮且可扩展的GNN的通用构件。
本文主要的贡献:
1.用PyTorch和DGL在GitHub上发布了一个基线框架,简单容易上手,链接:https://github.com/graphdeeplearning/benchmarking-gnns

或者扫描二维码,下面阅读原文也可以打开;
2.提出了一系列中等规模的数据集,包括数学建模,计算机视觉,组合优化,化学等领域;
3.确定了GNN关键部件的有效性,如异性扩散,残差连接,正则化等;
4.论文没有对已有的模型进行ranking,而是固定参数来确定GNN重要的机制;
5.好安装,易上手,可复现。
数据集
首先,我们看看公布的数据集,有以下6个数据集:
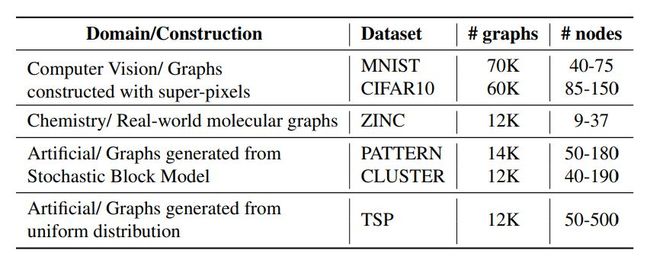
以上数据集分别是MNIST, CIFAR10,ZINC,PATTERN and CLUSTER , TSP,进行的任务是依次分类(acc),回归(溶解度性能指标预测, MAE),节点分类(acc),边分类(acc)
本文的主要动机是提出足够大的数据集,以便在各种GNN架构之间观察到差异。尽管小型数据集对于快速发展新想法很有用,但从长远来看,它们会限制GNN模型的发展,因为新的GNN模型会按照小型测试集进行设计,而不是寻找更通用的体系结构。 另外,普遍采用的CORA和TU数据集的另一个问题是缺乏实验结果的可重复性。大多数发表的论文没有使用相同的trainvalidation-test拆分。此外,即使对于相同的分割,由于数据集太小,GNN的性能在常规的10倍交叉验证中也表现出较大的标准偏差。本文提出的每个数据集都包含至少12 000个图,规模中等。
本文进行实验的模型有MLP, GCN, GAT, GaphSAGE, DiffPool, GIN, MoNet-Gaussian Mixture Model, GatedGCN等。验证了残差连接,Batch Normalization, Graph Size Normalization等模块的作用。
实验
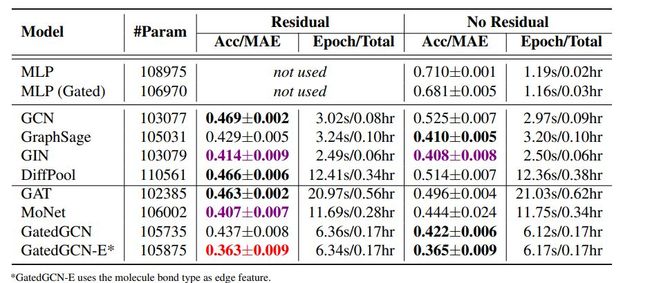
作者首先用以上模型在之前的图分类数据集上进行了实验,红蓝黑加粗的颜色分别代表第一,第二,第三的表现。
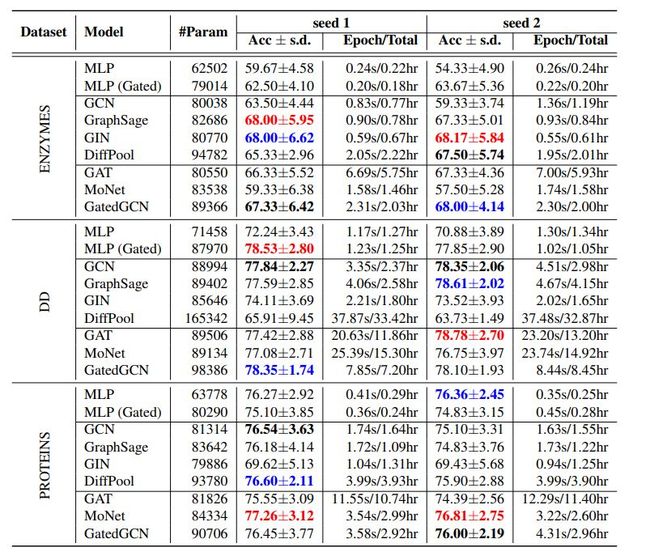
可以看出来,上面的结果标准偏差相当大,因为数据量小,按照交叉验证的思路,不同的分割方式会导致实验结果有很大的不同,这侧面反应了所有GNN的统计性能相似。另外,作者还报告了这些实验的第二次运行结果,采用相同的10倍拆分,但是不同的初始化方式,结果有较大的变化。这都可以归因于数据集的尺寸小和梯度下降优化器的不确定。还可以观察到,对于DD和Proteins数据集,MLP基线有时甚至比GNN还要好.
接着,作者在自己提出的数据集上一一进行了实验
SuperPixel数据集的图形分类
原始MNIST和CIFAR10图像使用超像素转换为Graph,超像素代表图像中强度均匀的小区域,可以使用SLIC技术提取,下面是提取的结果:
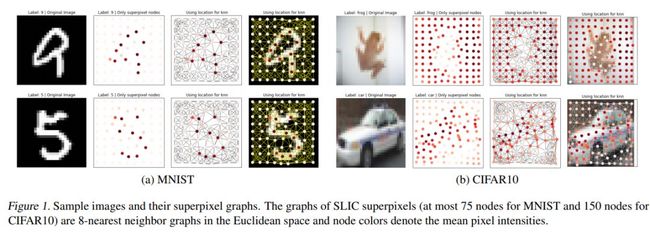
很多同学都很好奇,连接矩阵怎么来?这个其实也简单,主要你要想明白要定义的关系是怎么样的

文中采取的方式是采样k个最邻近的点,用上面的公式W来计算,可以看做是距离的度量,当然也可以有不同的定义方式,参考昨天的推送。其他的数据集参考论文细节,这里就不再一一展开了...
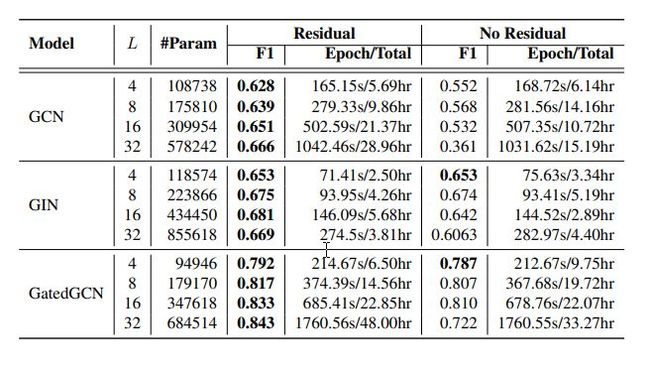
下面是部分实验结果
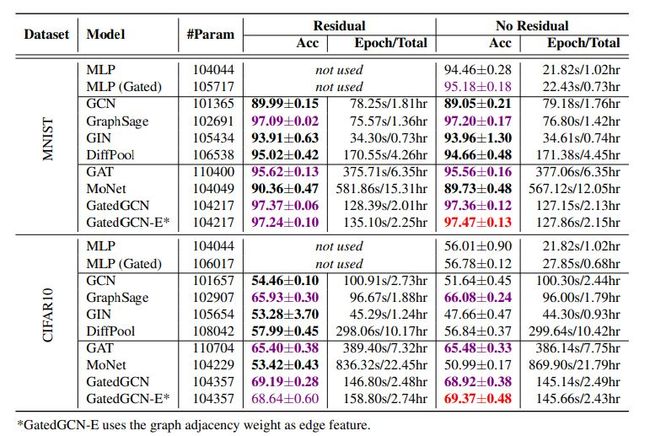
关于颜色Red: the best model, Violet: good models. Bold indicates the best model between residual and non-residual connections (both models are bold if they perform equally。
TSP数据集边分类
近年来,利用机器学习来解决NP-hard组合优化问题(COP)一直是研究的重点。最近提出的基于COP的基于深度学习的求解器将GNN与经典图搜索相结合,可直接从问题实例(表示为图)中预测近似解。考虑深入研究的旅行推销员问题(TSP):给定2D欧几里得图,就需要找到具有最小总边沿权重(旅行长度)的最优节点序列(称为旅行)。TSP的多尺度性质使其成为一项具有挑战性的图形任务,需要对本地节点邻域以及全局图形结构进行推理。为了从搜索组件中分离出GNN架构的影响,作者将TSP设置为二分类任务,with the groundtruth value for each edge belonging to the TSP tour given by Concord.

更多的实验请参考论文细节
本文的想要告诉我们什么?
与图形无关的NN(MLP)在小型数据集上的表现与GNN相同
对于较大的数据集,GNN改进了与图无关的NN
最简单形式的GNN表现较差
各向同性GNN架构在原始GCN上有所改进。GraphSage证明了在图卷积层中使用中心节点信息的重要性。GIN采用了中心节点特征以及一个新的分类器层,该分类器层在所有中间层均与卷积特征相连。DiffPool考虑了一种可学习的图形池化操作,其中在每个分辨率级别使用GraphSage。除CLUSTER外,这三个各向同性的GNN可以显着提高所有数据集的GCN性能。
各向异性的GNN是有效的。除了PATTERN以外,各向异性模型,例如GAT,MoNet和GatedGCN均能获得最佳结果。另外,注意到,GatedGCN在所有数据集上的性能始终都很好。注:各向同性的GNN大多依赖于相邻特征的简单总和,各向异性的GNN采用复杂的机制(GAT的稀疏关注机制,GatedGCN的边缘门)。
残差连接能够提升模型的性能
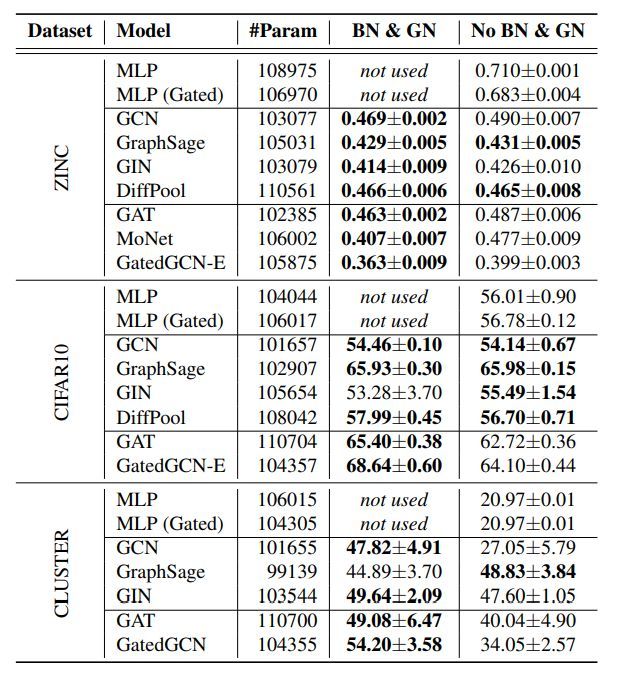
正则化能够提升模型的性能
结论
在本文中,作者提出了一个基准框架,以促进图神经网络的研究,并解决文献中的实验不一致问题。论文确认目前普遍使用的小型TU数据集不适合研究该领域模型,并在框架内引入六个中等规模的数据集。对图形的多个任务进行的实验表明:i)随着转向更大的数据集,图形结构非常重要;ii)GCN是GNN的最简单的各向同性版本,无法学习复杂的图结构;iii)自节点信息,层次结构,注意力机制,边缘门和更好的读出功能是改善GCN的关键结构;iv)GNN可以使用残差连接来更深地扩展,并且可以使用归一化层来提高性能。最后一点,基准测试基础架构利用PyTorch和DGL,是完全可复现的,并向GitHub上的用户开放,供大家尝试新模型并添加数据集。

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习在线手册深度学习在线手册AI基础下载(pdf更新到25集)本站qq群1003271085,加入微信群请回复“加群”获取一折本站知识星球优惠券,请回复“知识星球”喜欢文章,点个在看
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习在线手册深度学习在线手册AI基础下载(pdf更新到25集)本站qq群1003271085,加入微信群请回复“加群”获取一折本站知识星球优惠券,请回复“知识星球”喜欢文章,点个在看