oschina openapi 应用:博客搬家
http://my.oschina.net/oscfox/blog/194507
本文介绍基于osc openapi 以及 webmagic爬虫 开发的oschina博客搬家应用。 本应用作为oschina openAPI的一个实用demo,向各位OSCer 展示OSC openAPI 如何使用,以及可以实现什么功能。
oschina openapi 博客搬家 webmagic git
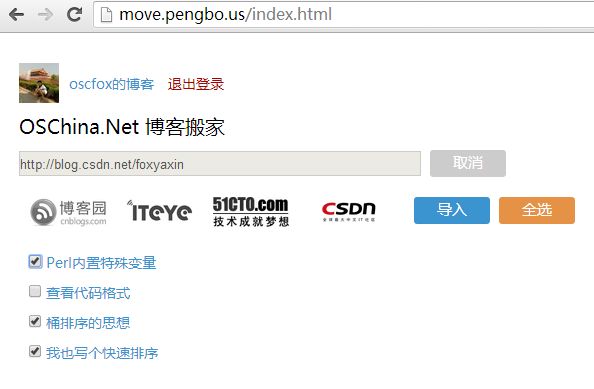
一、功能说明:本程序支持将csdn ,cnblogs, 51cto, iteye个人博客列表下载所有博文,选择导入到该用户的oschina博客。
二、使用说明:
1.进入博客搬家页面:http://move.oschina.net
2.点击左上角使用oschina账号登陆,
3.输入csdn或cnblogs或51cto或iteye个人博客列表url或者某篇博客url,
4.点击抓取,
5.点击导入。


三、如何实现:
本程序不用数据库,只用一个Map存储用户爬取的博客信息。爬虫用git.oschina上的开源垂直爬虫:webmagic 感谢黄亿华 。登陆用oschina的openAPI认证功能。
1.存储
博客链接:
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
/**
* 爬虫获取的博客列表
* @author oscfox
*
*/
public
class
LinksList {
//用户名,对应一个用户列表,如果用户为新用户则put新的列表
private
static
Map
new
ConcurrentHashMap
public
static
void
addLinks(String user, List
ConcurrentHashMap
if
(linkMap.containsKey(user)){
linkList= linkMap.get(user);
}
else
{
linkList =
new
ConcurrentHashMap
}
//put links 去重复
for
(
int
i=
0
; i
String key = links.get(i).getLink();
if
(linkList.containsKey(key)){
//重复,不提交
continue
;
}
linkList.put(key, links.get(i));
}
linkMap.put(user, linkList);
}
public
static
void
clearLinkList(String user) {
linkMap.remove(user);
}
public
static
List
ConcurrentHashMap
if
(linkMap.containsKey(user)){
hash = linkMap.get(user);
return
new
ArrayList
//hash to list
}
return
null
;
}
}
|
博客列表:
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
/**
* 爬虫获取的博客列表
* @author oscfox
*
*/
public
class
BlogList {
//用户名,对应一个用户列表,如果用户为新用户则put新的列表
private
static
Map
new
ConcurrentHashMap
public
static
void
addBlog(Blog blog) {
if
(blogMap.containsKey(blog.getLink())){
//已存在博客,有异常,没处理
blogMap.put(blog.getLink(), blog);
}
else
{
blogMap.put(blog.getLink(), blog);
}
}
public
static
Blog getBlog(String link) {
if
(blogMap.containsKey(link)){
return
blogMap.remove(link);
}
return
null
;
}
}
|
2.爬虫
webmagic用起来很方便,我只继承了pageProcessor 接口作为不同博客的抓取逻辑以及Pipeline接口作抓取后续处理。然后以下一行代码就可以开始抓取
|
1
|
Spider.create(pageProcessor).addUrl(url).addPipeline(
new
BlogPipeline(user)).run();
|
继承的pageProcessor主要是重写process 方法,根据不同博客网站标签逻辑抓取内容。然后对博客里有代码的部分(主要是pre标签里的)转换为osc博客的代码类型。方法很简单,只是简单替换一下标签属性而已。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
/**
* 博客爬虫逻辑
* @author oscfox
* @date 20140120
*/
public
class
BlogPageProcessor
implements
PageProcessor{
protected
Site site =
new
Site();
protected
String url;
protected
String blogFlag;
//博客url的内容标志域
protected
String name;
//博客原url 的名字域
protected
List
new
ArrayList
//代码过滤正则表达式
protected
List
new
ArrayList
//代码过滤正则表达式
protected
String linksRex;
//链接列表过滤表达式
protected
String titlesRex;
//title列表过滤表达式
protected
String PagelinksRex;
//类别页列表过滤表达式
protected
String contentRex;
//内容过滤表达式
protected
String titleRex;
//title过滤表达式
protected
String tagsRex;
//tags过滤表达式
protected
Hashtable
//代码class映射关系
/**
* 抓取博客内容等,并将博客内容中有代码的部分转换为oschina博客代码格式
*/
@Override
public
void
process(Page page) {
if
(url.contains(blogFlag)){
getPage(page);
page.putField(
"getlinks"
,
false
);
}
else
{
getLinks(page);
page.putField(
"getlinks"
,
true
);
}
}
/**
* 抓取链接列表
* @param page
*/
private
void
getLinks(Page page) {
List
List
page.putField(
"titles"
, titles);
page.putField(
"links"
, links);
List
page.addTargetRequests(Pagelinks);
}
/**
* 抓取博客内容
* @param page
*/
private
void
getPage(Page page){
String title = page.getHtml().xpath(titleRex).toString();
String content = page.getHtml().$(contentRex).toString();
String tags = page.getHtml().xpath(tagsRex).all().toString();
if
(StringUtils.isBlank(content) || StringUtils.isBlank(title)){
return
;
}
if
(!StringUtils.isBlank(tags)){
tags = tags.substring(tags.indexOf(
"["
)+
1
,tags.indexOf(
"]"
));
}
OscBlogReplacer oscReplacer=
new
OscBlogReplacer(hashtable);
//设置工具类映射关系
String oscContent = oscReplacer.replace(codeBeginRex, codeEndRex, content);
//处理代码格式
page.putField(
"content"
, oscContent);
page.putField(
"title"
, title);
page.putField(
"tags"
, tags);
}
|
例如csdn博客抓取只需要继承BlogPageProcessor
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
/**
* csdn博客爬虫逻辑
* @author oscfox
* @date 20140114
*/
public
class
CsdnBlogPageProcesser
extends
BlogPageProcessor{
public
CsdnBlogPageProcesser(String url) {
site = Site.me().setDomain(
"blog.csdn.net"
);
site.setSleepTime(
1
);
blogFlag=
"/article/details/"
;
//博客原url 的名字域
codeBeginRex.add(
"
);
//代码过滤正则表达式
//
codeBeginRex.add(
"
);
codeEndRex.add(
""
);
//
linksRex=
"//div[@class='list_item article_item']/div[@class='article_title']/h3/span/a/@href"
; //链接列表过滤表达式
titlesRex=
"//div[@class='list_item article_item']/div[@class='article_title']/h3/span/a/text()"
;//title列表过滤表达式
contentRex=
"div.article_content"
;
//内容过滤表达式
titleRex=
"//div[@class='details']/div[@class='article_title']/h3/span/a/text()"
; //title过滤表达式
tagsRex=
"//div[@class='tag2box']/a/text()"
; //tags过滤表达式
this
.url=url;
if
(!url.contains(blogFlag)){
name = url.split(
"/"
)[url.split(
"/"
).length -
1
];
}
//http://blog.csdn.net/cxhzqhzq/article/list/2
PagelinksRex=
"http://blog\\.csdn\\.net/"
+name+
"/article/list/\\d+"
; //类别页列表过滤表达式
initMap();
}
@Override
public
void
process(Page page) {
super
.process(page);
}
@Override
public
Site getSite() {
return
super
.getSite();
}
/**
* 初始化映射关系,只初始化代码类型同样而class属性不一样的。
* 分别为:csdn, osc
*/
private
void
initMap() {
hashtable =
new
Hashtable
//代码class映射关系
hashtable.put(
"csharp"
,
"c#"
);
hashtable.put(
"javascript"
,
"js"
);
hashtable.put(
"objc"
,
"cpp"
);
}
|
Pipeline只是简单的生成blog bean 然后增加至blogList
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
/**
* 成功blog并保存至BlogList
* @author oscfox
* @date
*/
public
class
BlogPipeline
implements
Pipeline{
private
Map
new
HashMap
private
String user;
public
BlogPipeline(String user){
this
.user = user;
}
@SuppressWarnings
(
"unchecked"
)
@Override
public
void
process(ResultItems resultItems, Task task) {
fields = resultItems.getAll();
if
((
boolean
)fields.get(
"getlinks"
)){
List
"titles"
);
List
"links"
);
if
(
null
== titles ||
null
== links){
return
;
}
List
new
ArrayList
for
(
int
i=
0
; i
BlogLink blogLink =
new
BlogLink();
blogLink.setTitle(titles.get(i));
blogLink.setLink(links.get(i));
linklist.add(blogLink);
}
LinksList.addLinks(user, linklist);
}
else
{
Blog oscBlog =
null
;
try
{
oscBlog =
new
Blog(fields);
oscBlog.setLink(resultItems.getRequest().getUrl());
}
catch
(Exception e) {
//e.printStackTrace();
return
;
}
BlogList.addBlog(oscBlog);
List
new
ArrayList
BlogLink blogLink =
new
BlogLink();
blogLink.setLink(oscBlog.getLink());
blogLink.setTitle(oscBlog.getTitle());
links.add(blogLink);
LinksList.addLinks(user, links);
}
}
}
|
所以如果需要抓取更多的博客网站,只需要继承pageProcessor重写process方法就行了。当然,spider选择哪个pageProcessor还得判断一下。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
/**
* //根据url选择博客类型
* @param url
* @return
*/
public
static
PageProcessor getBlogSitePageProcessor(String url){
|