Skyline 监控系统工作原理分析
Skyline 是一个实时的异常监测系统,它被动地接收 metrics 数据,并使用一系列算法自动地判断 metrics 是否异常,此外,用户可以很容易地根据自己应用数据的特点,提供自己的异常检测算法。
概述
Skyline 是一个实时的异常监测系统,它被动地接收 metrics 数据,并使用一系列算法自动地判断 metrics 是否异常,此外,用户可以很容易地根据自己应用数据的特点,提供自己的异常检测算法。Skyline 还提供了一个 web Ui 接口,异常的 metrics 会在 webapp 中得到展示。
Skyline 内部由 3 个组件组成:Horizon/Analyzer/Webapp:

它们的工作方式如下:
Horizon 负责接收外部发送过来的 datapoint 并转发到 Redis,同时从 Redis 中删除过时的 datapoint(所谓 datapoint 是指某个 metric 在一个特定时间点的数据,它包含 timestamp 和 value)。Analyzer 从 Redis 获取 metrics 数据,并使用算法判断是否异常。最后 Webapp 以图表的方式向用户展示异常的 metrics。
Horizon 和 Analyzer 的工作流程如下图所示,红色字体标注的是 settings.py 中定义的配置项:

Horizon
Horizon 是 Skyline 的数据收集器,它由 3 个角色组成:Listener/Worker/Roomba。Horizon 通过 bin/horizon.d 启停。
Listener
Listener 负责接收外部发送过来的数据,每个 Listener 是一个进程,目前会启动两种类型的 Listener:TCP 和 UDP,它们使用的应用层协议不同,且数据的序列化方式也不同。应用向 horizon 发送 metric 数据时是以 tuple 为单位的,一个 tuple 的格式如下所示,表示某个 metric 在某个时刻的值:
tuple == (metric_name, datapoint) == (metric_name, [timestamp,value])
TCP pickle
TCP 类型的 Listener 使用的序列化方式是 cPickle,应用层协议如下:
+----------------------------+-------------------------------------------------------------------------------+ | length(4 bytes) | [ [tuple1,tuple2...(of metric 'A')], [tuple1,tuple2...(of metric 'B')], ...] | +----------------------------+-------------------------------------------------------------------------------+
前 4 个字节是 length,表示后续数据的长度。接下来是一个使用 cPickle 序列化的数组,tuple 根据 metric name 分组,每组是该数组内的一个元素。
UDP messagepack
UDP 类型的 Listener 使用的序列化方式是 msgpack,应用层协议为:
+---------+ | tuple | +---------+
是的,很简单,把 tuple 用 msgpack 序列化后发送即可。因为 UDP 可以保持消息边界的特性,因此不需要 length 字段。
Listener 接收 datapoint 后将其缓存在内部的 Chunk 队列中,其长度由 CHUNK_SIZE 决定;Chunk 满后被放入一个公共的队列 Queue 中,该队列的长度为 MAX_QUEUE_SIZE。
Worker
Worker 负责处理公共队列 Queue 中的 Chunk,Horizon 在启动时会创建 WORKER_PROCESSES 个 worker 进程,不停地从 Queue 中出队 Chunk,将 Chunk 内的 datapoint 经 msgpack 序列化后,按其所属的 metric 添加到对应的 Redis 队列中。
Skyline 在 Redis 中定义了两个 namespace:FULL_NAMESPACE 和 MINI_NAMESPACE,MINI 的作用稍微次要一点,我们先忽略它,后面提及 Roomba 时再讲解。两个 namespace 下的结构都是一致的:
-
FULL_NAMESPACE + ${metric name} ==> List [ datapoint1,datapoint2,datapoint3 … ] (timeseries)
每个 metric 都有一个 List 保存着它所对应的 datapoint 集合,这个 List 在 Skyline 中又被称为 timeseries,它保存着该 metric 在一段时间内的取值序列。
-
FULL_NAMESPACE + ‘unique_metrics’ ==> Set [metric name 1, metric name 2, …]
该 Set 保存着所有 metric 的名字以便快速查找。
Worker 根据 Chunk 内 tuple 所携带的 metric name 信息,将 datapoint 发送到 Redis 的两个 namespace 中以供 Analyzer 模块分析。
Roomba
Roomba 负责清除 Redis 各 timeseries 中过时的 datapoint,只留下最近某段时间内的 datapoint,保证 Redis 不爆掉。Horizon 启动时会启动 Roomba 线程(Roomba 和 Worker 不太一样,它是继承 Thread 的,虽然它的实际工作都是靠创建的进程完成的),对 FULL 和 MINI 两个 namespace 分别创建 ROOMBA_PROCESSES 个进程,从 FULL/MINI_NAMESPACE + ‘unique_metrics’ 中找到所有的 metrics 并均匀地分配给每个进程处理。后者对每个分配的 timeseries,删除距当前 FULL/MINI_DURATION + ROOMBA_GRACE_TIME 秒前的 datapoint;如果整个 timeseries 都过时了,则该 metric 的 List 会从 Redis 中删除,同时 metric name 也会从 set 中删除。
所有进程都退出后,Roomba 线程继续循环,即将进行下一轮进程的创建。为了防止 Redis 中数据很少时,进程快速的创建和退出带来的性能消耗,每个进程在退出时都会判断运行的时间,如果小于 30s,则休眠 10s。
因此,Roomba 的工作其实就是保证 Redis 两个 namespace 下各个 timeseries 始终是 “最近的” 一段数据,其时间跨度由 FULL_DURATION/MINI_DURATION(以及 ROOMBA_GRACE_TIME)指定。FULL 命名空间下的 timeseries 是 Analyzer 分析的对象,MINI 下的并不会被分析,它的作用只在于在 web UI 中为用户提供某个 metric 最近一个小时间段(MINI_DURATION)内的概览。此外,MINI namespace 还用于和 Oculus 配合工作,Oculus 是 Esty 公司出品的另一个系统,我们这里忽略掉。
Analyzer

经过 Horizon 的处理,Redis 中已经保存了若干 timeseries,Analyzer 负责对其进行分析,同时提供了一系列算法判断 timeseries 是否异常的(anomalous)。
Analyzer
Analyzer 也是一个线程,它的工作方式和 Roomba 几乎一致,启动后创建 ANALYZER_PROCESSES 个进程,平均分配 FULL_NAMESPACE 下的所有 timeseries,每个 timeseries 被送入 Algorithms 模块处理,判断是否异常并返回异常的 datapoint、报告异常的算法。
所有进程分析完毕后,Analyzer 将异常 metrics 的相关信息 dump 到 webapp 的 anomalies.json 文件中,随后 webapp 将会通过 JSONP 请求该文件,得到异常信息并展示。此外,Analyzer 还将根据配置的 Email 信息发送预警邮件。
最后,Analyzer 线程判断整个分析过程耗时,如果 < 5s,则休眠 10s,醒后重新进入下一轮进程创建。这里和 Roomba 有点差别,Roomba 的休眠由各个进程判断,而这里是由 Analyzer 线程进行。
Algorithms
这里是判断异常的核心所在,Skyline 内置了 9 个算法来判断一个 datapoint 序列是否异常,用户可以根据自己应用的特征配置要使用的算法(ALGORITHMS 配置项),或者自定义自己的判定算法。
run_selected_algorithm(timeseries) 方法中,timeseries 首先会经过一系列合法性验证:
- datapoint 数目太少(< MIN_TOLERABLE_LENGTH):TooShort 异常
- 过时(最后一个 datapoint 在 STALE_PERIOD 秒前):Stable 异常
- 时间跨度太短(两端 datapoint 时间之差 < FULL_DURATION):Incomplete 异常
- 重复数据太多(最后 MAX_TOLERABLE_BOREDOM 个 datapoint 都是一个值):Boring 异常
验证后将 timeseries 送入所选算法中进行异常判断。每个算法都会返回 Boolean 值,true 表示异常,false 表示正常。当有 > CONSENSUS 个算法判断为异常时,该 timeseries 才会被认为是 anomalous 的。最终返回 3 个值:是否异常 | 判定为异常的算法集合 | 异常 datapoint,异常 datapoint 目前统一为序列最后 3 个 datapoint 的平均值,这和判断异常的算法是相关的,关于 Skyline 内置的 9 个算法的分析参见这里。
Webapp
Webapp 基于 Flask 框架提供异常 metrics 的图表展现,是一个比较简单的模块,就不展开了。基本原理是向后台轮询 anomalies.json,得到异常的 metrics 名称及对应的异常 datapoint,之后根据 metrics name 向后台请求 Redis 中的 timeseries 序列(包括 FULL/MINI namespace),并用图表展示出来。借用官网的一张图:
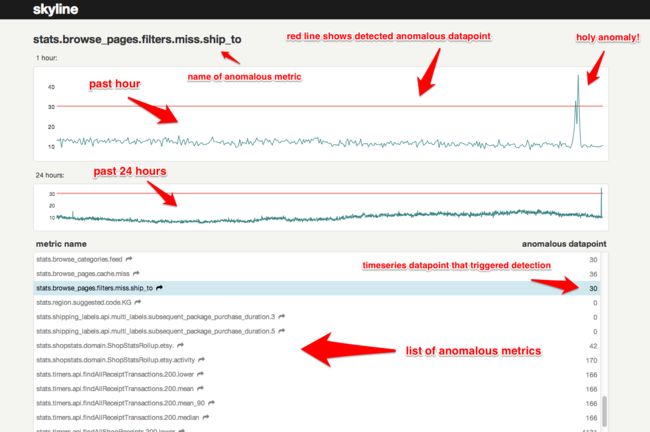
需要一提的是,图中所示 1 hour 和 24 hour 下的图表,分别是从 MINI 和 FULL NAMESPACE 中取得的 timeseries 数据,它们的时间跨度分别由参数 MINI_DURATION 和 FULL_DURATION 决定,并非固定的 1 小时或 24 小时,只不过页面上是这么写死的。
问题
-
Roomba 对同一 timeseries 两次 trim 的时间间隔在 10s 以上,Analyzer 是 5s 以上,如果 FULL_DURATION 过短(比如几秒),则两次 analysis 之间的 Roomba 过程可能将第一次分析后加入的新 datapoint 删除,当两次 analysis 的间隔 > FULL_DURATION 时就有可能会发生这种情况。因此使用 Skyline 时不能将分析的单位时间跨度 FULL_DURATION 设置的过短;同时选择的算法不宜过多太复杂,否则一次 analysis 的耗时比 FULLL_DURATION 还高,就有可能出现上述问题。
-
现在大部分的异常判定算法都是取 timeseries 的最后 3 个 datapoint 和整体序列进行比较,如果某些 metrics 的发送频率较快,在两次 analysis 的间隔(不考虑算法的运行时间的话 5s-15s)内发送了多于 3 个的 datapoint,这样,在第二次 analysis 时,就会忽略掉 N-3 个数据,假如异常刚好发生在倒数第 4 个 datapoint 处,则检测不到。因此 metrics 发送的频率(resolution)也不宜过高。
我在 Skyline 的 group 里向作者提到了这两个疑问,作者的回答是:
- 第一种情况不太可能出现,因为实际中 Analyzer 的耗时大概在一两分钟,远低于通常设置的 FULL_DURATION;
- 的确会有这样的情况,Analyzer 需要重写以便分析这段时间内所有加入的 datapoint,而不仅仅是最后 3 个。
总结
本文大致分析了 Skyline 的各个角色和工作原理,总的来说,Skyline 是一个简单精巧的监控工具,但从代码来看有些地方的处理方式不太一致,在调试的过程中发现了一个比较明显的 bug(不过作者的反应很快),给人的感觉不太严谨;其他的问题还有待于实际应用中发现。最后,Skyline 的规模对 Python 的初学者是个很好的源码阅读教材~
全文完
概述HorizonListenerTCP pickleUDP messagepackWorkerRoombaAnalyzerAnalyzerAlgorithmsWebapp问题总结