
示例代码托管在:http://www.github.com/dashnowords/blogs
博客园地址:《大史住在大前端》原创博文目录
- 一. 上手TensorFlow.js
- 二. 使用TensorFlow.js构建卷积神经网络
- 卷积神经网络
- 搭建LeNet-5模型
- 三. 基于迁移学习的语音指令识别
- 推荐课程

TensorFlow是Google推出的开源机器学习框架,并针对浏览器、移动端、IOT设备及大型生产环境均提供了相应的扩展解决方案,TensorFlow.js就是JavaScript语言版本的扩展,在它的支持下,前端开发者就可以直接在浏览器环境中来实现深度学习的功能,尝试过配置环境的读者都知道这意味着什么。浏览器环境在构建交互型应用方面有着天然优势,而端侧机器学习不仅可以分担部分云端的计算压力,也具有更好的隐私性,同时还可以借助Node.js在服务端继续使用JavaScript进行开发,这对于前端开发者而言非常友好。除了提供统一风格的术语和API,TensorFlow的不同扩展版本之间还可以通过迁移学习来实现模型的复用(许多知名的深度学习模型都可以找到python版本的源代码),或者在预训练模型的基础上来定制自己的深度神经网络,为了能够让开发者尽快熟悉相关知识,TensorFlow官方网站还提供了一系列有关JavaScript版本的教程、使用指南以及开箱即用的预训练模型,它们都可以帮助你更好地了解深度学习的相关知识。对深度学习感兴趣的读者推荐阅读美国量子物理学家Michael Nielsen编写的《神经网络与深度学习》(英文原版名为《Neural Networks and Deep Learning》),它对于深度学习基本过程和原理的讲解非常清晰。
一. 上手TensorFlow.js
Tensor(张量)是TensorFlow中的基本数据结构,它是向量和矩阵向更高维度的推广,从编程的角度来看,它的核心数据不过就是多维数组。或许你还记得在【带着canvas去流浪(9)】粒子动画一文中为了方便向量计算而定义的二维向量类Vector2,事实上它就可以被看作是Tensor在二维空间的简化形式。Tensor数据类型可以很方便地构造各种维度的张量,支持切片、变形、合并分割等结构操作,同时也定义了各类线性代数运算的操作符,这样做的好处是可以将开发者在应用层编写的程序和不同平台的底层实现之间解耦。这样,神经网络中的信息传递就通过张量(Tensor)的流动(Flow)表现出来了。在2018年Google I/O大会上,TensorFlow.js小组的工程师就介绍了该框架分层的结构设计,除了最底层为了解决编程语言和平台差异的层次外,为了对不同的工作性质的开发者实现更好地支持,TensorFlow.js在应用层还提供了两种不同的API:高阶API被称为Keras API(Keras是一个python编写的开源人工神经网络库)或Layer API,用于快速实现深度学习模型的构建、训练、评估和应用,软件和应用开发者大多情况下会使用它;低阶API也被称为Core API,通常用于支持研究人员对神经网络实现更底层的细节定制,使用起来难度也更高。
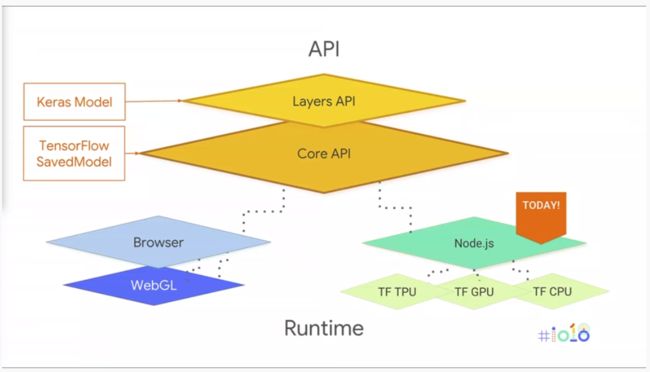
TensorFlow.js的工作依然是围绕神经网络展开的,基本的工作过程包含了如下几个典型步骤:

下面我们将通过TensorFlow.js官方网站提供的数据拟合的示例来了解整个流程。
Define阶段是使用TensorFlow.js的第一步,这个阶段中需要初始化神经网络模型,你可以在TensorFlow的tf.layers对象上找到具备各种功能和特征的隐藏层,通过模型实例的add方法将其逐层添加到神经网络中,从而实现张量变形处理、卷积神经网络、循环神经网络等复杂模型,当内置模型无法满足需求时,还可以自定义模型层,TensorFlow的高阶API可以帮助开发者以声明式的编码来完成神经网络的结构搭建,示例代码如下:
/*创建模型*/
function createModel() {
const model = tf.sequential();
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
Compile阶段需要对训练过程进行一些参数预设,你可以先温习一下上一章中介绍过的BP神经网络的工作过程,然后再来理解下面的示例代码:
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
loss(损失)用于定义损失函数,它是神经网络的实际输出和期望输出之间偏差的量化评估标准,最常用的损失函数就是均方差损失(tf.losses.meanSquaredError),其他损失函数可以在TensorFlow的API文档中进行查看;optimizer(优化器)是指误差反向传播结束后,神经网络进行权重调整时所使用的的算法。权重调整的目的就是为了使损失函数达到极小值,所以通常采用“梯度下降”的思想来进行逼近,梯度方向是指函数在某一点变化最显著的方向,但实际的情况往往并没有这么简单,假设下图是一个神经网络的损失函数曲线:

可以看到损失函数的形态、初始参数的位置以及优化过程的步长等都可能对训练过程和训练结果产生影响,这就需要在optimizer配置项中指定优化算法来达到较好的训练效果;metrics配置项用于指定模型的度量指标,大多数情况下可以直接使用损失函数来作为度量标准。
Fit阶段执行的是模型训练的工作(fit本身是拟合的意思),通过调用模型的fit方法就可以启动训练循环,官方示例代码如下(fit方法接收的参数分别为输入张量集、输出张量集和配置参数):
const batchSize = 32;
const epochs = 50;
await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
相关参数说明如下(其他参数可参考官方开发文档):
-
batchSize(批大小)指每个循环中使用的样本数,通常取值为32~512 -
epochs指定整个训练集上的数据的总循环次数 -
shuffle指是否在每个epochs中打乱训练样本的次序 -
callbacks指定了训练过程中的回调函数
神经网络的训练是循环进行的,假设总训练样本大小为320个,那么上面的示例代码所描述的训练过程是:先使用下标为031的样本来训练神经网络,然后使用optimizer来更新一次权重,再使用下标为3263的样本进行训练,再更新权重,直到总样本中所有数据均被使用过一次,上述过程被称为一个epoch,接着打乱整个训练样本的次序,再重复共计50轮,callbacks回调函数参数直接关联了tfvis库,它是TensorFlow提供的专用可视化工具模块。
Evaluate阶段需要对模型的训练结果进行评估,调用模型实例的evaluate方法就可以使用测试数据来获得损失函数和度量标准的数值。你可能已经注意到TensorFlow在定制训练过程时更加关注如何使用样本数据,而并没有将“度量指标小于给定阈值”作为训练终止的条件(例如brain.js中就可以通过设置errorthresh参数),在复杂神经网络的构建和设计中,开发者很可能需要一边构建一边进行非正式的训练测试,度量指标最终并不一定能够降低到给定的阈值以下,以此作为训练终止条件很可能会使训练过程陷入无限循环,所以使用固定的训练次数配合可视化工具来观察训练过程就更为合理。
Predict阶段是使用神经网络模型进行预测的阶段,这也是前端工程师参与度最高的部分,毕竟模型输出的结果只是数据,如何利用这些预测结果来制作一些更有趣或者更加智能化的应用或许才是前端工程师更应该关注的问题。从前文的过程中不难看出,TensorFlow.js提供的能力是围绕神经网络模型展开的,应用层很难直接使用,开发者通常都需要借助官方模型仓库中提供的预训练模型或者使用其他基于TensorFlow.js构建的第三方应用,例如人脸识别框架face-api.js(它可以在浏览器端和Node.js中实现快速的人脸追踪和身份识别),语义化更加明确的机器学习框架ml5.js(可以直接调用API来实现图像分类、姿势估计、人物抠图、风格迁移、物体识别等更加具体的任务),可以实现手部跟踪的handtrack.js等等,如果TensorFlow的相关知识让你觉得过于晦涩,也可以先尝试使用这些更高层的框架来构建一些有趣的程序。
二. 使用TensorFlow.js构建卷积神经网络
卷积神经网络
卷积神经网络(Convolutional Neural Networks,简称CNN)是计算视觉领域应用非常广泛的深度学习模型,它在处理图片或其他具有网格状特征的数据时具有非常好的表现。在信息处理时,卷积神经网络会先保持像素的行列空间结构,通过多个数学计算层来进行特征提取,然后再将信号转换为特征向量将其接入传统神经网络的结构中,经过特征提取的图像所对应的特征向量在提供给传统神经网络时体积更小,需要训练的参数数量也会相应减少。卷积神经网络的基本工作原理图如下(图中各个层的数量并不是固定的):
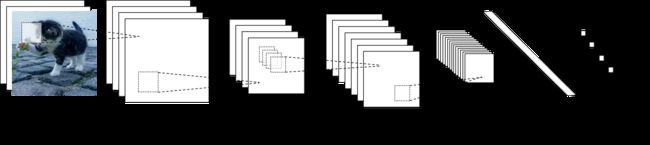
为了搞清楚卷积网络的工作流程,需要先了解卷积和池化这两个术语的含义。
卷积层需要对输入信息进行卷积计算,它使用一个网格状的窗口区(也被称为卷积核或过滤器)对输入图像进行遍历加工,过滤器的每个窗口单元通常都具有自己的权重,从输入图像的左上角开始,将权重和窗口覆盖区域的数值相乘并累加后得到一个新的结果,这个结果就是该区域映射后的值,接着将过滤器窗口向右滑动固定的距离(通常为1个像素),然后重复前面的过程,当过滤器窗口的右侧和输入图像的右边界重合后,窗口向下移动同样的距离,再次从左向右重复前面的过程,直到所有的区域遍历完成后就可以得到新的行列数据。每将一个不同的过滤器应用于输入图像后,卷积层就会增加一个输出,真实的深度网络中可能会使用多个过滤器,所以在卷积神经网络的原理图中通常会看到卷积层有多个层叠的图像。不难计算,对于一个输入尺寸为MM的图像,使用NN的过滤器处理后,新图像的单边尺寸为M-N+1。例如一个输入尺寸是88的灰度图,使用33过滤器对其进行卷积计算后,就会得到一个6*6的新图片,如下图所示:
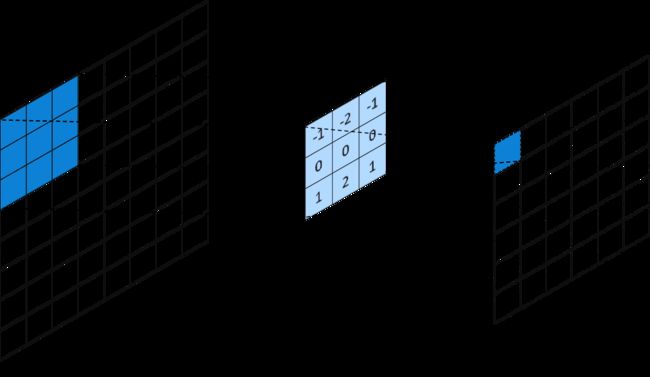
不同的过滤器可以识别出图像中不同的微小特征,例如上图中的过滤器,对于一个33大小的纯色区域,卷积计算的结果均为0,假设现在有一个上白下黑的边界,那么过滤器中上侧的计算结果会非常小,而中间一行和下面一行的结果都接近0,卷积计算的累加结果也会映射为一个很小的负数,相当于过滤器将一个33区域内的典型特征记录在1个像素中,也就达到了特征提取的目的,很明显,如果将上面的过滤器旋转90°,就可以用来识别图像中的垂直边界。由于卷积计算会将一个区域内的特征缩小到一个点上,所以卷积层的输出信息也被称为特征映射图。本章的代码仓中笔者基于canvas实现了一个简单的卷积计算程序,你可以在源码中修改过滤器的参数来观察处理后的图像,这就好像是在给图片添加各种有趣的滤镜一样:
上图分别展示了水平边缘检测、垂直边缘检测和斜线边缘检测处理后的效果。
再来看看池化层(也被称为混合层、合并层或下采样层),它通常紧接着卷积层之后来使用。图像中相邻像素的值通常比较接近,这会导致卷积层输出结果的产生大量信息冗余,比如一个水平边缘在卷积层中周围的像素可能也检测到了水平边缘,但事实上它们表示的是原图中的同一个特征,池化层的目的是就是简化卷积层的输出信息,它输出的每个单元可以被认为概括了前一层中一个区域的特征,常用的最大池化层就是在区域内选取一个最大值来作为整个区域在池化层的映射(这并不是唯一的池化计算方法),假设前文示例中的66的卷积层输出后紧接着一个使用22大小的窗口来进行区域映射的最大池化层,那么最终将得到一个3*3的图像输出,过程如下图所示:

可以看到,在不考虑深度影响时,示例中8*8的输入图像经过卷积层和池化层的处理后已经变成3*3大小了,对于后续的全连接神经网络而言,输入特征的数量已经大幅减少了。本章代码仓库中也提供了经过“卷积层+最大池化层”处理后图像变化的可视化示例,直观效果其实就是图片缩放,可以看到缩放后的图片仍然保持了池化前的典型特征:

在对复杂画面进行分析时,“卷积+池化”的模式可能会在网络中进行多次串联,以便可以从图像中逐级提取特征。在实际开发过程中,为了解决具体的计算视觉问题,开发者很可能需要自己去查阅相关学术论文并搭建相关的深度学习网络,它们通常使用非常简洁的符号来表示,下一节中我们将以经典的LeNet-5模型为例来学习相关的知识。
搭建LeNet-5模型
LeNet-5是一种高效的卷积神经网络模型,几乎在所有以MNIST手写数字图像识别为例的教程中都会介绍它,LeNet-5是论文《Gradient-Based Learning Applied to Document Recognition》中提出的,论文中给出的结构示意图如下:

可以看到模型中一共有7层,其含义和相关解释如下表所示:
| 序号 | 类别 | 标记 | 细节 |
|---|---|---|---|
| / | 输入层 | INPUT 32X32 | 输入为32x32像素的图片 |
| C1 | 卷积层 | C1:feature maps 6@28x28 | 卷积层,输出特征图共6个,每个尺寸为28x28(卷积核尺寸为5x5) |
| S2 | 池化层 | S2:f.maps6@14x14 | 池化层,对前一层的输出进行降采样,输出特征映射图共6个,每个尺寸14x14(降采样窗口尺寸为2x2) |
| C3 | 卷积层 | C3:f.maps16@10x10 | 卷积层,输出特征图共16个,每个尺寸为10x10(卷积核尺寸为5x5) |
| S4 | 池化层 | S4:f.maps16@5x5 | 池化层,对前一层的输出进行降采样,输出特征映射图共16个,每个尺寸5x5(降采样窗口尺寸为2x2) |
| C5 | 卷积层 | C5:layer 120 | 卷积层,输出特征图共120个,每个尺寸为1x1(卷积核尺寸为5x5) |
| F6 | 全连接层 | F6:layer 84 | 全连接层,使用84个神经元 |
| / | 输出层 | OUTPUT 10 | 输出层,10个节点,代表0~9共10个数字 |
在完成类似的图片分类任务时,构建的卷积神经网络并不需要完全与LeNet-5模型保持完全一致,只需要根据实际需求对它进行微调或扩展即可,例如在TensorFlow.js官方的“利用CNN识别手写数字”教程中,就在C1层使用了8个卷积核,并去掉了整个F6全连接层,即便这样依然能够获得不错的识别率。TensorFlow.js提供的layers API可以很方便地生成定制的卷积层和池化层,示例代码如下:
model = tf.sequential();
//添加LeNet-5中的 C1层
model.add(tf.layers.conv2d({
inputShape: [32, 32, 1],//输入张量的形状
kernelSize: 5, //卷积核尺寸
filters: 6, //卷积核数量
strides: 1, //卷积核移动步长
activation: 'relu', //激活函数
kernelInitializer: 'varianceScaling' //卷积核权重初始化方式
}));
//生成LeNet-5中的 S2层
model.add(tf.layers.maxPooling2d({
poolSize: [2, 2],//滑动窗口尺寸
strides: [2, 2]//滑动窗口移动步长
}));
官方教程提供的示例代码使用tfjs-vis库对训练过程进行了可视化,你可以很清楚地看到神经网络的结构、训练过程中度量指标的变化以及测试数据的预测结果汇总等信息:
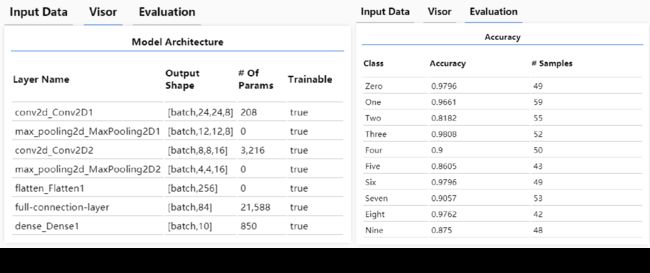
三. 基于迁移学习的语音指令识别
复杂的深度学习模型通常具有上百万的参数,即便能够重新搭建起整个神经网络,中小型开发者也没有足够的数据和机器资源来从头训练它,这就需要开发者将已经在相关任务中训练过的模型复用到新的模型中,从而降低深度学习模型搭建和训练的天然门槛,让更多的应用层开发这可以参与进来。
迁移学习是指一个使用数据集A完成训练的模型,被用于解决和另一个数据集B相关的任务,这通常需要对模型进行一些调整并使用数据集B重新训练它。幸运的是,有了A数据集训练结果的基础,重新训练模型时需要的新样本数和训练的时间都会大幅减少。调整预训练模型的基本方法是将它的输出层替换为自己需要的形式,而保留其他特征提取网络的部分,对于同类型的任务而言,被保留的部分依然可以完成特征提取的任务,并对类似的信号进行分类,但如果数据集A和数据集B的特征差异过大,新的模型仍有可能无法达到期望的效果,就需要对预训练模型进行更多的定制和改造(比如调整卷积神经网络中的卷积层和池化层的数量或参数),相关的理论和方法本章中不再展开。TensorFlow.js官方提供了的预训练模型可以实现图像分类、对象检测、姿势估计、面部追踪、文本恶意检测、句子编码、语音指令识别等等非常丰富的功能,本节中就以“语音指令识别”功能为例来了解迁移学习相关的技术。
TensorFlow.js官方语音识别模型speech-commands每次可以针对长度为1秒的音频片段进行分类,它已经使用近5万个声音样本进行过训练,直接使用时可以识别英文发音的数字(如zero ~ nine)、方向(up,down,right,left)和一些简单指令(如yes,no等),在这个预训练模型的基础上,只要通过少量的新样本就可以将它改造为一个中文指令识别器,是不是很方便?一段音频信号在处理时,会先通过快速傅里叶变换将其转换为频域信号,然后提取特征将其送入深度学习网络进行分析,对于简易指令的使用场景而言,只需要对若干个声音指令进行分类就可以了,并不需要计算机进行语种或真实语义分析,所以一个英文指令识别器才可以方便地改造为中文指令识别工具。语音指令功能的本质是对短语音进行分类,例如训练中将“向左”的声音片段标记为“右”,训练后的神经网络在听到“向左”时就会将其归类为“右”,使用预训练模型speech-command实现迁移学习的基本步骤如下:

官方提供的扩展库将具体的实现封装起来,提供给开发者的应用层API已经非常易用,本章代码仓中提供了一个完整的示例,你可以通过采集自己的声音样本来生成中文指令,然后重新训练迁移模型,并尝试用它来控制《吃豆人》游戏中的角色:
推荐课程
-
李宏毅 《深度学习》课程 (地址: http://speech.ee.ntu.edu.tw/~tlkagk/index.html)
-
吴恩达 《机器学习》在线教程(地址: https://www.coursera.org/learn/machine-learning)
-
MIT 6.S191《深度学习导论》(地址:http://introtodeeplearning.com/)
-
Stanford CS231.n《卷积神经网络与计算视觉》 (地址http://cs231n.stanford.edu/)