分布式消息队列RocketMQ与Kafka架构上的巨大差异之2 -- CommitLog与ConsumeQueue
在前面Rocket与Kafka的对比之“拨乱反正”续篇中,我们已经提到了RocketMQ和Kafka在架构上面的一个巨大差异:Kafka是每个partition对应一个文件,而RocketMQ是把所有topic的所有queue的消息存储在一个文件里面,然后再分发给ConsumeQueue。
存储上的巨大差异
Kafka的存储
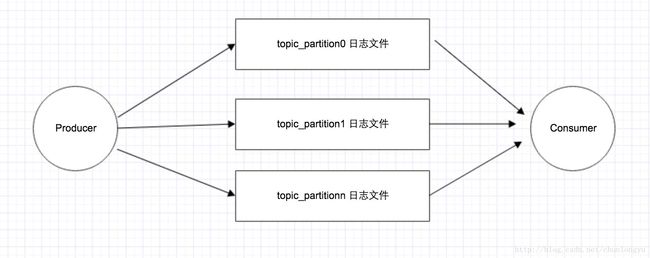
下图展示了Kafka的存储结构: 其中每个topic_partition对应一个日志文件,Producer对该日志文件进行“顺序写”,Consumer对该文件进行“顺序读”。
但正如在“拨乱反正”续篇中所提到的:这种存储方式,对于每个文件来说是顺序IO,但是当并发的读写多个partition的时候,对应多个文件的顺序IO,表现在文件系统的磁盘层面,还是随机IO。
因此出现了当partition或者topic个数过多时,Kafka的性能急剧下降。参见http://blog.csdn.net/chunlongyu/article/details/53913758
RocketMQ的存储
为了解决上述问题,RocketMQ采用了单一的日志文件,即把同1台机器上面所有topic的所有queue的消息,存放在一个文件里面,从而避免了随机的磁盘写入。其存储结构如下:
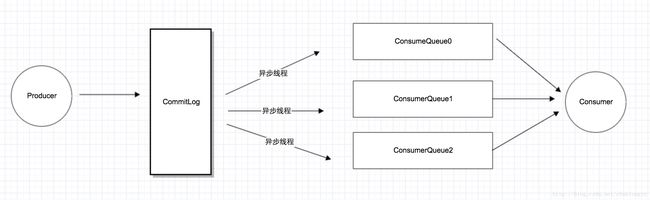
如上图所示,所有消息都存在一个单一的CommitLog文件里面,然后有后台线程异步的同步到ConsumeQueue,再由Consumer进行消费。
关键性差异
上面的存储差异,说的明显一点,就是:Kafka针对Producer和Consumer使用了同1份存储结构,而RocketMQ却为Producer和Consumer分别设计了不同的存储结构,Producer对应CommitLog, Consumer对应ConsumeQueue。
这其实也是“异步化“,或者说”离线计算“的一个典型例子。参见分布式思想汇总一文:http://blog.csdn.net/chunlongyu/article/details/52525604
这里至所以可以用“异步线程”,也是因为消息队列天生就是用来“缓冲消息”的。只要消息到了CommitLog,发送的消息也就不会丢。只要消息不丢,那就有了“充足的回旋余地”,用一个后台线程慢慢同步到ConsumeQueue,再由Consumer消费。
可以说,这也是在消息队列内部的一个典型的“最终一致性”的案例:Producer发了消息,进了CommitLog,此时Consumer并不可见。但没关系,只要消息不丢,消息最终肯定会进入ConsumeQueue,让Consumer可见。
CommitLog与ConsumeQueue结构
CommitLog的文件结构
下图展示了CommitLog的文件结构,可以看到,包含了topic、queueId、消息体等核心信息。
同Kafka一样,消息是变长的,顺序写入。

ConsumeQueue的文件结构
ConsumeQueue中并不需要存储消息的内容,而存储的是消息在CommitLog中的offset。也就是说,ConsumeQuue其实是CommitLog的一个索引文件。
如下图所示: 
ConsumeQueue是定长的结构,每1条记录固定的20个字节。很显然,Consumer消费消息的时候,要读2次:先读ConsumeQueue得到offset,再读CommitLog得到消息内容。
CommitLog的“顺序写”与“随机读”– MappedFileQueue
从上面的分析我们已经知道:对于ConsumeQueue,是完全的顺序读写。可是对于CommitLog,Producer对其“顺序写”,Consumer却是对其“随机读”。
对于这样的一个大型文件,又要随机读,如何提高读写效率呢?
答案就是“内存映射文件”。关于内存映射文件的原理,以后有机会,可以在Linux的篇章中,详细分析。此处就不展开了。
对于RocketMQ来说,它是把内存映射文件串联起来,组成了链表。因为内存映射文件本身大小有限制,只能是2G。所以需要把多个内存映射文件串联成一个链表,来和一个屋里文件对应起来。
public class CommitLog {
...
private final MappedFileQueue mappedFileQueue;
...
}
*/
public class ConsumeQueue {
...
private final MappedFileQueue mappedFileQueue;
...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
从上面源代码可以看出,无论CommitLog,还是ConsumeQueue,都有一个对应的MappedFileQueue,也就是对应的内存映射文件的链表。
public class MappedFileQueue {
...
private final CopyOnWriteArrayList mappedFiles = new CopyOnWriteArrayList();
...
} - 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
读写时,根据offset定位到链表中,对应的MappedFile,进行读写。
通过MappedFile,就很好的解决了大文件随机读的性能问题。