工作记录 | 基于DocSearch黑一套搜索引擎
记录一下最近工作中利用DocSearch,基于ServiceWorker和CacheAPI“恶搞”的一套Wiki搜索引擎,挺有意思的。

首先要考虑前端的基础设施。。
开发者开发一款app前首先考虑的是:自己能调度的硬件资源。硬件资源包括算力(时间资源)、存储力(空间资源)。
前端这个岗位是比较尴尬的,因为对我们来说,后端只提供有限的服务:只读的文件服务。通常一款app的架构基本上都是前端+后端,也就是一款app可以利用2台机器的算力和存储力为自己服役,这2台机器就是开发者的物质基础。
在“前后端分离”的大环境下,前端开发者所拥有的资源是有限的。这个限制主要在于服务器的算力上。服务器不能像往常那样提供任意的计算服务,只能提供静态文件的访问权限,对于前端来说,这台服务器是“read only”的。
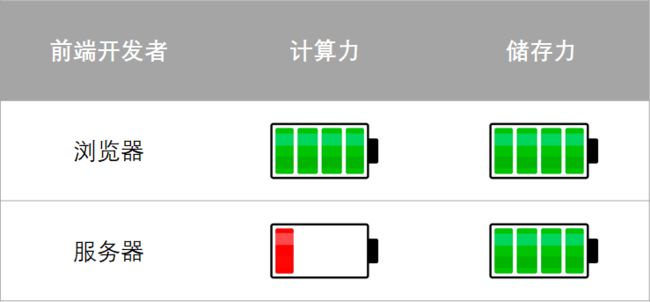
在这种充满挑战的环境,利用有限的资源开发app就是我们的日常。
然后回归主题。
扯了这么一大通就是为了证明,原来搜索引擎可以不用服务器的支持。由于“被搜索”的数据库就是所有markdown文档的一二三级标题,所有这些标题存储在index.json(下面简称index)作为【文档索引】从后端运送到前端,并在前端完成搜索工作。
// index.json的格式
[
{
"url": "/path/to/document",
"keys": [
"Title1",
"Title2",
... ]
},
{
...
}
]
看到了吗,这就是前后端分离的弱点:想要尽情利用前端算力的前提是要把【计算材料】提前送到前端,而输送是需要时间的。如果能在后端直接使用材料就省去了这个步骤。
生成文档索引的时候我是将所有markdown并发执行,节约时间是一方面,这样还可以导致每次的index.json的顺序都不太一样,排序不分先后,让每个标题都有均等的机会被搜索到,当然这只是统计意义上的平均,不过感觉还不错。
而且,index.json不是很大,可以在浏览器空闲时间下载并缓存起来:
global.caches.open("index").then(cache => {
cache.add(new Request("/path/to/index.json"));
});
但缓存是外存,使用的时候还要临时加载到内存中,这就是懒加载。将index从外存懒加载到内存中需要做一些准备:
我们需要一个变量来存放index;
我们需要一个函数来处理懒加载;
我们需要一个promise来确定外存是否可读;
我们需要一个算法来在index中搜索关键词;
于是我们需要4个闭包安全的全局变量:
const $index = Symbol('lazy load from cache async function');
const $indexOk = Symbol('promise checking if cache is ok');
const $indexJson = Symbol('store index into a variable');
const $indexSearch = Symbol('function searching keys');
关于UI,我们用docSearch就好了,docSearch是一套搜索框架,但它只包含UI部分,所以应该叫“搜索框”架。这个框架提供了比较简洁的搜索框UI,支持最多6个层级的搜索结果,就像下图这样。
docSearch还提供了友好的交互效果,比如缓存已经搜索过的结果,防抖等细节做的很好。
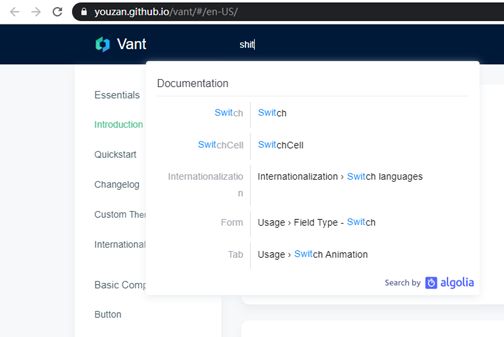
至于docSearch的后端,是一个叫做algolia的服务器,algolia通过爬取你的网站总结出一套关键词索引,再暴露给docSearch来请求。他的初衷是这样玩的,但是为了免费使用,我决定模拟一个服务器,伪造返回数据,达到同样的检索效果。
于是轮到我们ServiceWorker上场了(下面简称SW)。
SW的历史比较短,大致是浏览器发展到一定程度时,开始模仿Linux的守护进程(daemon),搞了一套应用级的,独立于前端控制、周期性地执行某种任务或等待处理某些发生事件,不会随app关闭而停止的守护线程,由于占用了一个worker线程,于是取名叫Service Worker。
于是我们可以利用SW来拦截docSearch的请求,代码如下:
self.addEventListener("fetch", event => {
// 拦截docSearch的请求
if (/bh4d9od16a.*algolia/.test(event.request.url)) {
event.respondWith(
(async () => {
// 从request中提取出关键词
const key = new URLSearchParams(
(await event.request.json()).requests[0].params
).get("query");
// 懒加载index.json
const index = await self[$index]();
// 搜索并返回结果
return new Response(JSON.stringify(self[$indexSearch](index, key)), {
headers: { "Content-Type": "application/json; charset=UTF-8" }
});
})()
);
}
});
为了避免“全表扫描”,“表”指内存中的列表,匹配到一定数量时应当终止扫描,我们可以通过Array的find、some、any等方法来实现这个效果:具体原理参考《函数式编程中的数组问题》。
docSearch支持的6级菜单中我只用了2级,第一级是markdown文件名,第二级是文档中的各级标题,然后先序遍历地搜索。在避免全表扫描的时候我设定的上限是5条结果,但前提是等待本次的第二级扫描完。这样做的结果导致有时候搜到六七条结果,甚至更多,有时候全表扫描完又不到5条,这样操作的唯一好处在于,可以给用户一种【神秘感】,有效地掩盖我的上限值5。
也许说的不太形象,举个例子,网易云音乐有个功能叫“定时关闭”,还支持“播完当前歌曲再关闭”,如图,即每次都要比定的时间稍微长一点。
扯远了。。
同时,为了支持正则表达式,我们将用户输入的关键词封装成正则表达式。为了将搜索能力最大化,还可以将“不合法”的表达式转换为普通的包含匹配,以保证用户的输入都是合法的:
let matcher;
try {
matcher = new RegExp(keyword, "i");
} catch (err) {
matcher = {
test: str => str.includes(keyword)
};
}
// usage: matcher.test(index.json)
完美。
然而这个方案还是被老板一票否决了,原因是SW和Cache必须在https下才能使用,而我们的wiki网站是http。。即使重写fetch方法来替代SW也无法容忍使用堵塞线程的webStorage来替代Cache。再之index.json较小的情况下还能玩玩内存搜索,【文档索引】的体积即使线性级增长也要考虑用用web sql来外存搜索。
<完>
