【Flink】基于 Flink 的电商用户行为分析(二)
1、市场营销商业指标统计分析
模块创建和数据准备
继续在 UserBehaviorAnalysis 下新建一个 maven module 作为子项目,命名为 MarketAnalysis。
这个模块中我们没有现成的数据,所以会用自定义的测试源来产生测试数据流,或者直接用生成测试数据文件。
APP 市场推广统计
随着智能手机的普及,在如今的电商网站中已经有越来越多的用户来自移动端,相比起传统浏览器的登录方式,手机 APP 成为了更多用户访问电商网站的首选。对于电商企业来说,一般会通过各种不同的渠道对自己的 APP 进行市场推广,而这些渠道的统计数据(比如,不同网站上广告链接的点击量、APP 下载量)就成了市场营销的重要商业指标。
首先我们考察分渠道的市场推广统计。 在 src/main/scala 下创建
AppMarketingByChannel.scala 文件。由于没有现成的数据,所以我们需要自定义一个测试源来生成用户行为的事件流。
自定义测试数据源
定义一个源数据的样例类 MarketingUserBehavior,再定义一个 SourceFunction,用于产生用户行为源数据,命名为 SimulatedEventSource:
case class MarketingUserBehavior(userId: Long, behavior: String, channel: String, timestamp: Long)
class SimulatedEventSource extends RichParallelSourceFunction[MarketingUserBehavior]{
var running = true
val channelSet: Seq[String] = Seq("AppStore", "XiaomiStore", "HuaweiStore", "weibo", "wechat", "tieba")
val behaviorTypes: Seq[String] = Seq("BROWSE", "CLICK", "PURCHASE", "UNINSTALL")
val rand: Random = Random
override def run(ctx: SourceContext[MarketingUserBehavior]): Unit = {
val maxElements = Long.MaxValue
var count = 0L
while (running && count < maxElements) {
val id = UUID.randomUUID().toString.toLong
val behaviorType = behaviorTypes(rand.nextInt(behaviorTypes.size))
val channel = channelSet(rand.nextInt(channelSet.size))
val ts = System.currentTimeMillis()
ctx.collectWithTimestamp(MarketingUserBehavior(id, behaviorType, channel, ts), ts)
count += 1
TimeUnit.MILLISECONDS.sleep(5L)
}
}
override def cancel(): Unit = running = false
}
分渠道统计
另外定义一个窗口处理的输出结果样例类 MarketingViewCount,并自定义
ProcessWindowFunction 进行处理,代码如下:
case class MarketingCountView(windowStart: Long, windowEnd: Long, channel: String, behavior: String, count: Long)
object AppMarketingByChannel {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val stream: DataStream[MarketingUserBehavior] = env.addSource(new SimulatedEventSource)
.assignAscendingTimestamps(_.timestamp)
stream
.filter(_.behavior != "UNINSTALL")
.map(data => {
((data.channel, data.behavior), 1L)
})
.keyBy(_._1)
.timeWindow(Time.hours(1), Time.seconds(1))
.process(new MarketingCountByChannel())
.print()
env.execute(getClass.getSimpleName)
}
}
class MarketingCountByChannel() extends ProcessWindowFunction[((String, String), Long), MarketingViewCount, (String, String), TimeWindow] {
override def process(key: (String, String), context: Context, elements: Iterable[((String, String), Long)], out: Collector[MarketingViewCount]): Unit = {
val startTs = context.window.getStart
val endTs = context.window.getEnd
val channel = key._1
val behaviorType = key._2
val count = elements.size
out.collect( MarketingViewCount(formatTs(startTs), formatTs(endTs), channel, behaviorType, count) )
}
private def formatTs (ts: Long) = {
val df = new SimpleDateFormat ("yyyy/MM/dd-HH:mm:ss")
df.format (new Date (ts) )
}
}
不分渠道(总量)统计
同样我们还可以考察不分渠道的市场推广统计,这样得到的就是所有渠道推广的总量。在 src/main/scala 下创建 AppMarketingStatistics.scala 文件,代码如下:
object AppMarketingStatistics {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val stream: DataStream[MarketingUserBehavior] = env.addSource(new SimulatedEventSource)
.assignAscendingTimestamps(_.timestamp)
stream
.filter(_.behavior != "UNINSTALL")
.map(data => {
("dummyKey", 1L)
})
.keyBy(_._1)
.timeWindow(Time.hours(1), Time.seconds(1))
.process(new MarketingCountTotal())
.print()
env.execute(getClass.getSimpleName)
}
}
class MarketingCountTotal() extends ProcessWindowFunction[(String, Long), MarketingViewCount, String, TimeWindow]{
override def process(key: String, context: Context, elements: Iterable[(String, Long)], out: Collector[MarketingViewCount]): Unit = {
val startTs = context.window.getStart
val endTs = context.window.getEnd
val count = elements.size
out.collect( MarketingViewCount(formatTs(startTs), formatTs(endTs), "total","total", count) )
}
private def formatTs (ts: Long) = {
val df = new SimpleDateFormat ("yyyy/MM/dd-HH:mm:ss")
df.format (new Date (ts))
}
}
页面广告分析
电商网站的市场营销商业指标中,除了自身的 APP 推广,还会考虑到页面上的广告投放(包括自己经营的产品和其它网站的广告)。所以广告相关的统计分析,也是市场营销的重要指标。
对于广告的统计,最简单也最重要的就是页面广告的点击量,网站往往需要根据广告点击量来制定定价策略和调整推广方式,而且也可以借此收集用户的偏好信息。更加具体的应用是,我们可以根据用户的地理位置进行划分,从而总结出不同省份用户对不同广告的偏好,这样更有助于广告的精准投放。
页面广告点击量统计
接下来我们就进行页面广告按照省份划分的点击量的统计。在 src/main/scala 下创建 AdStatisticsByGeo.scala 文件。同样由于没有现成的数据,我们定义一些测试数据,放在 AdClickLog.csv 中,用来生成用户点击广告行为的事件流。
在代码中我们首先定义源数据的样例类 AdClickLog,以及输出统计数据的样例类 CountByProvince。主函数中先以 province 进行 keyBy,然后开一小时的时间窗口,滑动距离为 5 秒,统计窗口内的点击事件数量。具体代码实现如下:
case class AdClickLog(userId: Long, adId: Long, province: String, city: String, timestamp: Long)
case class CountByProvince(windowEnd: String, province: String, count: Long)
object AdStatisticsByGeo {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val adLogStream: DataStream[AdClickLog] = env.readTextFile("YOURPATH\\resources\\AdClickLog.csv")
.map(data => {
val dataArray = data.split(",")
AdClickLog(dataArray(0).toLong, dataArray(1).toLong, dataArray(2), dataArray(3), dataArray(4).toLong)
})
.assignAscendingTimestamps(_.timestamp * 1000L)
val adCountStream = adLogStream
.keyBy(_.province)
.timeWindow(Time.minutes(60), Time.seconds(5))
.aggregate(new CountAgg(), new CountResult())
.print()
env.execute("ad statistics job")
}
}
class CountAgg() extends AggregateFunction[AdClickLog, Long, Long]{
override def add(value: AdClickLog, accumulator: Long): Long = accumulator + 1L
override def createAccumulator(): Long = 0L
override def getResult(accumulator: Long): Long = accumulator
override def merge(a: Long, b: Long): Long = a + b
}
class CountResult() extends WindowFunction[Long, CountByProvince, String, TimeWindow]{
override def apply(key: String, window: TimeWindow, input: Iterable[Long], out: Collector[CountByProvince]): Unit = {
out.collect(CountByProvince(formatTs(window.getEnd), key, input.iterator.next()))
}
private def formatTs (ts: Long) = {
val df = new SimpleDateFormat ("yyyy/MM/dd-HH:mm:ss")
df.format (new Date (ts) )
}
}
黑名单过滤
上节我们进行的点击量统计,同一用户的重复点击是会叠加计算的。在实际场景中,同一用户确实可能反复点开同一个广告,这也说明了用户对广告更大的兴趣;但是如果用户在一段时间非常频繁地点击广告,这显然不是一个正常行为,有刷点击量的嫌疑。所以我们可以对一段时间内(比如一天内)的用户点击行为进行约束,如果对同一个广告点击超过一定限额(比如 100 次),应该把该用户加入黑名单并报警,此后其点击行为不应该再统计。
具体代码实现如下:
case class AdClickLog(userId: Long, adId: Long, province: String, city: String, timestamp: Long)
case class CountByProvince(windowEnd: String, province: String, count: Long)
case class BlackListWarning(userId: Long, adId: Long, msg: String)
object AdStatisticsByGeo {
val blackListOutputTag = new OutputTag[BlackListWarning]("blacklist")
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val adLogStream: DataStream[AdClickLog] = env.readTextFile("D:\\Projects\\BigData\\UserBehaviorAnalysis\\MarketAnalysis\\src\\main\\resources\\AdClickLog.csv")
.map(data => {
val dataArray = data.split(",")
AdClickLog(dataArray(0).toLong, dataArray(1).toLong, dataArray(2), dataArray(3), dataArray(4).toLong)
})
.assignAscendingTimestamps(_.timestamp * 1000L)
val filterBlackListStream = adLogStream
.keyBy(logData => (logData.userId, logData.adId))
.process(new FilterBlackListUser(100))
val adCountStream = filterBlackListStream
.keyBy(_.province)
.timeWindow(Time.minutes(60), Time.seconds(5))
.aggregate(new countAgg(), new countResult())
.print()
filterBlackListStream
.getSideOutput(blackListOutputTag)
.print("black list")
env.execute("ad statistics job")
}
class FilterBlackListUser(maxCount: Long) extends KeyedProcessFunction[(Long, Long), AdClickLog, AdClickLog] {
// 保存当前用户对当前广告的点击量
lazy val countState: ValueState[Long] = getRuntimeContext.getState(new ValueStateDescriptor[Long]("count-state", classOf[Long]))
// 标记当前(用户,广告)作为 key 是否第一次发送到黑名单
lazy val firstSent: ValueState[Boolean] = getRuntimeContext.getState(new ValueStateDescriptor[Boolean]("firstsent-state", classOf[Boolean]))
// 保存定时器触发的时间戳,届时清空重置状态
lazy val resetTime: ValueState[Long] = getRuntimeContext.getState(new ValueStateDescriptor[Long]("resettime-state", classOf[Long]))
override def processElement(value: AdClickLog, ctx: KeyedProcessFunction[(Long, Long), AdClickLog, AdClickLog]#Context, out: Collector[AdClickLog]): Unit = {
val curCount = countState.value()
// 如果是第一次处理,注册一个定时器,每天 00 : 00 触发清除
if( curCount == 0 ){
val ts = (ctx.timerService().currentProcessingTime() / (24*60*60*1000) + 1) * (24*60*60*1000)
resetTime.update(ts)
ctx.timerService().registerProcessingTimeTimer(ts)
}
// 如果计数已经超过上限,则加入黑名单,用侧输出流输出报警信息
if( curCount > maxCount ){
if( !firstSent.value() ){
firstSent.update(true)
ctx.output( blackListOutputTag, BlackListWarning(value.userId, value.adId,"Click over " + maxCount + " times today.") )
}
return
}
// 点击计数加 1
countState.update(curCount + 1)
out.collect( value )
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[(Long, Long), AdClickLog, AdClickLog]#OnTimerContext, out: Collector[AdClickLog]): Unit = {
if( timestamp == resetTime.value() ){
firstSent.clear()
countState.clear()
}
}
}
}
class countAgg() extends AggregateFunction[AdClickLog, Long, Long] {
override def add(value: AdClickLog, accumulator: Long): Long = accumulator + 1L
override def createAccumulator(): Long = 0L
override def getResult(accumulator: Long): Long = accumulator
override def merge(a: Long, b: Long): Long = a + b
}
class countResult() extends WindowFunction[Long, CountByProvince, String, TimeWindow]{
override def apply(key: String, window: TimeWindow, input: Iterable[Long], out: Collector[CountByProvince]): Unit = {
out.collect(CountByProvince(formatTs(window.getEnd), key, input.iterator.next()))
}
private def formatTs(ts: Long) = {
val df = new SimpleDateFormat("yyyy/MM/dd-HH:mm:ss")
df.format(new Date(ts))
}
}
2、恶意登录监控
模块创建和数据准备
继续在 UserBehaviorAnalysis 下新建一个 maven module 作为子项目,命名为 LoginFailDetect。在这个子模块中,我们将会用到 flink 的 CEP 库来实现事件流的模式匹配,所以需要在 pom 文件中引入 CEP 的相关依赖:
org.apache.flink
flink-cep-scala_${scala.binary.version}
${flink.version}
同样,在 src/main/目录下,将默认源文件目录 java 改名为 scala。
代码实现
对于网站而言,用户登录并不是频繁的业务操作。如果一个用户短时间内频繁登录失败,就有可能是出现了程序的恶意攻击,比如密码暴力破解。因此我们考虑,应该对用户的登录失败动作进行统计,具体来说,如果同一用户(可以是不同 IP)在 2 秒之内连续两次登录失败,就认为存在恶意登录的风险,输出相关的信息进行报警提示。这是电商网站、也是几乎所有网站风控的基本一环。
状态编程
由于同样引入了时间,我们可以想到,最简单的方法其实与之前的热门统计类似,只需要按照用户 ID 分流,然后遇到登录失败的事件时将其保存在 ListState 中,然后设置一个定时器,2 秒后触发。定时器触发时检查状态中的登录失败事件个数,如果大于等于 2,那么就输出报警信息。
在 src/main/scala 下创建 LoginFail.scala 文件,新建一个单例对象。定义样例类 LoginEvent,这是输入的登录事件流。登录数据本应该从 UserBehavior 日志里提取,由于 UserBehavior.csv 中没有做相关埋点,我们从另一个文件 LoginLog.csv 中读取登录数据。
代码如下:
LoginFailDetect/src/main/scala/LoginFail.scala
case class LoginEvent(userId: Long, ip: String, eventType: String, eventTime: Long)
object LoginFail {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val loginEventStream = env.readTextFile("YOUR_PATH\\resources\\LoginLog.csv")
.map( data => {
val dataArray = data.split(",")
LoginEvent(dataArray(0).toLong, dataArray(1), dataArray(2), dataArray(3).toLong)
})
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[ApacheLogEvent](Time.milliseconds(3000)) {
override def extractTimestamp(element: ApacheLogEvent): Long ={
element.eventTime * 1000L
}
})
.keyBy(_.userId)
.process(new MatchFunction())
.print()
env.execute("Login Fail Detect Job")
}
class MatchFunction extends KeyedProcessFunction[Long, LoginEvent, LoginEvent] {
// 定义状态变量
lazy val loginState: ListState[LoginEvent] = getRuntimeContext.getListState(new ListStateDescriptor[LoginEvent]("saved login", classOf[LoginEvent]))
override def processElement(login: LoginEvent, context: KeyedProcessFunction[Long, LoginEvent, LoginEvent]#Context, out: Collector[LoginEvent]): Unit = {
if (login.eventType == "fail") {
loginState.add(login)
}
// 注册定时器,触发事件设定为 2 秒后
context.timerService.registerEventTimeTimer(login.eventTime * 1000 + 2 * 1000)
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Long, LoginEvent, LoginEvent]#OnTimerContext, out: Collector[LoginEvent]): Unit = {
val allLogins: ListBuffer[LoginEvent] = ListBuffer()
import scala.collection.JavaConversions._
for (login <- loginState.get) {
allLogins += login
}
loginState.clear()
if (allLogins.length > 1) {
out.collect(allLogins.head)
}
}
}
}
状态编程的改进
上一节的代码实现中我们可以看到,直接把每次登录失败的数据存起来、设置定时器一段时间后再读取,这种做法尽管简单,但和我们开始的需求还是略有差异的。这种做法只能隔 2 秒之后去判断一下这期间是否有多次失败登录,而不是在一次登录失败之后、再一次登录失败时就立刻报警。这个需求如果严格实现起来,相当于要判断任意紧邻的事件,是否符合某种模式。
于是我们可以想到,这个需求其实可以不用定时器触发,直接在状态中存取上一次登录失败的事件,每次都做判断和比对,就可以实现最初的需求。
上节的代码 MatchFunction 中删掉 onTimer,processElement 改为:
override def processElement(value: LoginEvent, ctx: KeyedProcessFunction[Long, LoginEvent, Warning]#Context, out: Collector[Warning]): Unit = {
// 首先按照 type 做筛选,如果 success 直接清空,如果 fail 再做处理
if ( value.eventType == "fail" ){
// 如果已经有登录失败的数据,那么就判断是否在两秒内
val iter = loginState.get().iterator()
if ( iter.hasNext ){
val firstFail = iter.next()
// 如果两次登录失败时间间隔小于 2 秒,输出报警
if ( value.eventTime < firstFail.eventTime + 2 ){
out.collect( Warning( value.userId, firstFail.eventTime, value.eventTime, "login fail in 2 seconds." ) )
}
// 把最近一次的登录失败数据,更新写入 state 中
val failList = new util.ArrayList[LoginEvent]()
failList.add(value)
loginState.update( failList )
} else {
// 如果 state 中没有登录失败的数据,那就直接添加进去
loginState.add(value)
}
} else
loginState.clear()
}
CEP 编程
上一节我们通过对状态编程的改进,去掉了定时器,在 process function 中做了更多的逻辑处理,实现了最初的需求。不过这种方法里有很多的条件判断,而我们目前仅仅实现的是检测“连续 2 次登录失败”,这是最简单的情形。如果需要检测更多次,内部逻辑显然会变得非常复杂。那有什么方式可以方便地实现呢?
很幸运,flink 为我们提供了 CEP(Complex Event Processing,复杂事件处理)库,用于在流中筛选符合某种复杂模式的事件。接下来我们就基于 CEP 来完成这个模块的实现。
在 src/main/scala 下继续创建 LoginFailWithCep.scala 文件,新建一个单例对象。样例类 LoginEvent 由于在 LoginFail.scala 已经定义,我们在同一个模块中就不需要再定义了。
代码如下:
LoginFailDetect/src/main/scala/LoginFailWithCep.scala
object LoginFailWithCep {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val loginEventStream = env.readTextFile("YOUR_PATH\\resources\\LoginLog.csv")
.map( data => {
val dataArray = data.split(",")
LoginEvent(dataArray(0).toLong, dataArray(1), dataArray(2), dataArray(3).toLong)
})
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[ApacheLogEvent](Time.milliseconds(3000)) {
override def extractTimestamp(element: ApacheLogEvent): Long ={
element.eventTime * 1000L
}
})
// 定义匹配模式
val loginFailPattern = Pattern.begin[LoginEvent]("begin")
.where(_.eventType == "fail")
.next("next")
.where(_.eventType == "fail")
.within(Time.seconds(2))
// 在数据流中匹配出定义好的模式
val patternStream = CEP.pattern(loginEventStream.keyBy(_.userId), loginFailPattern)
// .select 方法传入一个 pattern select function ,当检测到定义好的模式序列时就会调用
val loginFailDataStream = patternStream
.select((pattern: Map[String, Iterable[LoginEvent]]) => {
val first = pattern.getOrElse("begin", null).iterator.next()
val second = pattern.getOrElse("next", null).iterator.next()
(second.userId, second.ip, second.eventType)
})
// 将匹配到的符合条件的事件打印出来
loginFailDataStream.print()
env.execute("Login Fail Detect Job")
}
}
3、订单支付实时监控
在电商网站中,订单的支付作为直接与营销收入挂钩的一环,在业务流程中非常重要。对于订单而言,为了正确控制业务流程,也为了增加用户的支付意愿,网站一般会设置一个支付失效时间,超过一段时间不支付的订单就会被取消。另外,对于订单的支付,我们还应保证用户支付的正确性,这可以通过第三方支付平台的交易数据来做一个实时对账。在接下来的内容中,我们将实现这两个需求。
模块创建和数据准备
同样地,在 UserBehaviorAnalysis 下新建一个 maven module 作为子项目,命名为 OrderTimeoutDetect。在这个子模块中,我们同样将会用到 flink 的 CEP 库来实现事件流的模式匹配,所以需要在 pom 文件中引入 CEP 的相关依赖:
org.apache.flink
flink-cep-scala_${scala.binary.version}
${flink.version}
同样,在 src/main/目录下,将默认源文件目录 java 改名为 scala。
代码实现
在电商平台中,最终创造收入和利润的是用户下单购买的环节;更具体一点,是用户真正完成支付动作的时候。用户下单的行为可以表明用户对商品的需求,但在现实中,并不是每次下单都会被用户立刻支付。当拖延一段时间后,用户支付的意愿会降低。所以为了让用户更有紧迫感从而提高支付转化率,同时也为了防范订单支付环节的安全风险,电商网站往往会对订单状态进行监控,设置一个失效时间(比如 15 分钟),如果下单后一段时间仍未支付,订单就会被取消。
使用 CEP 实现
我们首先还是利用 CEP 库来实现这个功能。我们先将事件流按照订单号 orderId 分流,然后定义这样的一个事件模式:在 15 分钟内,事件“create”与“pay”非严格紧邻:
val orderPayPattern = Pattern.begin[OrderEvent]("begin")
.where(_.eventType == "create")
.followedBy("follow")
.where(_.eventType == "pay")
.within(Time.seconds(5))
这样调用.select 方法时,就可以同时获取到匹配出的事件和超时未匹配的事件了。
在 src/main/scala 下继续创建 OrderTimeout.scala 文件,新建一个单例对象。定义样例类 OrderEvent,这是输入的订单事件流;另外还有 OrderResult,这是输出显示的订单状态结果。订单数据也本应该从UserBehavior 日志里提取,由于 UserBehavior.csv 中没有做相关埋点,我们从另一个文件 OrderLog.csv 中读取登录数据。
完整代码如下:
OrderTimeoutDetect/src/main/scala/OrderTimeout.scala
case class OrderEvent(orderId: Long, eventType: String, eventTime: Long)
case class OrderResult(orderId: Long, eventType: String)
object OrderTimeout {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val orderEventStream = env.readTextFile("YOUR_PATH\\resources\\OrderLog.csv")
.map( data => {
val dataArray = data.split(",")
OrderEvent(dataArray(0).toLong, dataArray(1), dataArray(3).toLong)
})
.assignAscendingTimestamps(_.eventTime * 1000)
// 定义一个带匹配时间窗口的模式
val orderPayPattern = Pattern.begin[OrderEvent]("begin")
.where(_.eventType == "create")
.followedBy("follow")
.where(_.eventType == "pay")
.within(Time.minutes(15))
// 定义一个输出标签
val orderTimeoutOutput = OutputTag[OrderResult]("orderTimeout")
// 订单事件流根据 orderId 分流,然后在每一条流中匹配出定义好的模式
val patternStream = CEP.pattern(orderEventStream.keyBy("orderId"), orderPayPattern)
val completedResult = patternStream.select(orderTimeoutOutput) {
// 对于已超时的部分模式匹配的事件序列,会调用这个函数
(pattern: Map[String, Iterable[OrderEvent]], timestamp: Long) => {
val createOrder = pattern.get("begin")
OrderResult(createOrder.get.iterator.next().orderId, "timeout")
}
} {
// 检测到定义好的模式序列时,就会调用这个函数
pattern: Map[String, Iterable[OrderEvent]] => {
val payOrder = pattern.get("follow")
OrderResult(payOrder.get.iterator.next().orderId, "success")
}
}
// 拿到同一输出标签中的 timeout 匹配结果(流)
val timeoutResult = completedResult.getSideOutput(orderTimeoutOutput)
completedResult.print()
timeoutResult.print()
env.execute("Order Timeout Detect Job")
}
}
使用 Process Function 实现
我们同样可以利用 Process Function,自定义实现检测订单超时的功能。为了简化问题,我们只考虑超时报警的情形,在 pay 事件超时未发生的情况下,输出超时报警信息。
一个简单的思路是,可以在订单的 create 事件到来后注册定时器,15 分钟后触发;然后再用一个布尔类型的 Value 状态来作为标识位,表明 pay 事件是否发生过。
如果 pay 事件已经发生,状态被置为 true,那么就不再需要做什么操作;而如果 pay 事件一直没来,状态一直为 false,到定时器触发时,就应该输出超时报警信息。
具体代码实现如下:
OrderTimeoutDetect/src/main/scala/OrderTimeoutWithoutCep.scala
object OrderTimeoutWithoutCep {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val orderEventStream = env.readTextFile("YOUR_PATH\\resources\\OrderLog.csv")
.map( data => {
val dataArray = data.split(",")
OrderEvent(dataArray(0).toLong, dataArray(1), dataArray(3).toLong)
})
.assignAscendingTimestamps(_.eventTime * 1000)
.keyBy(_.orderId)
// 自定义一个 process function ,进行 order 的超时检测,输出超时报警信息
val timeoutWarningStream = orderEventStream
.process(new OrderTimeoutAlert)
timeoutWarningStream.print()
env.execute()
}
class OrderTimeoutAlert extends KeyedProcessFunction[Long, OrderEvent, OrderResult]{
lazy val isPayedState: ValueState[Boolean] = getRuntimeContext.getState(new ValueStateDescriptor[Boolean]("ispayed-state", classOf[Boolean]))
override def processElement(value: OrderEvent, ctx: KeyedProcessFunction[Long, OrderEvent, OrderResult]#Context, out: Collector[OrderResult]): Unit = {
val isPayed = isPayedState.value()
if (value.eventType == "create" && !isPayed) {
ctx.timerService().registerEventTimeTimer(value.eventTime * 1000L + 15 * 60 *1000L)
} else if (value.eventType == "pay") {
isPayedState.update(true)
}
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Long, OrderEvent, OrderResult]#OnTimerContext, out: Collector[OrderResult]): Unit = {
val isPayed = isPayedState.value()
if (!isPayed) {
out.collect(OrderResult(ctx.getCurrentKey, "order timeout"))
}
isPayedState.clear()
}
}
}
来自两条流的订单交易匹配
对于订单支付事件,用户支付完成其实并不算完,我们还得确认平台账户上是否到账了。而往往这会来自不同的日志信息,所以我们要同时读入两条流的数据来做合并处理。 这里我们利用 connect 将两条流进行连接,然后用自定义的 CoProcessFunction 进行处理。
具体代码如下:
TxMatchDetect/src/main/scala/TxMatch
case class OrderEvent( orderId: Long, eventType: String, txId: String, eventTime: Long )
case class ReceiptEvent( txId: String, payChannel: String, eventTime: Long )
object TxMatch {
val unmatchedPays = new OutputTag[OrderEvent]("unmatchedPays")
val unmatchedReceipts = new OutputTag[ReceiptEvent]("unmatchedReceipts")
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val orderEventStream = env.readTextFile("YOUR_PATH\\resources\\OrderLog.csv")
.map( data => {
val dataArray = data.split(",")
OrderEvent(dataArray(0).toLong, dataArray(1), dataArray(2), dataArray(3).toLong)
})
.filter(_.txId != "")
.assignAscendingTimestamps(_.eventTime * 1000L)
.keyBy(_.txId)
val receiptEventStream = env.readTextFile("YOUR_PATH\\resources\\ReceiptLog.csv")
.map( data => {
val dataArray = data.split(",")
ReceiptEvent(dataArray(0), dataArray(1), dataArray(2).toLong)
})
.assignAscendingTimestamps(_.eventTime * 1000L)
.keyBy(_.txId)
val processedStream = orderEventStream
.connect(receiptEventStream)
.process(new TxMatchDetection)
processedStream.getSideOutput(unmatchedPays).print("unmatched pays")
processedStream.getSideOutput(unmatchedReceipts).print("unmatched receipts")
processedStream.print("processed")
env.execute()
}
class TxMatchDetection extends CoProcessFunction[OrderEvent, ReceiptEvent, (OrderEvent, ReceiptEvent)]{
lazy val payState: ValueState[OrderEvent] = getRuntimeContext.getState(new ValueStateDescriptor[OrderEvent]("pay-state",classOf[OrderEvent]) )
lazy val receiptState: ValueState[ReceiptEvent] = getRuntimeContext.getState(new ValueStateDescriptor[ReceiptEvent]("receipt-state", classOf[ReceiptEvent]) )
override def processElement1(pay: OrderEvent, ctx: CoProcessFunction[OrderEvent, ReceiptEvent, (OrderEvent, ReceiptEvent)]#Context, out: Collector[(OrderEvent, ReceiptEvent)]): Unit = {
val receipt = receiptState.value()
if( receipt != null ){
receiptState.clear()
out.collect((pay, receipt))
} else{
payState.update(pay)
ctx.timerService().registerEventTimeTimer(pay.eventTime * 1000L)
}
}
override def processElement2(receipt: ReceiptEvent, ctx: CoProcessFunction[OrderEvent, ReceiptEvent, (OrderEvent, ReceiptEvent)]#Context, out: Collector[(OrderEvent, ReceiptEvent)]): Unit = {
val payment = payState.value()
if( payment != null ){
payState.clear()
out.collect((payment, receipt))
} else{
receiptState.update(receipt)
ctx.timerService().registerEventTimeTimer(receipt.eventTime * 1000L)
}
}
override def onTimer(timestamp: Long, ctx: CoProcessFunction[OrderEvent, ReceiptEvent, (OrderEvent, ReceiptEvent)]#OnTimerContext, out: Collector[(OrderEvent, ReceiptEvent)]): Unit = {
if ( payState.value() != null ){
ctx.output(unmatchedPays, payState.value())
}
if ( receiptState.value() != null ){
ctx.output(unmatchedReceipts, receiptState.value())
}
payState.clear()
receiptState.clear()
}
}
}
4、电商常见指标汇总
现在的电子商务:
1、大多买家通过搜索找到所买物品,而非电商网站的内部导航,搜索关键字更为重要;
2、电商商家通过推荐引擎来预测买家可能需要的商品。推荐引擎以历史上具有类似购买记录的买家数据以及用户自身的购买记录为基础,向用户提供推荐信息;
3、电商商家时刻优化网站性能,如 A/B Test 划分来访流量,并区别对待来源不同的访客,进而找到最优的产品、内容和价格;
4、购买流程早在买家访问网站前,即在社交网络、邮件以及在线社区中便已开始,即长漏斗流程(以一条推文、一段视频或一个链接开始,以购买交易结束)。
相关数据指标:关键词和搜索词、推荐接受率、邮件列表/短信链接点入率
电商 8 类基本指标
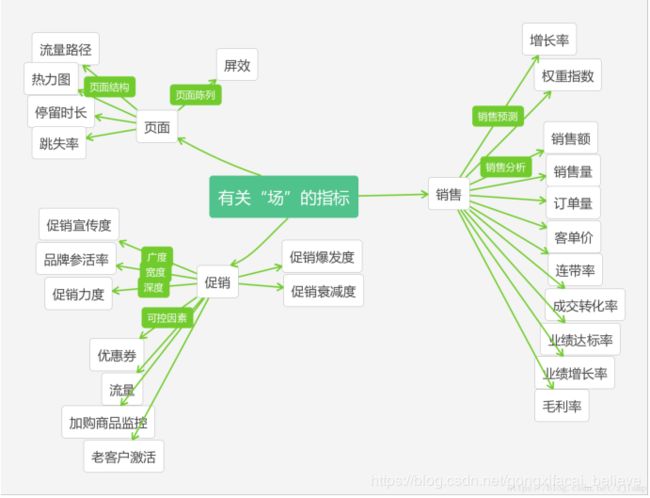
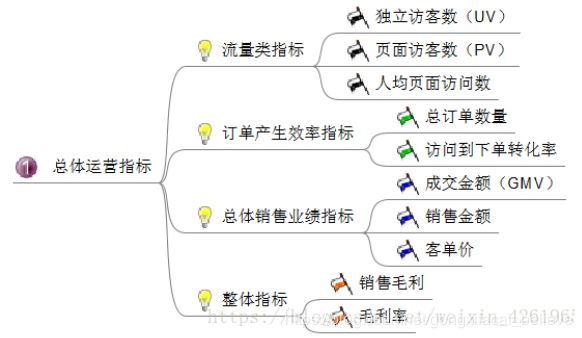
1、总体运营指标:从流量、订单、总体销售业绩、整体指标进行把控,起码对运营的电商平台有个大致了解,到底运营的怎么样,是亏是赚。
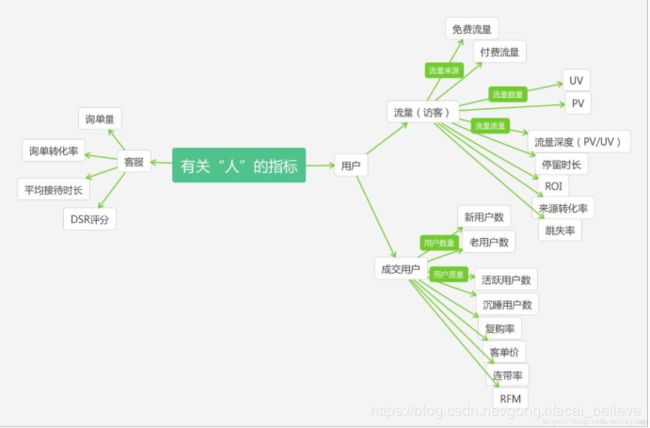
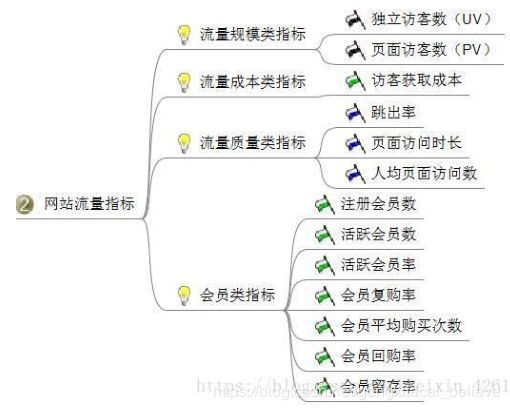
2、站流量指标:即对访问你网站的访客进行分析,基于这些数据可以对网页进行改进,以及对访客的行为进行分析等等。
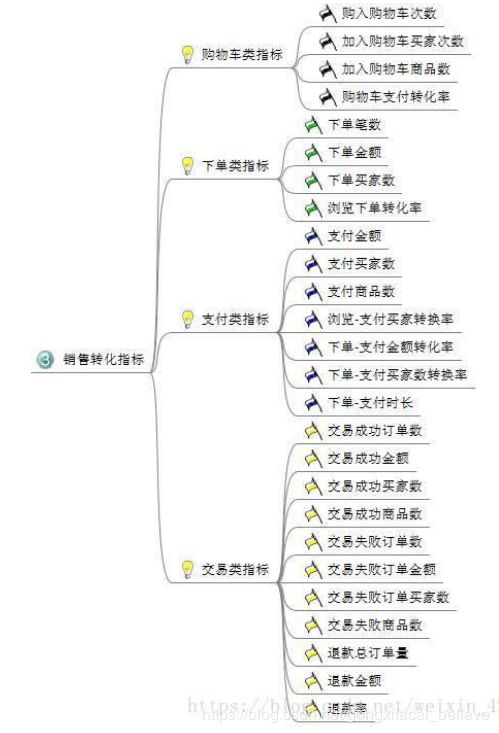
3、销售转化指标:分析从下单到支付整个过程的数据,帮助你提升商品转化率。也可以对一些频繁异常的数据展开分析。
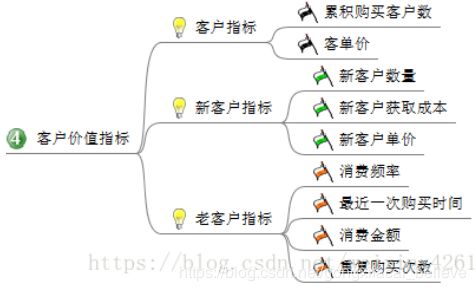
4、客户价值指标:这里主要就是分析客户的价值,可以建立 RFM 价值模型,找出那些有价值的客户,精准营销等等。
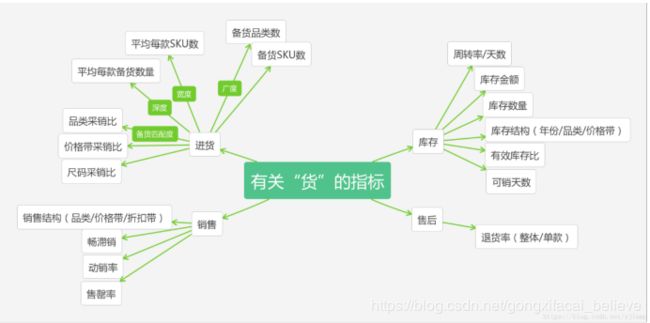
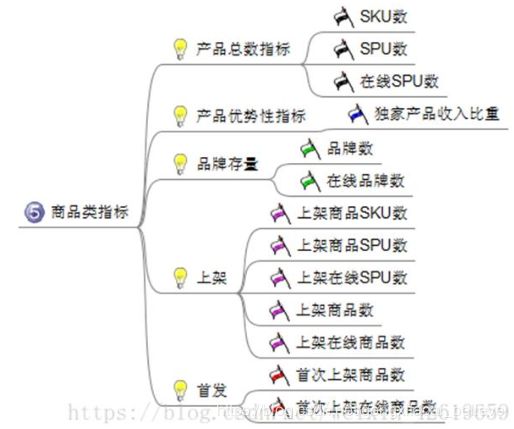
5、商品类指标:主要分析商品的种类,那些商品卖得好,库存情况,以及可以建立关联模型,分析那些商品同时销售的几率比较高,而进行捆绑销售,有点像啤酒和尿布的故事。
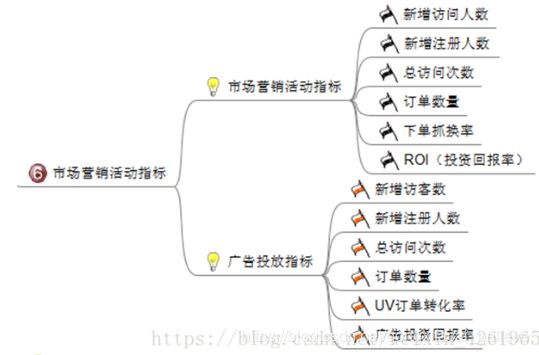
6、市场营销活动指标,主要监控某次活动给电商网站带来的效果,以及监控广告的投放指标。
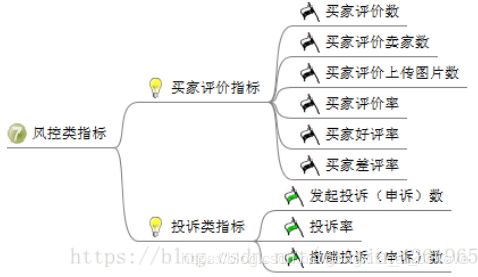
7、风控类指标:分析卖家评论,以及投诉情况,发现问题,改正问题。
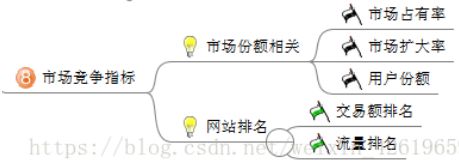
8、市场竞争指标:主要分析市场份额以及网站排名,进一步进行调整。