Sklearn到底是什么?
更多详细代码关注sklearn中文官方文档:
http://www.scikitlearn.com.cn/
http://lijiancheng0614.github.io/scikit-learn/index.html
1.概念
Sklearn (全称 Scikit-Learn) 是基于 Python 语言的机器学习工具,是机器学习中的常用第三方模块。它建立在 NumPy, SciPy, Pandas 和 Matplotlib 之上,里面的 API 的设计非常好,所有对象的接口简单,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法。
2.方法
2.1有监督学习的分类任务(Classification)

分类算法:
from sklearn import SomeClassifier
from sklearn.linear_model import SomeClassifier
from sklearn.ensemble import SomeClassifier2.2有监督学习的回归任务(Regression)

回归算法:
from sklearn import SomeRegressor
from sklearn.linear_model import SomeRegressor
from sklearn.ensemble import SomeRegressor2.3无监督学习聚类任务(Clustering)

聚类算法:
from sklearn.cluster import SomeModel2.4无监督学习的降维任务(Dimensionality Reduction)

from sklearn.decomposition import SomeModel2.5模型选择任务(Model Selection)

from sklearn.model_selection import SomeModel2.6数据的预处理任务(Preprocessing)


from sklearn.preprocessing import SomeModel2.7引入某个数据集
from sklearn.datasets import SomeData3.部分代码详细分析
3.1自带的数据集
例如导入乳腺癌数据集:
#导入乳腺癌数据集
from sklearn.datasets import load_breast_cancer数据是以「字典」格式存储的,详细查看一下里面的键:
breast = load_breast_cancer()
print(breast.keys())结果:
![]()
键的名词解释:
-
data:特征值 (数组)
-
target:标签值 (数组)
-
target_names:标签 (列表)
-
DESCR:数据集描述
-
feature_names:特征 (列表)
-
filename:iris.csv 文件路径
详细查看一下数据集:
#定义两个分别为数据集的样例个数、特征个数
n_samples,n_features = breast.data.shape
#输出数据集的样例个数和特征个数,类似数据集的规模
print(n_samples,n_features)
#输出数据集的特征名称
print(breast.feature_names)
#输出数据集的前5个特征示例
print(breast.data[0:5])可以看到输出分别为——样例个数以及特征个数:
![]()
数据集中30个特征的名称为:
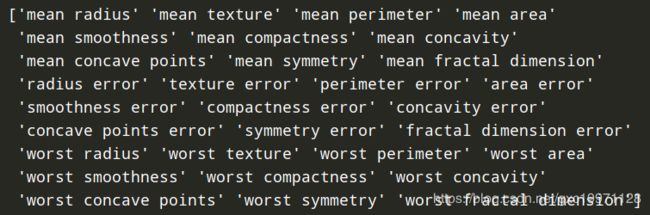
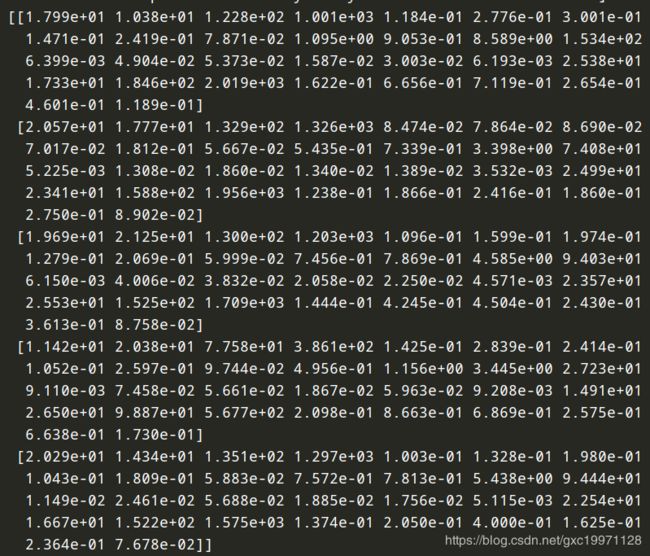
前五个示例为(每一个示例中都有30个数据,分别对应30个特征):
输出数据集的标签大小:
#输出数据集的标签数量(也就是最后的那个是乳腺癌良性还是恶性):
print(breast.target.shape)![]()
输出数据集标签名称看看:
#输出数据集标签名称:
print(breast.target_names)![]()
输出全部标签示例:
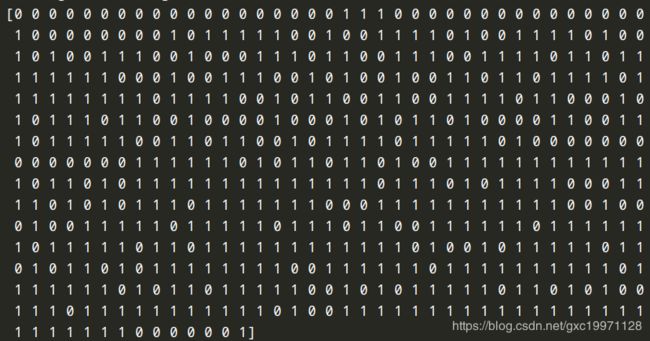
即数据集中有569个标签,2个类别(malignant恶性、benign良性),分别用0和1来表示。
使用pandas下的工具DataFrame来把数据集创建成表格来读取数据集中的详细数据
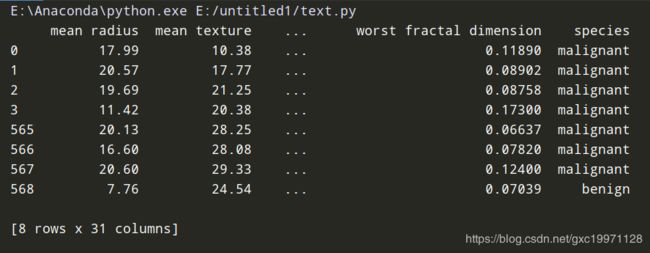
Seaborn 的 pairplot (看每个特征之间的关系)来用图来展示一下数据集的内容。
import seaborn as sns
from matplotlib import pyplot as plt
sns.pairplot(breast_data,hue='species',palette='husl');
plt.show()