【数据挖掘】决策树中根据 信息增益 确定划分属性 ( 信息与熵 | 总熵计算公式 | 每个属性的熵计算公式 | 信息增益计算公式 | 划分属性确定 )
文章目录
- I . 决策树 树根属性 选择
- II . 信息增益 示例说明
- III . 信息增益 计算步骤
- IV . 信息增益 计算使用的数据集 S
- V . 信息增益 计算公式 已知条件
- VI . 信息增益 总熵 计算公式
- VII . 信息增益 每个属性的熵 计算公式
- VIII . 信息增益 计算公式
- IX . 信息增益计算 案例
- X . 信息增益计算 递归确定 划分属性
I . 决策树 树根属性 选择
1 . 属性选择方法 : 树根属性选择的方法很多 , 这里介绍一种常用的方法 , 信息增益 ;
2 . 信息增益 : 信息增益 效果越大 , 其作为树根属性 , 划分的数据集分类效果越明显 ;
3 . 信息 和 熵 : 涉及 信息论 的知识点 , 建议有空就去 B站 刷一下信息论课程 ;
① 信息 与 熵 的关系 : 信息 会 消除 熵 , 熵 代表了不确定性 , 信息用来消除不确定性 ;
② 信息增益 : 信息增益大的属性 , 能最大消除熵的不确定性 ;
4 . 决策树中的信息增益 : 属性的 信息增益 越大 , 就越能将分类效果达到最大 ;
如 : 想要从用户数据集中找到是否能买奢侈品的用户 , 先把高收入群体划分出来 , 将低收入者从数据集中去除 , 这个收入水平的属性 ( 特征 ) , 信息增益就很大 ;
II . 信息增益 示例说明
1 . 熵 和 信息 的数据组成 :
① 数据集 ( 熵 ) : 给定一个总的数据集如 100 个用户数据 , 要从里面选择购买奢侈品的 1 个用户 ( 高收入 , 30 岁以下 ) ;
② 年龄属性 ( 信息 ) : 30 岁以上的 50 个 , 30 岁以下的 50 个 ;
③ 收入属性 ( 信息 ) : 高收入 10 个 , 低收入 90 个 ;
2 . 信息增益分析 :
① 收入属性的信息增益 : 熵是 100 个用户数据 , 代表不确定性 ; 根据收入属性来划分 , 将高收入者 10 个用户划分出来 , 买奢侈品的用户从这 10 个中选择 ; 由 100 个用户中选 1 个用户 , 变为 10 个用户中选择 1 个用户 ; 消除了 90 个用户的不确定性 ;
② 年龄属性的信息增益 : 熵是 100 个用户数据 , 代表不确定性 ; 根据收入属性来划分 , 将30 岁以下的 50 个用户划分出来 , 买奢侈品的用户从这 50 个中选择 ; 由 100 个用户中选 1 个用户 , 变为 50 个用户中选择 1 个用户 ; 消除了 50 个用户的不确定性 ;
③ 信息增益分析 : 明显 收入属性 的信息增益要高于 年龄属性 的信息增益 ;
III . 信息增益 计算步骤
信息增益计算步骤 :
1 . 总熵 : 不考虑 输入变量 ( 属性 / 特征 ) , 为数据集 S 中的某个数据样本进行分类 , 计算出该过程的熵 ( 不确定性 ) , 用 Entropy(S) 表示 ;
2 . 引入属性后的熵 : 使用 输入变量 ( 属性 / 特征 ) X 后 , 为数据集 S 中的某个数据样本进行分类 , 计算出该过程的熵 ( 不确定性 ) , 用 Entropy(X , S) 表示 ;
3 . 信息增益 : 上面 Entropy(X , S) - Entropy(S) 的差 , 就是 X 属性 ( 特征 ) 带来的信息增益 , 用 Gain(X , S) 表示 ;
IV . 信息增益 计算使用的数据集 S
数据集 : 根据 年龄 , 收入水平 , 是否是学生 , 信用等级 , 预测该用户是否会购买商品 ;
① 是否会购买商品 : 9 个 会购买 , 5 个不会购买 ;
② 年龄 ( 属性 ) :
5 个小于 30 岁的人中 , 3 个不会买电脑 , 有 2 个会买商品 ;
4 个 31 ~ 39 岁的人中 , 0 个不会买电脑 , 有 4 个会买商品 ;
5 个 大于 40 岁的人中 , 2 个不会买电脑 , 有 3 个会买商品 ;
| 年龄 | 收入水平 | 是否是学生 | 信用等级 | 是否购买商品 |
|---|---|---|---|---|
| 小于 30 岁 | 高收入 | 不是 | 一般 | 不会 |
| 小于 30 岁 | 高收入 | 不是 | 很好 | 不会 |
| 31 ~ 39 岁 | 高收入 | 不是 | 一般 | 会 |
| 40 岁以上 | 中等收入 | 不是 | 一般 | 会 |
| 40 岁以上 | 低收入 | 是 | 一般 | 会 |
| 40 岁以上 | 低收入 | 是 | 很好 | 不会 |
| 31 ~ 40 岁 | 低收入 | 不是 | 很好 | 会 |
| 小于 30 岁 | 中等收入 | 不是 | 一般 | 不会 |
| 小于 30 岁 | 低收入 | 是 | 一般 | 会 |
| 40 岁以上 | 中等收入 | 是 | 一般 | 会 |
| 小于 30 岁 | 中等收入 | 是 | 很好 | 会 |
| 31 ~ 39 岁 | 中等收入 | 不是 | 很好 | 会 |
| 31 ~ 39 岁 | 高收入 | 是 | 一般 | 会 |
| 40 岁以上 | 中等收入 | 不是 | 很好 | 不会 |
V . 信息增益 计算公式 已知条件
1 . 已知条件 ( 变量声明 ) : 声明一些计算公式中使用的变量 ;
① 总的数据集 : S S S
② 最终分类个数 : m m m , 最终分成 m m m 个类别 , 如 是否购买商品 ( 是 , 否 ) , 就是分成 2 2 2 类 , m = 2 m = 2 m=2 ;
③ 分类表示 : C i ( i = 1 , ⋯ , m ) C_i ( i = 1 , \cdots , m ) Ci(i=1,⋯,m) , 如 : 是否购买商品 ( 是 , 否 ) , C 1 C_1 C1 表示 是 , C 2 C_2 C2 表示 否 ;
④ 分类样本个数 : s i ( i = 1 , ⋯ , m ) s_i ( i = 1 , \cdots , m ) si(i=1,⋯,m) , 如 : 是否购买商品 , 会购买的 ( C 1 C_1 C1 ) 的样本个数是 9 人 , 表示为 s 1 = 9 s_1 = 9 s1=9 ;
VI . 信息增益 总熵 计算公式
1 . 计算总熵公式 :
E n t r o p y ( S ) = − ∑ i = 1 m s i s l o g 2 s i s Entropy(S)=- \sum_{i=1}^{m} \frac{s_i}{s} log_2 \frac{s_i}{s} Entropy(S)=−i=1∑mssilog2ssi
2 . 公式解析 :
① 加和式 : 这是一个 1 1 1 到 m m m 的加和式 ;
② 比值权重 : s i s \frac{s_i}{s} ssi 表示第 i i i 个样本数 ( s i s_i si ) 与 总样本数 ( s s s) 比值 ;
3 . 计算示例 :
① 需求 : 判定 14 个用户是否会购买某商品 , 9 个会购买 , 5 个不购买 ;
② 计算过程 :
E n t r o p y ( S ) = − ∑ i = 1 m s i s l o g 2 s i s = − 9 14 l o g 2 9 14 − 5 14 l o g 2 5 14 \begin{array}{lcl} Entropy(S) &=&- \sum_{i=1}^{m} \frac{s_i}{s} log_2 \frac{s_i}{s} \\ \\ &=& - \frac{9}{14} log_2 \frac{9}{14} - \frac{5}{14} log_2 \frac{5}{14} \end{array} Entropy(S)==−∑i=1mssilog2ssi−149log2149−145log2145
VII . 信息增益 每个属性的熵 计算公式
1 . 计算熵的属性 : 属性 A A A 的值为 { a 1 , a 2 , ⋯ , a v } \{ a_1 , a_2 , \cdots, a_v \} {a1,a2,⋯,av} ;
2 . 引入 属性 ( 特征 ) A 后 的熵计算公式 :
E n t r o p y ( A , S ) = ∑ j = 1 v s j s E n t r o p y ( S j ) Entropy(A ,S)= \sum_{j=1}^{v} \frac{s_j}{s} Entropy(Sj) Entropy(A,S)=j=1∑vssjEntropy(Sj)
3 . 公式解析 :
① 剩余的熵 : 引入属性 A A A 后 , 属性 A A A 是信息 , 信息会消除熵 , 这里计算消除后剩余的熵是多少 ;
② 属性解析 : 这是一个 1 1 1 到 v v v 的加和式 , v v v 表示 A A A 属性的取值个数 , 如 : A A A 表示年龄 , 有 : 30岁以下( a 1 a_1 a1 ) 有 5 个样本 , 31 ~ 39 岁 ( a 2 a_2 a2 ) 有 4 个样本 , 40 岁以上( a 3 a_3 a3 ) 有 5 个样本 , v = 3 v = 3 v=3 ;
③ 系数说明 : 其中 s j s \frac{s_j}{s} ssj 系数 表示 , 属性 A ( 年龄特征 ) 的第 j j j 个版本的比例 , 这个比例越高 , 样本对多 , 越重要 ;
4 . 属性的熵 计算示例 :
E n t r o p y ( A , S ) = ∑ j = 1 v E n t r o p y ( S j ) = 5 14 E n t r o p y ( 2 , 3 ) + 4 14 E n t r o p y ( 4 , 0 ) + 5 14 E n t r o p y ( 3 , 2 ) \begin{array}{lcl} Entropy(A ,S) &=& \sum_{j=1}^{v} Entropy(Sj) \\ \\ &=& \frac{5}{14}Entropy(2 , 3) + \frac{4}{14}Entropy(4 , 0) + \frac{5}{14}Entropy(3 , 2) \\ \\ \end{array} Entropy(A,S)==∑j=1vEntropy(Sj)145Entropy(2,3)+144Entropy(4,0)+145Entropy(3,2)
5 . 计算过程解析 :
① 5 14 E n t r o p y ( 2 , 3 ) \frac{5}{14}Entropy(2 , 3) 145Entropy(2,3) 在 5 个 小于 30 岁的人中 , 有 2 个会买商品 , 3 个不会买商品 ;
② 4 14 E n t r o p y ( 4 , 0 ) \frac{4}{14}Entropy(4 , 0) 144Entropy(4,0) 在 4 个 31 ~ 39 岁的人中 , 有 4 个会买商品 , 0 个不会买商品 ;
③ 5 14 E n t r o p y ( 3 , 2 ) \frac{5}{14}Entropy(3 , 2) 145Entropy(3,2) 在 5 个 大于 40 岁的人中 , 有 3 个会买商品 , 2 个不会买商品 ;
VIII . 信息增益 计算公式
计算 A A A 属性的信息增益 :
G a i n ( A , S ) = E n t r o p y ( S ) − E n t r o p y ( A , S ) Gain ( A , S ) = Entropy(S) - Entropy(A ,S) Gain(A,S)=Entropy(S)−Entropy(A,S)
IX . 信息增益计算 案例
1 . 已知数据 :
① 数据集 : 计算 上述数据集 S S S 的信息增益 , 该数据集 S S S 有 14 个样本数据 ;
② 数据集属性 : 数据集 S S S 有 5 5 5 个属性 , 年龄 , 收入 , 是否是学生 , 信用等级 , 是否购买商品 ;
③ 预测属性 : 根据 年龄 , 收入 , 是否是学生 , 信用等级 4 4 4 个属性 , 预测 是否购买商品 这个属性 ;
2 . 总熵计算 :
① 总熵 : 计算每个属性的信息增益 , 先要使用 E n t r o p y ( S ) Entropy(S) Entropy(S) 公式计算出总熵 ;
① 预测属性分析 : 最后预测的属性是 是否购买电脑 , 有两个取值 , 是 或 否 , 2 2 2 个取值 , 计算总熵时 , 需要计算两项 , 分别计算 取值 会买电脑 和 不会买电脑的 熵 ;
③ 属性的具体分类 : 判定 14 个用户是否会购买某商品 , 9 个会购买 , 5 个不购买 ;
④ 计算过程 :
E n t r o p y ( S ) = − ∑ i = 1 2 s 1 s l o g 2 s 2 s = − 9 14 l o g 2 9 14 − 5 14 l o g 2 5 14 = 0.940 \begin{array}{lcl} Entropy(S) &=&- \sum_{i=1}^{2} \frac{s_1}{s} log_2 \frac{s_2}{s} \\\\ &=& - \frac{9}{14} log_2 \frac{9}{14} - \frac{5}{14} log_2 \frac{5}{14} \\\\ &=& 0.940 \end{array} Entropy(S)===−∑i=12ss1log2ss2−149log2149−145log21450.940
3 . 计算 年龄 属性的熵 :
① 引入属性 : 引入 年龄 属性 后 , 年龄 属性 是信息 , 信息会消除熵 , 这里计算引入 年龄 属性 之后的熵是多少 ;
② 年龄属性分析 : 年龄属性有 3 种取值 : 30岁以下有 5 个样本 , 31 ~ 39 岁有 4 个样本 , 40 岁以上有 5 个样本 ;
③ 计算内容 :
需要分别计算 3 种取值的熵各是多少 ,
30岁以下有 5 个样本 , 需要计算这 5 个样本的熵是多少 , 5 个样本 , 有 3 个人买商品 , 2 个人不买商品 ,
④ 计算示例 :
E n t r o p y ( A , S ) = ∑ j = 1 3 E n t r o p y ( S j ) = 5 14 E n t r o p y ( 2 , 3 ) + 4 14 E n t r o p y ( 4 , 0 ) + 5 14 E n t r o p y ( 3 , 2 ) = 0.694 \begin{array}{lcl} Entropy(A ,S) &=& \sum_{j=1}^{3} Entropy(Sj) \\ \\ &=& \frac{5}{14}Entropy(2 , 3) + \frac{4}{14}Entropy(4 , 0) + \frac{5}{14}Entropy(3 , 2) \\ \\ &=& 0.694 \end{array} Entropy(A,S)===∑j=13Entropy(Sj)145Entropy(2,3)+144Entropy(4,0)+145Entropy(3,2)0.694
5 14 E n t r o p y ( 2 , 3 ) \frac{5}{14}Entropy(2 , 3) 145Entropy(2,3) 在 5 个 小于 30 岁的人中 , 有 2 个会买商品 , 3 个不会买商品 ;
4 14 E n t r o p y ( 4 , 0 ) \frac{4}{14}Entropy(4 , 0) 144Entropy(4,0) 在 4 个 31 ~ 39 岁的人中 , 有 4 个会买商品 , 0 个不会买商品 ;
5 14 E n t r o p y ( 3 , 2 ) \frac{5}{14}Entropy(3 , 2) 145Entropy(3,2) 在 5 个 大于 40 岁的人中 , 有 3 个会买商品 , 2 个不会买商品 ;
4 . 计算每个 属性 不同样本取值的熵 :
① 计算 E n t r o p y ( 2 , 3 ) Entropy(2 , 3) Entropy(2,3) : 5 个人 , 有 2 个人买商品 , 3 个人没有买商品 ;
E n t r o p y ( 2 , 3 ) = − ∑ i = 1 m s 1 s l o g 2 s 2 s = − ∑ i = 1 2 s 1 s l o g 2 s 2 s = − 2 5 l o g 2 2 5 − 3 5 l o g 2 3 5 \begin{array}{lcl} Entropy(2 , 3) &=& - \sum_{i=1}^{m} \frac{s_1}{s} log_2 \frac{s_2}{s} \\\\ &=& - \sum_{i=1}^{2} \frac{s_1}{s} log_2 \frac{s_2}{s} \\\\ &=& - \frac{2}{5} log_2 \frac{2}{5} - \frac{3}{5} log_2 \frac{3}{5} \end{array} Entropy(2,3)===−∑i=1mss1log2ss2−∑i=12ss1log2ss2−52log252−53log253
② 计算 E n t r o p y ( 4 , 0 ) Entropy(4 , 0) Entropy(4,0) : 4 个人 , 有 4 个人买商品 , 0 个人没有买商品 ;
E n t r o p y ( 4 , 0 ) = − ∑ i = 1 m s 1 s l o g 2 s 2 s = − ∑ i = 1 2 s 1 s l o g 2 s 2 s = − 4 4 l o g 2 4 4 − 0 4 l o g 2 0 4 \begin{array}{lcl} Entropy(4 , 0) &=& - \sum_{i=1}^{m} \frac{s_1}{s} log_2 \frac{s_2}{s} \\\\ &=& - \sum_{i=1}^{2} \frac{s_1}{s} log_2 \frac{s_2}{s} \\\\ &=& - \frac{4}{4} log_2 \frac{4}{4} - \frac{0}{4} log_2 \frac{0}{4} \end{array} Entropy(4,0)===−∑i=1mss1log2ss2−∑i=12ss1log2ss2−44log244−40log240
③ 计算 E n t r o p y ( 3 , 2 ) Entropy(3 , 2) Entropy(3,2) : 5 个人 , 有 3 个人买商品 , 2 个人没有买商品 ;
E n t r o p y ( 3 , 2 ) = − ∑ i = 1 m s 1 s l o g 2 s 2 s = − ∑ i = 1 2 s 1 s l o g 2 s 2 s = − 3 5 l o g 2 3 5 − 2 5 l o g 2 2 5 \begin{array}{lcl} Entropy(3 , 2) &=& - \sum_{i=1}^{m} \frac{s_1}{s} log_2 \frac{s_2}{s} \\\\ &=& - \sum_{i=1}^{2} \frac{s_1}{s} log_2 \frac{s_2}{s} \\\\ &=& - \frac{3}{5} log_2 \frac{3}{5} - \frac{2}{5} log_2 \frac{2}{5} \end{array} Entropy(3,2)===−∑i=1mss1log2ss2−∑i=12ss1log2ss2−53log253−52log252
5 . 计算年龄属性的信息增益 :
G a i n ( A , S ) = E n t r o p y ( S ) − E n t r o p y ( A , S ) = 5 14 E n t r o p y ( 2 , 3 ) + 4 14 E n t r o p y ( 4 , 0 ) + 5 14 E n t r o p y ( 3 , 2 ) − ( − 3 5 l o g 2 3 5 − 2 5 l o g 2 2 5 ) = 0.246 \begin{array}{lcl} Gain ( A , S ) &=& Entropy(S) - Entropy(A ,S) \\\\ &=& \frac{5}{14}Entropy(2 , 3) + \frac{4}{14}Entropy(4 , 0) + \frac{5}{14}Entropy(3 , 2) - ( - \frac{3}{5} log_2 \frac{3}{5} - \frac{2}{5} log_2 \frac{2}{5} ) \\\\ &=& 0.246 \end{array} Gain(A,S)===Entropy(S)−Entropy(A,S)145Entropy(2,3)+144Entropy(4,0)+145Entropy(3,2)−(−53log253−52log252)0.246
6 . 依次计算 各个属性的 熵 :
① 年龄 属性的信息增益 : G a i n ( 年 龄 ) = 0.246 Gain ( 年龄 ) = 0.246 Gain(年龄)=0.246
② 收入 属性的信息增益 : G a i n ( 收 入 ) = 0.029 Gain ( 收入 ) = 0.029 Gain(收入)=0.029
③ 是否是学生 属性的信息增益 : G a i n ( 是 否 是 学 生 ) = 0.151 Gain ( 是否是学生 ) = 0.151 Gain(是否是学生)=0.151
④ 信用等级 属性的信息增益 : G a i n ( 信 用 等 级 ) = 0.048 Gain ( 信用等级 ) = 0.048 Gain(信用等级)=0.048
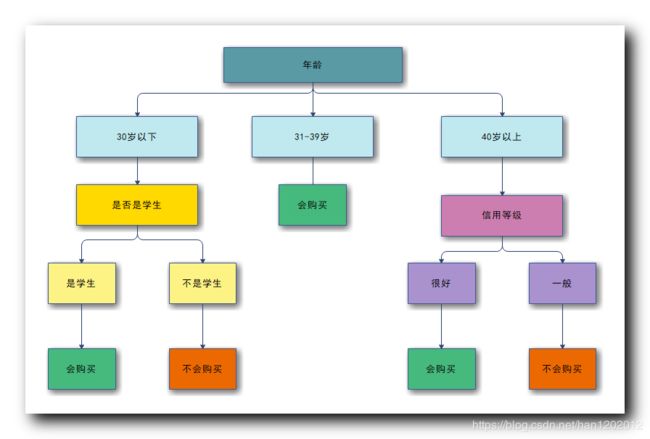
⑤ 树根 属性选择: 年龄属性的 信息增益 最大 , 选择年龄属性作为树根 ;
7 . 后续工作 ( 重要 ) : 选择完树根后 , 树根属性将数据分为不同的子集 , 每个子集再计算剩余的 3 个属性 , 哪个属性的信息增益最大 , 就选那个属性作为子树的树根属性 ;
X . 信息增益计算 递归确定 划分属性
1 . 计算公式使用 : 根据上述公式 , 计算出每个属性的信息增益 , 递归选取信息增益最大的作为树根 ;
2 . 决策树创建算法 ( 递归 ) : 使用递归算法 , 递归算法分为递归操作 和 递归停止条件 ;
3 . 递归操作 : 每个步骤先选择属性 , 选择好属性后 , 根据 总树 ( 子树 ) 的树根属性划分训练集 ;
① 选择属性 : 递归由上到下决定每一个节点的属性 , 依次递归构造决策树 ;
② 数据集划分 : 开始决策时 , 所有的数据都在树根 , 由树根属性来划分数据集 ;
③ 属性离散化 : 如果属性的值是连续值 , 需要将连续属性值离散化 ; 如 : 100 分满分 , 将 60 分以下分为不及格数据 , 60 分以上分为及格数据 ;
4 . 递归停止的条件 :
① 子树分类完成 : 节点上的子数据集都属于同一个类别 , 该节点就不再向下划分 , 称为叶子节点 ;
② 属性 ( 节点 ) 全部分配完毕 : 所有的属性都已经分配完毕 , 决策树的高度等于属性个数 ;
③ 所有样本分类完毕 : 所有的样本数据集都分类完成 ;
5 . 下图是最终的决策树样式 :