【Python程序设计(七)】文件和数据格式化
文章目录
- 1 文件的使用
- 1.1 文件的类型
- 1.2 文件的打开和关闭
- 1.3 文件内容的读取
- 1.4 数据的文件写入
- 2 实例: 自动轨迹绘制
- 3 一维数据的格式化和处理
- 3.1 一维数据的表示
- 3.2 一维数据的存储
- 3.3 一维数据的处理
- 4 二维数据的格式化和处理
- 4.1 二维数据的表示
- 4.2 CSV 数据存储格式
- 4.3 二维数据的处理
- 5 wordcloud 库的使用
- 5.1 安装及使用
- 5.2 应用实例
- 6 实例: 政府工作报告词云
- 7 小结
1 文件的使用
1.1 文件的类型
文件是数据的抽象和集合,有文本文件和二进制文件两种,文件文件和二进制文件只是文件的展示方式,本质上,所有文件都是二进制形式存储。
文本文件由单一特定编码组成,如 UTF-8编码,由于存在编码,也被看成是存储着的长字符串,如 .txt文件、.py 文件。二进制文件直接由比特 0 和 1 组成,没有统一字符编码,如 .png文件、.avi 文件等。
example:
#文本形式打开文件
tf = open("data.txt", 'rt')
print(tf.readline())
tf.close()
中国是个伟大的国家!
#二进制形式打开文件
bf = open("f.txt", "rb")
print(bf.readline())
bf.close()
b'\xd6\xd0\xb9\xfa\xca\xc7\xb8\xf6\xce\xb0\xb4\xf3\xb5\xc4\xb9\xfa\xbc\xd2\xa3\xa1'
1.2 文件的打开和关闭
文件处理的步骤:打开-操作-关闭

文件使用 open() 函数打开,第一个参数为文件名,可以使用绝对路径也可以使用相对路径,如果源文件和需要打开的文件在同一个文件夹中,路径可以省略。如下所示:

第二个参数为打开模式
| 文件的打开模式 | 描述 |
|---|---|
| ‘r’ | 只读模式,默认值,如果文件不存在,返回 FileNotFoundError |
| ‘w’ | 覆盖写模式,文件不存在则创建,存在则完全覆盖 |
| ‘x’ | 创建写模式,文件不存在则创建,存在则返回 FileExistsError |
| ‘a’ | 追加写模式,文件不存在则创建,存在则在文件最后追加内容 |
| ‘b’ | 二进制文件模式 |
| ‘t’ | 文本文件模式,默认值 |
| ‘+’ | 与 r/w/x/a 一同使用,在原功能基础上增加同时读写功能 |
example:

文件的关闭:<变量名>.close()
1.3 文件内容的读取
| 操作方法 | 描述 |
|---|---|
| 读入全部内容,如果给出参数,读入前 size 长度 >>>s = f.read(2) 中国 |
|
| 读入一行内容,如果给出参数,读入该行前size长度 >>>s = f.readline() 中国是一个伟大的国家! |
|
| 读入文件所有行,以每行为元素形成列表 如果给出参数,读入前 hint 行 >>>s = f.readlines() [‘中国是一个伟大的国家!’] |
文件的全文本操作和逐行操作如下:

1.4 数据的文件写入
| 操作方法 | 描述 |
|---|---|
| 向文件写入一个字符串或字节流 >>>f.write(“中国是一个伟大的国家!”) |
|
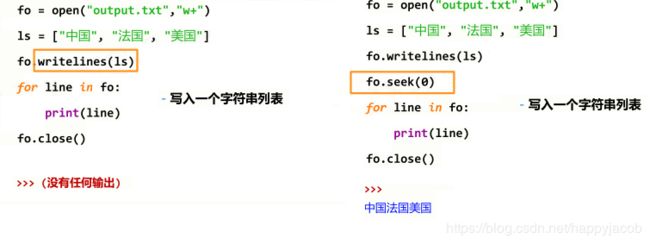
| 将一个元素全为字符串的列表写入文件 >>>ls = [“中国”, “法国”, “美国”] >>>f.writelines(ls) 中国法国美国 |
|
| 改变当前文件操作指针的位置,offset 含义如下: 0 – 文件开头; 1 – 当前位置; 2 – 文件结尾 >>>f.seek(0) #回到文件开头 |
下面两段代码向文件中写数据,第一个程序此时文件操作指针在最后面,所以向后读取不到任何数据,没有输出,需要向第段程序一样,先将文件操作指针移动到文件开头,才能读取到内容。
2 实例: 自动轨迹绘制
需求:根据脚本来绘制图形?不通过写代码而通过写数据绘制轨迹
思路:
- 步骤1:定义数据文件格式(接口)
- 步骤2:编写程序,根据文件接口解析参数绘制图形
- 步骤3:编制数据文件
数据接口定义

import turtle as t
t.title("自动轨迹绘制")
t.setup(800,600, 0, 0)
t.pencolor("red")
t.pensize(5)
datals = []
f = open("data.txt")
for line in f:
line = line.replace("\n", "")
datals.append(list(map(eval, line.split(","))))
f.close()
for i in range(len(datals)):
t.pencolor(datals[i][3], datals[i][4], datals[i][5])
t.fd(datals[i][0])
if datals[i][1]:
t.right(datals[i][2])
else:
t.left(datals[i][2])
文件 data.txt 中的数据如下:
300,0,144,1,0,0
300,0,144,0,1,0
300,0,144,0,0,1
300,0,144,1,1,0
300,0,108,0,1,1
184,0,72,1,0,1
184,0,72,0,0,0
184,0,72,0,0,0
184,0,72,0,0,0
184,1,72,1,0,1
184,1,72,0,0,0
184,1,72,0,0,0
184,1,72,0,0,0
184,1,72,0,0,0
184,1,720,0,0,0
运行结果
3 一维数据的格式化和处理
3.1 一维数据的表示
如果数据间有序使用列表类型,如果数据间无序使用集合类型
ls = [3.1398, 3.1349, 3.1376]
st = {3.1398, 3.1349, 3.1376}
列表类型和集合类型都可以表达一维数据,可以使用 for 循环可以遍历数据
3.2 一维数据的存储
可以使用空格分隔,逗号分隔和其他分隔方式
- 空格分隔:中国 美国 日本 德国 法国 英国 意大利
- 逗号分隔:中国,美国,日本,德国,法国,英国,意大利
- 其他方式:中国$美国$日本$德国$法国$英国$意大利
空格分隔使用一个或多个空格分隔进行存储,数据中不能存在空格;逗号分隔使用英文半角逗号分隔数据进行存储,数据中不能有英文逗号;其他方式采用使用其他符号或符号组合分隔,建议采用特殊符号,需要根据数据特点定义,通用性较差。
3.3 一维数据的处理
一维数据的读入处理
- 从空格分隔的文件中读入数据
data.txt 中数据:中国 美国 日本 德国 法国 英国 意大利
>>> txt = open("data.txt").read()
>>> ls = txt.split()
>>> ls
['中国', '美国', '日本', '德国', '法国', '英国', '意大利']
- 从特殊符号分隔的文件中读入数据
data.txt 中数据:中国$美国$日本$德国$法国$英国$意大利
>>> txt = open("data.txt").read()
>>> ls = txt.split("$")
>>> ls
['中国', '美国', '日本', '德国', '法国', '英国', '意大利']
一维数据的写入处理
- 采用空格分隔方式将数据写入文件
ls = ['中国', '美国', '日本']
f = open("data.txt", "w")
f.write(" ".join(ls))
f.close()
- 采用特殊分隔方式将数据写入文件
ls = ['中国', '美国', '日本']
f = open("data.txt", "w")
f.write("$".join(ls))
f.close()
4 二维数据的格式化和处理
4.1 二维数据的表示
列表类型可以表达二维数据,使用两层 for 循环遍历每个元素
[ [1, 2, 3], [4, 5, 6], [7, 8, 9] ]
4.2 CSV 数据存储格式
csv 是国际通用的一二维数据存储格式,一般.csv扩展名。每行一个一维数据,采用逗号分隔,无空行
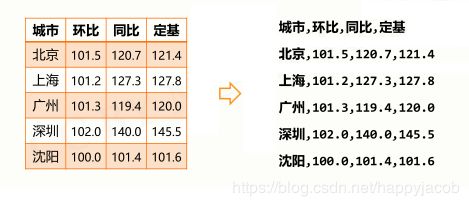
如果某个元素缺失,逗号仍要保留,逗号为英文半角逗号,逗号与数据之间无额外空格。二维数据的表头可以作为数据存储,也可以另行存储。根据一般习惯,外层列表每个元素是一行,一般索引习惯先行后列 ls[row][column]。
4.3 二维数据的处理
二维数据的读入处理,从 CSV 格式的文件中读入数据
fo = open("data.txt")
ls = []
for line in fo:
line = line.replace("\n", "")
ls.append(line.split(","))
fo.close()
二维数据的写入处理,将数据写入 CSV 格式的文件
ls = [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ]
f = open("data.txt", 'w')
for item in ls:
f.write(','.join('%s' % id for id in item) + '\n') # 整数转换为字符串
f.close()
二维数据的逐一处理,采用二层循环
ls = [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ]
for row in ls:
for col in row:
print(col)
5 wordcloud 库的使用
5.1 安装及使用
wordcloud 是优秀的词云展示第三方库,以词语为基本单位,更加直观和艺术地展示文本

安装:(cmd 命令行) pip3 install wordcloud
wordcloud 库基本使用
wordcloud 库把词云当作一个 WordCloud 对象
- wordcloud.WordCloud() 代表一个文本对应的词云
- 可以根据文本中词语出现的频率等参数绘制词云,词云的绘制形状、尺寸和颜色都可以设定
wordcloud 库常规方法
- 步骤1:配置对象参数
- 步骤2:加载词云文本
- 步骤3:输出词云文件
| 方法 | 描述 |
|---|---|
| w = wordcloud.WordCloud() | 生成词云对象 |
| w.generate(txt) | 向 WordCloud 对象 w 中加载文本 txt >>>w.generate( “Python and WordCloud” ) |
| w.to_file(filename) | 将词云输出为图像文件,.png 或 .jpg 格式 >>>w.to_file( “outfile.png” ) |
配置对象参数
w = wordcloud.WordCloud(<参数>)
| 参数 | 描述 |
|---|---|
| width | 指定词云对象生成图片的宽度,默认 400 像素 >>>w=wordcloud.WordCloud(width=600) |
| height | 指定词云对象生成图片的高度,默认 200 像素 >>>w=wordcloud.WordCloud(height=400) |
| min_font_size | 指定词云中字体的最小字号,默认 4 号 >>>w=wordcloud.WordCloud(min_font_size=10) |
| max_font_size | 指定词云中字体的最大字号,根据高度自动调节 >>>w=wordcloud.WordCloud(max_font_size=20) |
| font_step | 指定词云中字体字号的步进间隔,默认为 1 >>>w=wordcloud.WordCloud(font_step=2) |
| font_path | 指定字体文件的路径,默认 None >>>w=wordcloud.WordCloud(font_path=“msyh.ttc”) |
| max_words | 指定词云显示的最大单词数量,默认 200 >>>w=wordcloud.WordCloud(max_words=20) |
| stop_words | 指定词云的排除词列表,即不显示的单词列表 >>>w=wordcloud.WordCloud(stop_words={“Python”}) |
| mask | 指定词云形状,默认为长方形,需要引用 imread() 函数 >>>from scipy.misc import imread >>>mk=imread(“pic.png”) >>>w=wordcloud.WordCloud(mask=mk) |
| background_color | 指定词云图片的背景颜色,默认为黑色 >>>w=wordcloud.WordCloud(background_color=“white”) |
5.2 应用实例
import wordcloud
txt = "life is short, you need python"
w = wordcloud.WordCloud(background_color = "white")
w.generate(txt)
w.to_file("pycloud.png")

import jieba
import wordcloud
txt = "程序设计语言是计算机能够理解和识别用户操作意图的一种交互体系,它按照\
特定规则组织计算机指令,使计算机能够自动进行各种运算处理。"
w = wordcloud.WordCloud(width = 1000,font_path = "msyh.ttc",\
height = 700,background_color = "white")
w.generate(" ".join(jieba.lcut(txt)))
w.to_file("pycloud.png")
jieba.lcut() 函数将文本分割成列表,join() 函数将列表中的字符串使用空格连接成长字符串。

6 实例: 政府工作报告词云
需求:对于政府工作报告等政策文件,生成有效展示的词云
《决胜全面建成小康社会 夺取新时代中国特色社会主义伟大胜利》
链接:https://python123.io/resources/pye/新时代中国特色社会主义.txt
import jieba
import wordcloud
f = open("新时代中国特色社会主义.txt", "r", encoding = "utf-8")
t = f.read()
f.close()
ls = jieba.lcut(t)
txt = " ".join(ls)
w = wordcloud.WordCloud(font_path = "msyh.ttc", width = 1000, height = 700, background_color = "white")
w.generate(txt)
w.to_file("grwordcloud.png")
运行结果

生成更有形的词云,读取一个形状,新程序如下,第3,4,10行做出修改增加 import wordcloud,from imageio import imread,WordCloud 函数中增加参数 mask = mask
import jieba
import wordcloud
from imageio import imread
mask = imread("fivestar.png")
f = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")
t = f.read()
f.close()
ls = jieba.lcut(t)
txt = " ".join(ls)
w = wordcloud.WordCloud( font_path = "msyh.ttc", mask = mask, width = 1000,\
height = 700, background_color = "white")
w.generate(txt)
w.to_file("grwordcloud.png")
读取的形状

运行结果

7 小结
文件的使用
- 文件的使用方式:打开-操作-关闭
- 文本文件&二进制文件,open( , ) 和 .close()
- 文件内容的读取:.read() .readline() .readlines()
- 数据的文件写入:.write() .writelines() .seek()
一维数据的格式化和处理
- 数据的维度:一维、二维、多维、高维
- 一维数据的表示:列表类型(有序)和集合类型(无序)
- 一维数据的存储:空格分隔、逗号分隔、特殊符号分隔
- 一维数据的处理:字符串方法 .split() 和 .join()
二维数据的格式化和处理
- 二维数据的表示:列表类型,其中每个元素也是一个列表
- CSV 格式:逗号分隔表示一维,按行分隔表示二维
- 二维数据的处理:for 循环+.split() 和 .join()