游戏付费金额 —— 基于DC游戏数据(Brutal Age)
背景
“《野蛮时代》(Brutal Age)是一款风靡全球的SLG类型手机游戏。根据App Annie统计,《野蛮时代》在12个国家取得游戏畅销榜第1,在82个国家取得游戏畅销榜前10。准确了解每个玩家的价值,对游戏的广告投放策略和高效的运营活动(如精准的促销活动和礼包推荐)具有重要意义,有助于给玩家带来更个性化的体验。因此,我们希望能在玩家进入游戏的前期就对于他们的价值进行准确的估算。在这个竞赛里,想请各位选手利用玩家在游戏内前7日的行为数据,预测他们每个人在45日内的付费总金额”。
下面就针对这个游戏数据集进行分析和建模,因为比赛已经结束了,后面的分析只针对训练集样本。
数据一览
训练集样本总共2288007条数据,109个变量,主要涉及用户在注册7天内的游戏表现和付费信息。
import warnings
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder, scale
from sklearn.metrics import mean_squared_error
from sklearn.decomposition import PCA
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import KFold
warnings.filterwarnings('ignore')
pd.set_option('display.max_columns', 150)
pd.set_option('display.max_rows', 150)
plt.style.use('ggplot')
%matplotlib inline
train = pd.read_csv('tap_fun_train.csv')
float_feat = train.select_dtypes(include='float64').columns.values
int_feat = train.select_dtypes(include='int64').columns.values
train[float_feat] = train[float_feat].astype(np.float32)
train[int_feat] = train[int_feat].astype(np.int32)
train.info()
RangeIndex: 2288007 entries, 0 to 2288006
Columns: 109 entries, user_id to prediction_pay_price
dtypes: float32(13), int32(95), object(1)
memory usage: 960.1+ MB
train.head()
| user_id | register_time | wood_add_value | wood_reduce_value | stone_add_value | stone_reduce_value | ivory_add_value | ivory_reduce_value | meat_add_value | meat_reduce_value | magic_add_value | magic_reduce_value | infantry_add_value | infantry_reduce_value | cavalry_add_value | cavalry_reduce_value | shaman_add_value | shaman_reduce_value | wound_infantry_add_value | wound_infantry_reduce_value | wound_cavalry_add_value | wound_cavalry_reduce_value | wound_shaman_add_value | wound_shaman_reduce_value | general_acceleration_add_value | general_acceleration_reduce_value | building_acceleration_add_value | building_acceleration_reduce_value | reaserch_acceleration_add_value | reaserch_acceleration_reduce_value | training_acceleration_add_value | training_acceleration_reduce_value | treatment_acceleraion_add_value | treatment_acceleration_reduce_value | bd_training_hut_level | bd_healing_lodge_level | bd_stronghold_level | bd_outpost_portal_level | bd_barrack_level | bd_healing_spring_level | bd_dolmen_level | bd_guest_cavern_level | bd_warehouse_level | bd_watchtower_level | bd_magic_coin_tree_level | bd_hall_of_war_level | bd_market_level | bd_hero_gacha_level | bd_hero_strengthen_level | bd_hero_pve_level | sr_scout_level | sr_training_speed_level | sr_infantry_tier_2_level | sr_cavalry_tier_2_level | sr_shaman_tier_2_level | sr_infantry_atk_level | sr_cavalry_atk_level | sr_shaman_atk_level | sr_infantry_tier_3_level | sr_cavalry_tier_3_level | sr_shaman_tier_3_level | sr_troop_defense_level | sr_infantry_def_level | sr_cavalry_def_level | sr_shaman_def_level | sr_infantry_hp_level | sr_cavalry_hp_level | sr_shaman_hp_level | sr_infantry_tier_4_level | sr_cavalry_tier_4_level | sr_shaman_tier_4_level | sr_troop_attack_level | sr_construction_speed_level | sr_hide_storage_level | sr_troop_consumption_level | sr_rss_a_prod_levell | sr_rss_b_prod_level | sr_rss_c_prod_level | sr_rss_d_prod_level | sr_rss_a_gather_level | sr_rss_b_gather_level | sr_rss_c_gather_level | sr_rss_d_gather_level | sr_troop_load_level | sr_rss_e_gather_level | sr_rss_e_prod_level | sr_outpost_durability_level | sr_outpost_tier_2_level | sr_healing_space_level | sr_gathering_hunter_buff_level | sr_healing_speed_level | sr_outpost_tier_3_level | sr_alliance_march_speed_level | sr_pvp_march_speed_level | sr_gathering_march_speed_level | sr_outpost_tier_4_level | sr_guest_troop_capacity_level | sr_march_size_level | sr_rss_help_bonus_level | pvp_battle_count | pvp_lanch_count | pvp_win_count | pve_battle_count | pve_lanch_count | pve_win_count | avg_online_minutes | pay_price | pay_count | prediction_pay_price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2018-02-02 19:47:15 | 20125.0 | 3700.0 | 0.0 | 0.0 | 0.0 | 0.0 | 16375.0 | 2000.0 | 0.0 | 0.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 50 | 0 | 50 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.333333 | 0.0 | 0 | 0.0 |
| 1 | 1593 | 2018-01-26 00:01:05 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.333333 | 0.0 | 0 | 0.0 |
| 2 | 1594 | 2018-01-26 00:01:58 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.166667 | 0.0 | 0 | 0.0 |
| 3 | 1595 | 2018-01-26 00:02:13 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.166667 | 0.0 | 0 | 0.0 |
| 4 | 1596 | 2018-01-26 00:02:46 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.333333 | 0.0 | 0 | 0.0 |
数据分析
付费金额分布
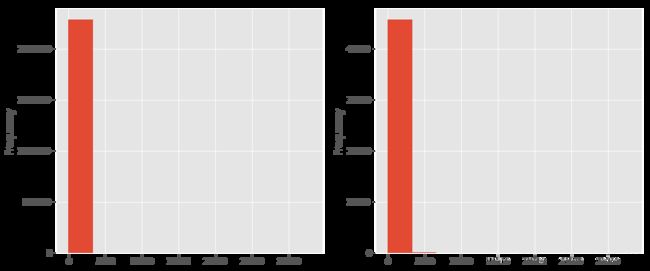
绝大部分用户的付费金额为0,45天内的人均付费金额为1.79元,即使是付费用户的付费金额也是集中在低金额区间,付费率情况后面和细看;最高金额高达3万以上,分布非常不均衡。
#整体金额分布,付费用户的金额分布
train['prediction_pay_price'].describe()
count 2.288007e+06
mean 1.793456e+00
std 8.844339e+01
min 0.000000e+00
25% 0.000000e+00
50% 0.000000e+00
75% 0.000000e+00
max 3.297781e+04
Name: prediction_pay_price, dtype: float64
fig, ax = plt.subplots(1, 2, figsize=(14, 6))
train['prediction_pay_price'].plot.hist(ax=ax[0])
train.loc[train['prediction_pay_price'] > 0, 'prediction_pay_price'].plot.hist(ax=ax[1])
付费金额和人数
注册后,
- 7天内的付费玩家41439人、付费总金额122万元
- 45天内的付费玩家45988人、付费总金额410万元,人数增长11%,金额增长却超过235%
- 新增加的付费玩家(7天内未付费,45天内有付费)4549人,只贡献了增长总额的6.5%,也就是说93.5%的增长来源于7天内就付费的玩家
#付费金额和人数,新增加人数贡献的金额
first_7_num = len(train[train['pay_price'] > 0])
first_45_num = len(train[train['prediction_pay_price'] > 0])
first_7_amt = train.loc[train['pay_price'] > 0, 'pay_price'].sum()
first_45_amt = train.loc[train['prediction_pay_price'] > 0, 'prediction_pay_price'].sum()
fig, ax = plt.subplots(1, 2, figsize=(14,6))
ax[0].bar(['first_7_num', 'first_45_num'], [first_7_num, first_45_num], color='lightblue')
ax[0].set_xlabel('First_7 VS First_45')
ax[0].set_ylabel('Number of Player Who Paid')
for i, j in zip([0, 1], [first_7_num, first_45_num]):
ax[0].text(i, j+500, j, ha='center', fontsize=12)
ax[1].bar(['first_7_amt', 'first_45_amt'], [first_7_amt, first_45_amt], color='pink')
ax[1].set_xlabel('First_7 VS First_45')
ax[1].set_ylabel('Paid Amount')
for i, j in zip([0, 1], [first_7_amt, first_45_amt]):
ax[1].text(i, j+10000, j, ha='center', fontsize=12)

train.loc[(train['pay_price'] == 0) & (train['prediction_pay_price'] > 0), 'prediction_pay_price'].sum()/(first_45_amt-first_7_amt)
0.06452517
付费率
7天内的付费率1.81%,再次付费的比例57%,45天内付费率2.01%。
#付费率,二次付费率
pay_rate_7 = len(train[train['pay_price'] > 0])/len(train)
pay_rate_45 = len(train[train['prediction_pay_price'] > 0])/len(train)
fig, ax = plt.subplots(figsize=(8,6))
ax.bar(['pay_rate_7', 'pay_rate_45'], [pay_rate_7, pay_rate_45], color='gold')
ax.set_xlabel('First_7 VS First_45')
ax.set_ylabel('Pay Rate')
for i, j in zip([0, 1], [pay_rate_7, pay_rate_45]):
ax.text(i, j+0.0002, str(round(j*100, 2))+'%', ha='center', fontsize=12)

len(train[train['pay_count'] > 1])/len(train[train['pay_count'] > 0])
0.5747484253963657
人均付费金额(ARPU)
付费玩家的人均付费金额89元,45天内达到这个水平,很厉害了。
train.loc[train['prediction_pay_price'] > 0, 'prediction_pay_price'].sum()/len(train[train['prediction_pay_price'] > 0])
89.21306101591719
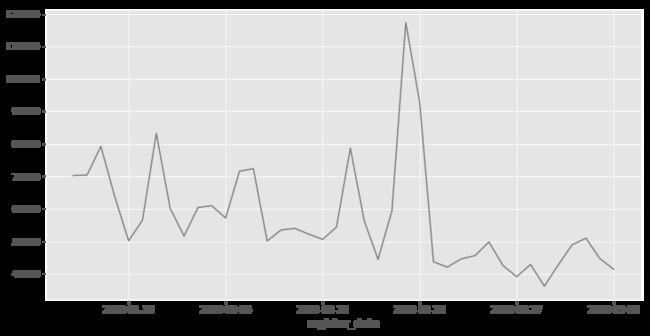
注册日期和人数
样本数据的时间从2018年1月26日到3月06日,在这段时间内每日的注册人数有隐隐的下降趋势;2月19日是一个峰值,注册人数达到117311。
train['register_time'] = pd.to_datetime(train['register_time'])
train['register_date'] = train['register_time'].dt.date
train.groupby('register_date')['prediction_pay_price'].count().plot(figsize=(12,6), color='grey')
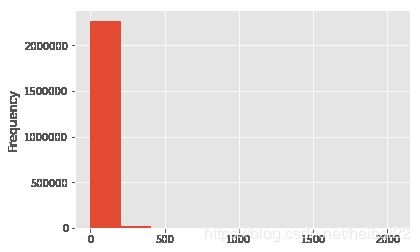
在线时长
人均一周游戏时长为10分钟,最高时长超过2000分钟,分布集中在偏低区间;游戏时长和付费金额没有很明显的线性关系,也可能是离群点太多了。
train['avg_online_minutes'].describe()
count 2.288007e+06
mean 1.016729e+01
std 3.869698e+01
min 0.000000e+00
25% 5.000000e-01
50% 1.833333e+00
75% 4.833333e+00
max 2.049667e+03
Name: avg_online_minutes, dtype: float64
train['avg_online_minutes'].plot.hist()
特征工程
下面进行特征工程,会增加一些变量,也会删除部分变量,最后会对游戏数据进行标准化。
train['register_month'] = train['register_time'].dt.month
train['register_day'] = train['register_time'].dt.day
train['register_week'] = train['register_time'].dt.week
train['register_weekday'] = train['register_time'].dt.weekday
# 计算一下达到某种等级建筑的数量
def level_num(num):
data = train.loc[:,'bd_training_hut_level':'bd_hero_pve_level'].applymap(lambda x: 1 if x > num else 0)
result = data.apply(sum, axis=1)
return result
train['over_0_level'] = level_num(0)
train['over_3_level'] = level_num(3)
train['over_5_level'] = level_num(5)
train['over_10_level'] = level_num(10)
# 计算完成科研的数量
train['sr_done_num'] = train.loc[:,'sr_scout_level':'sr_rss_help_bonus_level'].apply(sum, axis=1)
train['pvp_lanch_rate'] = train['pvp_lanch_count']/train['pvp_battle_count']
train['pvp_win_rate'] = train['pvp_win_count']/train['pvp_battle_count']
train['pve_lanch_rate'] = train['pve_lanch_count']/train['pve_battle_count']
train['pve_win_rate'] = train['pve_win_count']/train['pve_battle_count']
train['pvp_pve'] = train['pvp_battle_count']+train['pve_battle_count']
train['pvp_pve_win_rate'] = (train['pvp_win_count']+train['pve_win_count'])/train['pvp_pve']
train.fillna(0, inplace=True)
# 找出方差为0或者非常小的变量,sklearn中有个类似的方法可以调用
def low_var(df):
columns = df.columns.values
col_list = []
for column in columns:
unique_num = df[column].nunique()
if unique_num > 1:
unique_rate = unique_num/len(df)
first_two = list(df[column].value_counts())[0:2]
first_two_rate = first_two[0]/first_two[1]
if (unique_rate < 0.01) and (first_two_rate > 80):
col_list.append(column)
else:
col_list.append(column)
return col_list
feats = list(train.columns.values)
del feats[106:109]
low_var_feat = low_var(train[feats])
# 对游戏数据进行标准化,同时使用主成分分析
train.loc[:,'wood_add_value':'avg_online_minutes'] = train.loc[:,'wood_add_value':'avg_online_minutes'].apply(scale)
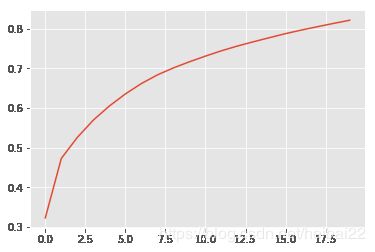
pca = PCA(n_components=20)
pca.fit(train.loc[:,'wood_add_value':'avg_online_minutes'])
plt.plot(range(0, 20), np.cumsum(pca.explained_variance_ratio_))
pca_df = pd.DataFrame(pca.transform(train.loc[:,'wood_add_value':'avg_online_minutes']), columns=['components_'+str(i) for i in range(20)])
train = pd.concat([train, pca_df], axis=1)
train.drop(low_var_feat, axis=1, inplace=True)
train.drop(['register_time', 'user_id'], axis=1, inplace=True)
train['register_date'] = LabelEncoder().fit_transform(train['register_date'])
train['pay_price'] = np.log(train['pay_price'] + 1)
train['prediction_pay_price'] = np.log(train['prediction_pay_price'] + 1)
float_feat = train.select_dtypes(include='float64').columns.values
int_feat = train.select_dtypes(include='int64').columns.values
train[float_feat] = train[float_feat].astype(np.float32)
train[int_feat] = train[int_feat].astype(np.int32)
del pca_df
建模
X = list(train.columns.values)
X.remove('prediction_pay_price')
y = 'prediction_pay_price'
gbm = GradientBoostingRegressor(verbose=1, random_state=123)
kfold = KFold(n_splits=4, shuffle=True, random_state=123)
rmse_list = []
feature_importance = pd.DataFrame()
for fold, (train_idx, test_idx) in enumerate(kfold.split(train)):
print('='*50)
print('fold {}'.format(fold))
gbm.fit(train.iloc[train_idx][X], train.iloc[train_idx][y])
pred = gbm.predict(train.iloc[test_idx][X])
# rmse = np.sqrt(mean_squared_error(train.iloc[test_idx][y], pred))
rmse = np.sqrt(mean_squared_error(np.exp(train.iloc[test_idx][y])-1, np.exp(pred)-1))
rmse_list.append(rmse)
print('rmse {}'.format(rmse))
importance_df = pd.DataFrame()
importance_df['feature'] = X
importance_df['importance'] = gbm.feature_importances_
importance_df['fold'] = fold + 1
feature_importance = pd.concat([feature_importance, importance_df], axis=0)
==================================================
fold 0
Iter Train Loss Remaining Time
1 0.1259 23.10m
2 0.1065 22.28m
3 0.0908 21.97m
4 0.0779 21.70m
5 0.0675 21.52m
6 0.0591 21.26m
7 0.0522 21.12m
8 0.0466 20.85m
9 0.0421 20.59m
10 0.0383 20.32m
20 0.0240 17.91m
30 0.0219 15.75m
40 0.0215 13.55m
50 0.0213 11.28m
60 0.0213 9.01m
70 0.0212 6.75m
80 0.0211 4.49m
90 0.0211 2.24m
100 0.0210 0.00s
rmse 76.81655221125601
==================================================
fold 1
Iter Train Loss Remaining Time
1 0.1260 22.07m
2 0.1066 21.79m
3 0.0908 21.59m
4 0.0780 21.68m
5 0.0675 21.39m
6 0.0591 21.11m
7 0.0522 20.91m
8 0.0466 20.71m
9 0.0420 20.55m
10 0.0383 20.36m
20 0.0239 18.40m
30 0.0218 16.33m
40 0.0214 14.15m
50 0.0213 11.87m
60 0.0212 9.51m
70 0.0211 7.14m
80 0.0210 4.77m
90 0.0210 2.39m
100 0.0209 0.00s
rmse 80.4590172800173
==================================================
fold 2
Iter Train Loss Remaining Time
1 0.1259 22.36m
2 0.1065 22.10m
3 0.0908 21.89m
4 0.0780 21.69m
5 0.0676 21.45m
6 0.0591 21.29m
7 0.0522 21.24m
8 0.0466 21.17m
9 0.0421 21.08m
10 0.0384 20.96m
20 0.0240 19.00m
30 0.0219 16.78m
40 0.0215 14.45m
50 0.0213 12.06m
60 0.0212 9.66m
70 0.0212 7.26m
80 0.0211 4.84m
90 0.0210 2.42m
100 0.0210 0.00s
rmse 53.03963382354496
==================================================
fold 3
Iter Train Loss Remaining Time
1 0.1261 24.34m
2 0.1067 24.01m
3 0.0908 23.76m
4 0.0780 23.52m
5 0.0675 23.23m
6 0.0590 22.94m
7 0.0522 22.69m
8 0.0465 22.43m
9 0.0420 22.19m
10 0.0382 21.93m
20 0.0238 19.49m
30 0.0217 17.07m
40 0.0213 14.64m
50 0.0211 12.19m
60 0.0210 9.74m
70 0.0210 7.24m
80 0.0209 4.79m
90 0.0209 2.37m
100 0.0208 0.00s
rmse 49.03841446816272
print('通过交叉验证,训练集的均方根误差为{}'.format(np.mean(rmse_list)))
通过交叉验证,训练集的均方根误差为64.83840444574524
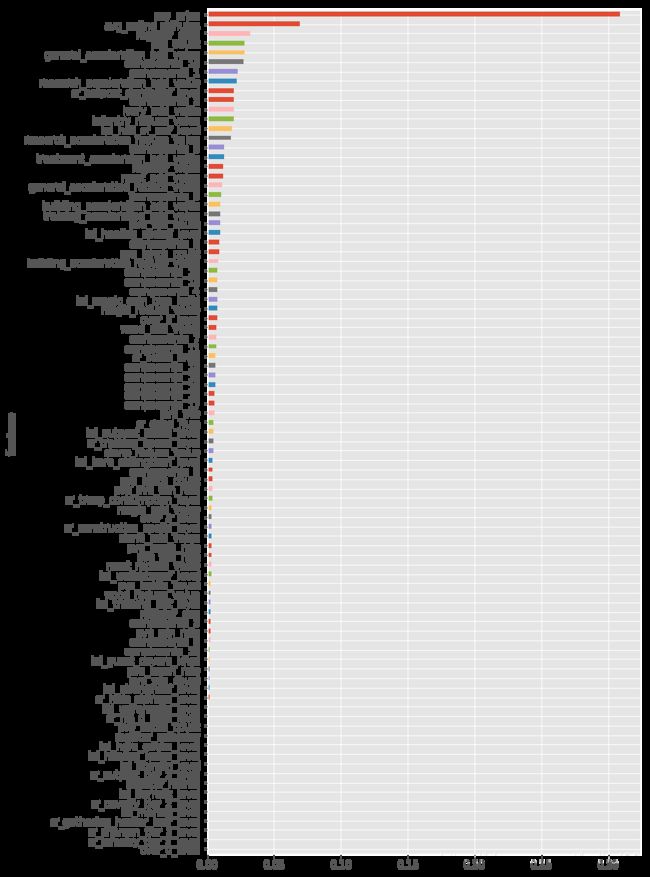
feature_importance.groupby('feature')['importance'].mean().sort_values(ascending=True).plot.barh(figsize=(8, 16))
结语
因为没有玩过这款游戏,对其中的游戏内容和指标还有理解不到位的地方,相信玩过游戏后应该会有新的理解,找到其它的重要特征。上文中的模型没有调参,模型优化后结果还能提升。同时,还可以根据游戏的参与度对用户进行不同类型的划分,观察高氪用户和普通用户在游戏属性上的差异等其它方面。