ElasticSearch7.2 从安装部署到SpringBoot集成实战(基于Windows)
简介
基本概念
常用术语
详细说明
字段类型
注意事项
ES windows 版 安装部署
ElasticSearch-head 安装部署
IK分词器安装
使用Postman创建索引
创建一个空的索引 testindex (非结构化索引)
对索引的mappings进行赋值,并转换为结构化索引
SpringBoot 集成实战
简介
https://blog.csdn.net/heiyogl/article/details/103281714
基本概念
Elasticsearch也是基于Lucene的全文检索库,本质也是存储数据,很多概念与MySQL类似的。
对比关系:
| 索引库(indices) |
Databases 数据库 |
| 类型(type) |
Table 数据表 |
| 文档(Document) |
Row 行 |
| 字段(Field) |
Columns 列 |
常用术语
1.1:文档Document:用户存储在Elasticsearch中的文档;
1.2:索引 Index:由具有相同字段的文档列表组成;
1.3:节点Node:一个Elasticsearch的运行实例,是集群的构成单元;
1.4:集群Cluster:由一个或多个节点组成,对外提供服务;
1.5:分片:每个索引都有多个分片,每个分片是一个Lucene索引;
1.6:备份:拷贝一份分片就完成了分片的备份;
详细说明
- 索引库(indices): indices是index的复数,代表许多的索引;
- 类型(type): 类型是模拟mysql中的table概念,一个索引库下可以有不同类型的索引,比如商品索引,订单索引,其数据格式不同。不过这会导致索引库混乱,因此未来版本中会移除这个概念;
- 文档(document): 存入索引库原始的数据。比如每一条商品信息,就是一个文档;
- 字段(field): 文档中的属性;
- 映射配置(mappings): 字段的数据类型、属性、是否索引、是否存储等特性。
在Elasticsearch有一些集群相关的概念:
- 索引集(Indices,index的复数):逻辑上的完整索引
- 分片(shard):数据拆分后的各个部分
- 副本(replica):每个分片的复制
字段类型
- type:字段类型,是枚举:FieldType,可以是text、long、short、date、integer、object等
- text:存储数据时候,会自动分词,并生成索引;
- keyword:存储数据时候,不会分词建立索引;
- Numerical:数值类型,分两类
- 基本数据类型:long、interger、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
- Date:日期类型;
- elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
- index:是否索引,布尔类型,默认是true
- store:是否存储,布尔类型,默认是false
- analyzer:分词器名称,这里的ik_max_word即使用ik分词器
注意事项
1、Elasticsearch本身就是分布式的,因此即便你只有一个节点,Elasticsearch默认也会对你的数据进行分片和副本操作;当你向集群添加新数据时,数据也会在新加入的节点中进行平衡;
2、ES创建索引时默认创建5个分片一个备份 , 分片的数量只能在创建索引时指定,备份可以动态修改;
3、索引命名规范:字母小写,且不含中划线。
ES windows 版 安装部署
下载地址: https://www.elastic.co/cn/downloads/elasticsearch
文件名: elasticsearch-7.4.0-windows-x86_64.zip
Es 安装包内本身内置了JDK,且内置的JDK版本是该Es所推荐使用的版本。
1、将文件 elasticsearch-7.4.0-windows-x86_64.zip 解压到安装目录下;
2、配置es使用内置的jdk(而非电脑所配置的JAVA_HOME环境变量)
使用文本编辑器编辑 bin/elasticsearch-env.bat 直接添加了JAVA_HOME 的配置,具体如下:

rem 配置自己的jdk
set JAVA_HOME=E:/xxx/elastic/elasticsearch-7.4.0/jdk
3、双击打开解压后 bin 目录下的 elasticsearch.bat

浏览器打开地址: http://127.0.0.1:9200/ 看到如下界面说明启动好了

ElasticSearch-head 安装部署
ElasticSearch-head 是一个用来查看ES的运行状态和数据的可视化工具,ElasticSearch-head依赖 node.js
1、node.js 安装
下载地址: http://nodejs.cn/download/
文件名: node-v12.13.0-x64.msi
双击打开即可进入安装环节,安装完成后,打开cmd 命令,输入 node --version 命令即可查看安装的版本。
node.js 安装完成后,切换到 node.js 的安装目录(cmd中输入 npm config ls 命令可查看安装目录),运行命令安装 grunt,命令如下: npm install -g grunt-cli
2、ElasticSearch-head 安装
下载地址: https://github.com/mobz/elasticsearch-head
文件名: elasticsearch-head-master.zip
下载完成后,cmd 进入 elasticsearch-head-master 的解压目录,然后执行 npm install 命令(对改目录下的相关文件解压并安装)。安装完成后,输入启动命令 npm run start
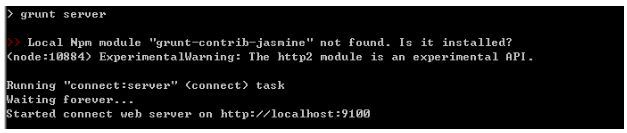
浏览器地址输入: http://127.0.0.1:9100/ 可查看 head 界面

Es默认不允许跨域链接,所以默认会显示未连接的状态。
在es > config 目录下,打开 elasticsearch.yml 文件,并在末尾处添加配置:
http.cors.enabled: true
http.cors.allow-origin: "*"
保存,重启es,且刷新elasticsearch-head 即可链接。

IK分词器安装
下载地址: https://github.com/medcl/elasticsearch-analysis-ik
文件名: elasticsearch-analysis-ik-master.zip
安装步骤:
1、cmd 进入 elasticsearch-analysis-ik-master 解压目录;
2、执行 mvn clean package 命令进行打包,打包完后会多出一个 target 文件夹。打包zip文件路径为: target > releases > elasticsearch-analysis-ik-7.4.0.zip ;
3、在es安装目录下的 plugins 文件夹下创建 analysis-ik 文件夹,并将上一步打包好的 elasticsearch-analysis-ik-7.4.0.zip 解压到此处,如下图:
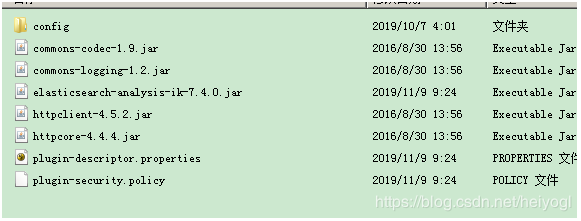
4、重启 ES,可以启动,则说明安装成功。
使用Postman创建索引
创建一个空的索引 testindex (非结构化索引)
http://127.0.0.1:9200/testindex
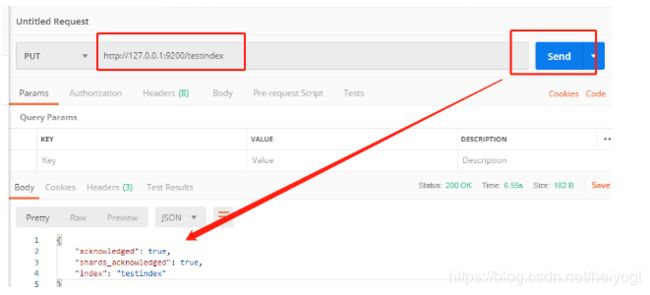
通过 elasticsearch-head 可以看到该索引的mappings 是空的(非结构化索引)

对索引的mappings进行赋值,并转换为结构化索引
mapping类似于数据库表的结构,主要用于
1.定义index下的字段名;
2.定义字段类型;
3.定义倒排索引相关的配置。
http://127.0.0.1:9200/testindex/_mapping
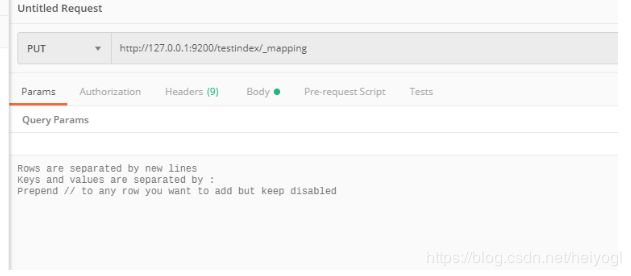
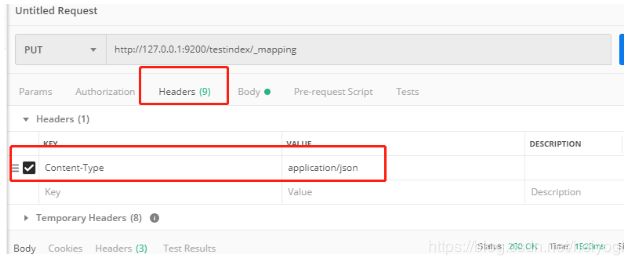
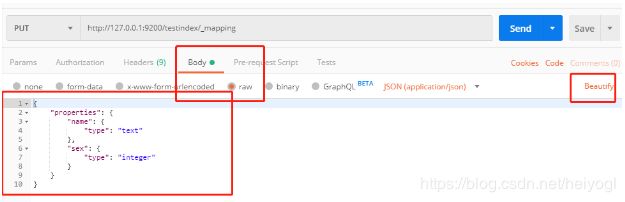
{"properties":{"name":{"type":"text"},"sex":{"type":"integer"}}}
通过 elasticsearch-head 可以看到该索引的mappings

SpringBoot 集成实战
基于SpringBoot实现新增/修改、删除、查询、聚合统计的功能
1、pom.xml 添加依赖
org.elasticsearch
elasticsearch
7.2.0
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.2.0
2、application.properties 配置ES地址
elasticsearch.ip=127.0.0.1:92003、创建 ElasticsearchRestClient.java
@Configuration
public class ElasticsearchRestClient {
private static final int ADDRESS_LENGTH = 2;
private static final String HTTP_SCHEME = "http";
private static final String ARTICLE_INDEX_NAME = "article_index";
@Value("${elasticsearch.ip}")
String[] ipAddress;
private RestHighLevelClient highLevelClient;
@Bean
public RestClientBuilder restClientBuilder() {
HttpHost[] hosts = Arrays.stream(ipAddress)
.map(this::makeHttpHost)
.filter(Objects::nonNull)
.toArray(HttpHost[]::new);
return RestClient.builder(hosts);
}
@Bean(name = "highLevelClient")
public RestHighLevelClient highLevelClient(@Autowired RestClientBuilder restClientBuilder) {
highLevelClient = new RestHighLevelClient(restClientBuilder);
return highLevelClient;
}
private HttpHost makeHttpHost(String s) {
assert StringUtils.isNotEmpty(s);
String[] address = s.split(":");
if (address.length == ADDRESS_LENGTH) {
String ip = address[0];
int port = Integer.parseInt(address[1]);
return new HttpHost(ip, port, HTTP_SCHEME);
} else {
return null;
}
}
// 新增 或 修改文档(若ID存在,则修改)
public void insertOrUpdateArticle(EsArticle article) throws IllegalArgumentException, IllegalAccessException{
try {
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
// 遍历实体类
Class clas = article.getClass();
Field[] fields = clas.getDeclaredFields();
for (int i = 0; i < fields.length; i++) {
Field f = fields[i];
f.setAccessible(true);
// es字段赋值
if (f.getType().toString().equals("class java.sql.Timestamp")) { //若字段类型为时间类型,则将其转换为 long 进行存储
builder.field(f.getName(), ((Timestamp)f.get(article)).getTime());
} else {
builder.field(f.getName(), f.get(article));
}
}
builder.endObject();
IndexRequest request = new IndexRequest(ARTICLE_INDEX_NAME).source(builder);
request.id(article.getId()); // 通过指定 id 来实现:若存在则更新记录,否则插入记录
highLevelClient.index(request, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
}
// 批量新增 或 修改文档(若ID存在,则修改)
public int insertOrUpdateBatchArticle(List list) {
int result = -1;
try {
BulkRequest request = new BulkRequest();
for (EsArticle article : list) {
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
// 遍历实体类
Class clas = article.getClass();
Field[] fields = clas.getDeclaredFields();
for (int i = 0; i < fields.length; i++) {
Field f = fields[i];
f.setAccessible(true);
// es字段赋值
if (f.getType().toString().equals("class java.sql.Timestamp")) { //若字段类型为时间类型,则将其转换为 long 进行存储
if (null == f.get(article)) {
builder.field(f.getName(), 0l);
} else {
builder.field(f.getName(), ((Timestamp)f.get(article)).getTime());
}
} else {
builder.field(f.getName(), f.get(article));
}
}
builder.endObject();
IndexRequest requestItem = new IndexRequest(ARTICLE_INDEX_NAME).source(builder);
requestItem.id(article.getId()); // 通过指定 id 来实现:若存在则更新记录,否则插入记录
request.add(requestItem);
}
highLevelClient.bulk(request, RequestOptions.DEFAULT);
result = list.size();
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
// 批量删除
public void deleteBatchArticle(Collection idList) {
BulkRequest request = new BulkRequest();
idList.forEach(item -> request.add(new DeleteRequest(ARTICLE_INDEX_NAME, item.toString())));
try {
highLevelClient.bulk(request, RequestOptions.DEFAULT);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 通过查询条件实现分页查询
* @param queryParam 查询条件(Map)
* @param pageIndex 分页索引,从第 1 页开始
* @param pageSize 每页条数
* @param order 排序数组,[排序字段][排序方式(asc | desc)]
*/
public void queryArticle(Map queryParam, int pageIndex, int pageSize, String[][] order) {
List> result = new ArrayList>();
SearchRequest searchRequest = new SearchRequest(ARTICLE_INDEX_NAME);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
queryBuilder(pageIndex, pageSize, queryParam, ARTICLE_INDEX_NAME, order, searchRequest, searchSourceBuilder);
try {
SearchResponse response = highLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
Map map = hit.getSourceAsMap();
map.put("id", hit.getId());
result.add(map);
// 取高亮结果
if (null != queryParam.get("content")) { // 如果查询条件中有内容关键词,则使用内容关键词处理高亮
Map highlightFields = hit.getHighlightFields();
HighlightField highlight = highlightFields.get("content");
Text[] fragments = highlight.fragments(); // 多值的字段会有多个值
String fragmentString = fragments[0].string();
System.out.println("高亮:" + fragmentString);
}
}
System.out.println("pageIndex:" + pageIndex);
System.out.println("pageSize:" + pageSize);
System.out.println(response.getHits().getTotalHits());
System.out.println(result.size());
for (Map map : result) {
System.out.println(map.get("title"));
System.out.println(map.get("content"));
System.out.println(map.get("id"));
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 构建查询条件
* @param pageIndex 分页索引,从第 1 页开始
* @param pageSize 每页条数
* @param query 查询条件集合(Map)
* @param indexName 索引名称
* @param order 排序数组,[排序字段][排序方式(asc | desc)]
* @param searchRequest
* @param searchSourceBuilder
*/
private void queryBuilder(Integer pageIndex, Integer pageSize, Map query, String indexName, String[][] order, SearchRequest searchRequest, SearchSourceBuilder searchSourceBuilder) {
if (query != null && !query.keySet().isEmpty()) {
if (pageIndex != null && pageSize != null) {
searchSourceBuilder.size(pageSize);
if (pageIndex <= 0) {
pageIndex = 0;
}
searchSourceBuilder.from((pageIndex - 1) * pageSize);
}
//1.创建QueryBuilder(即设置查询条件)这儿创建的是组合查询(也叫多条件查询),后面会介绍更多的查询方法
// 组合查询BoolQueryBuilder -> must(QueryBuilders):AND ; mustNot(QueryBuilders):NOT; should(QueryBuilders):OR
BoolQueryBuilder boolBuilder = QueryBuilders.boolQuery();
// 构建查询条件
query.keySet().forEach(
key -> {
boolBuilder.must(QueryBuilders.matchQuery(key, query.get(key)));// builder下有must、should以及mustNot 相当于sql中的and、or以及not
});
searchSourceBuilder.query(boolBuilder);
HighlightBuilder highlightBuilder = new HighlightBuilder();
HighlightBuilder.Field highlightTitle = new HighlightBuilder.Field("content").preTags("").postTags("");
highlightTitle.highlighterType("unified");
highlightBuilder.field(highlightTitle);
searchSourceBuilder.highlighter(highlightBuilder);
}
searchRequest.source(searchSourceBuilder);
// 排序
if (null != order && order.length > 0) {
for (int i = 0; i < order.length; i++) {
searchSourceBuilder.sort(new FieldSortBuilder(order[i][0]).order(SortOrder.fromString(order[i][1])));
}
}
}
/**
* 通过条件实现聚合查询(统计)
* @param queryParam 查询条件(Map)
* @param pageIndex 分页索引,从第 1 页开始
* @param pageSize 每页条数
* @param order 排序数组,[排序字段][排序方式(asc | desc)]
* @param groupName 聚合查询别名
* @param groupField 聚合字段
* @return
*/
public LinkedHashMap countArticle(Map queryParam, int pageIndex, int pageSize, String[][] order, String groupName, String groupField) {
SearchRequest searchRequest = new SearchRequest(ARTICLE_INDEX_NAME);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 构建聚合条件
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms(groupName).field(groupField);
sourceBuilder.aggregation(termsAggregationBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// 构建查询条件
queryBuilder(pageIndex, pageSize, queryParam, ARTICLE_INDEX_NAME, order, searchRequest, sourceBuilder);
// 若不需要上述“构建查询条件”,直接使用下文即可
// searchRequest.source(sourceBuilder);
try {
SearchResponse searchResponse = highLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
Map stringAggregationMap = aggregations.asMap();
ParsedStringTerms parsedLongTerms = (ParsedStringTerms) stringAggregationMap.get(groupName);
List buckets = parsedLongTerms.getBuckets();
// 使用LinkedHashMap 确保结果有序输出
LinkedHashMap map = new LinkedHashMap();
for (Terms.Bucket bucket : buckets) {
long docCount = bucket.getDocCount();//个数
String v = bucket.getKeyAsString(); //
map.put(v, docCount);
}
return map;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 通过条件实现多字段聚合查询(统计)
* @param queryParam 查询条件(Map)
* @param pageIndex 分页索引,从第 1 页开始
* @param pageSize 每页条数
* @param order 排序数组,[排序字段][排序方式(asc | desc)](暂不支持)
* @param groupField1 聚合字段1
* @param groupField2 聚合字段2
* @return
*/
public List> countArticleMultiple(Map queryParam, int pageIndex, int pageSize, String[][] order, String groupField1, String groupField2) {
//搜索结果状态信息
List> result = new ArrayList>();
try {
// 1、创建search请求
//SearchRequest searchRequest = new SearchRequest();
SearchRequest searchRequest = new SearchRequest(ARTICLE_INDEX_NAME);
// 2、用SearchSourceBuilder来构造查询请求体 ,请仔细查看它的方法,构造各种查询的方法都在这。
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.size(0);
//加入聚合
//字段值项分组聚合
TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_mutiple_" + groupField1 + "_" + groupField2)
.script(new Script("doc['" + groupField1 + "'] +'#'+doc['" + groupField2 + "']")) //(分组如果在字符串字段上,需要建立字段对应的.keyword字段(如:media_type.keyword),该字段支持聚合处理,直接用字符串字段会报错。)
//.field("fngroup.keyword")
// .size(Integer.MAX_VALUE)
.size(500) // 开发环境,避免出现性能问题,设置返回buckets数量相对小一些;一次性返回buckets数量大于10000,需设置search.max_buckets参数,否则会报错。
.order(BucketOrder.aggregation("count", true));
//计算每组的平均balance指标
aggregation.subAggregation(AggregationBuilders.count("count").field("sessionid"));
sourceBuilder.aggregation(aggregation);
// 构建查询条件
queryBuilder(pageIndex, pageSize, queryParam, ARTICLE_INDEX_NAME, order, searchRequest, sourceBuilder);
//3、发送请求
SearchResponse searchResponse = highLevelClient.search(searchRequest,RequestOptions.DEFAULT);
int row = 0;
//4、处理响应
if(RestStatus.OK.equals(searchResponse.status())) {
// 获取聚合结果
Aggregations aggregations = searchResponse.getAggregations();
Terms byAgeAggregation = aggregations.get("by_mutiple_" + groupField1 + "_" + groupField2);
for(Terms.Bucket buck : byAgeAggregation.getBuckets()) {
HashMap map=new HashMap();
String[] arr= buck.getKeyAsString().split("#");
map.put(groupField1, arr[0].replace("[","").replace("]",""));
map.put(groupField2, arr[1].replace("[","").replace("]",""));
map.put("count", buck.getDocCount()); // 获取统计数
result.add(map);
}
}
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
}
4、调用测试
// 新增记录
public void create() {
EsArticle article = new EsArticle();
article.setTid("tidv");
article.setTitle("标题");
try {
client.insertOrUpdateArticle(article);
} catch (IllegalArgumentException | IllegalAccessException e) {
e.printStackTrace();
}
System.out.println("success ..");
}
// 查询
public void query() {
Map queryParam = new HashMap();
queryParam.put("content", "深圳创业板");
client.queryArticle(queryParam, 1, 5, null);
System.out.println("success..");
}
// 分组统计
public void count() {
Map queryParam = new HashMap();
String[][] order = {{"tid", "desc"}};
LinkedHashMap resultMap = client.countArticle(queryParam, 1, 5, order, "by_tid", "tid");
int row = 1;
for (Entry entry : resultMap.entrySet()) {
System.out.println(row++ + " > " + entry.getKey() + ":" + entry.getValue());
}
System.out.println("success..");
}
// 多字段分组统计
public void countArticleMultiple() {
String[][] order = {{"media_type", "desc"}};
Map queryParam = new HashMap();
queryParam.put("content", "深圳创业板");
client.countArticleMultiple(queryParam, 1, 5, order, "tid", "media_type");
System.out.println("success..");
}
至此,就完成了从安装部署到集成常用功能的实战工作。
参考文献:
https://blog.csdn.net/u014082714/article/details/89963046
https://blog.csdn.net/chen_2890/article/details/83895646
https://blog.csdn.net/weixin_37703281/article/details/90974279
https://www.jianshu.com/p/1fbfde2aefa5