论文-《From Recognition to Cognition: Visual Commonsense Reasoning》笔记
论文下载
摘要(Abstract):
Visual understanding goes well beyond object recognition. With one glance at an image, we can effortlessly imagine the world beyond the pixels: for instance, we can infer people’s actions, goals, and mental states. While this task is easy for humans, it is tremendously difficult for today’s vision systems, requiring higher-order cognition and commonsense reasoning about the world. We formalize this task as Visual Commonsense Reasoning. Given a challenging question about an image, a machine must answer correctly and then provide a rationale justifying its answer.
Next, we introduce a new dataset, VCR, consisting of 290k multiple choice QA problems derived from 110k movie scenes. The key recipe for generating non-trivial and high-quality problems at scale is Adversarial Matching, a new approach to transform rich annotations into multiple choice questions with minimal bias. Experimental results show that while humans find VCR easy (over 90% accuracy), state-of-the-art vision models struggle (∼45%).
To move towards cognition-level understanding, we present a new reasoning engine, Recognition to Cognition Networks (R2C), that models the necessary layered inferences for grounding, contextualization, and reasoning. R2C helps narrow the gap between humans and machines (∼65%); still, the challenge is far from solved, and we provide analysis that suggests avenues for future work.
对于人类来说,随便瞥一眼就能获取到很多图片信息,这些信息不仅仅是像素点显示的,还有图像之外隐藏的知识类信息,但是这个任务对机器来说很难,这里作者将这个任务定义为视觉常识推理,要求机器不仅回答出正确答案,还要对这个答案给出证明。
作者提出一个新的数据集VCR,包含290k个多选QA,这些问题来源于110k个电影场景。生成大量的有意义并且高质量的问题的关键是对抗性匹配,这是一种通过将丰富的注释转换为偏差极小的多选问题的方法。VCR数据集对人类来说比较简单,准确率可以超过90%,但是对于机器来说比较困难,准确率约为45%。
为了使机器能够达到认知的层面,作者提出一个新的方法,叫做Recognition to Cognition Networks (R2C),为基础、情景化、推理建立了必要的分层模型,缩小了人类和机器在识别VCR上的差距。
介绍(Introduction):
视觉理解要求实现识别和认知的无缝集成。除了识别层次的感知(例如检测物体及其属性),机器还需要达到认知层次的感知(比如推断人们的目的意图等)。现有的模型能较好的完成识别层次的认识,但是对于认知层次的任务效果并不好。

作为视觉理解的重要步骤,作者将其定义为视觉常识推理,要求模型针对图像和问题做出回答,并且根据对图像深层次的理解,给出一个基本原理来证明这个答案为什么正确。这个任务的数据集是VCR,使第一个这种类型这么大规模的数据集,包含290k个问题、答案、推理对,还包括超过110张独一无二的电影场景。在构建这个数据集时,最大的挑战是注释工作,由于人工编写的答案经常会带有一些偏见,这可以使模型在不理解图像真实内容的情况下利用这些偏见获得正确答案。
因此,作者提出了一种对抗性匹配的方法,这个方法可以在一定范围内创建健壮稳定的数据集。关键思路是将一个问题的正确答案重复三次,作为三个问题的错误答案,这样每个答案都有25%的正确率,解决了数据集的偏差问题,并抑制模型总是选择通用答案。
想要缩小识别和认知的差距,需要在视觉数据中建立自然语言的基础,在问题的上下文中理解答案,并对问题、答案、基本原理和图像进行推理。作者提出了一个新的模型,称作识别-认知网络模型(Recognition to Cogni- tion Networks (R2C))。该模型包含三个推理步骤:首先,将自然语言段落的意义与直接引用的图像区域(对象)联系起来;然后,将问题的答案和未提及的全局对象置于上下文环境中理解;最后,推理获得正确答案。在VCR上实验表明,R2C性能大大优于最先进的VQA系统,在回答问题可以达到65%的正确率,在回答理由时可以达到67%的正确率。
主要贡献:
(1) we formalize a new task, Visual Commonsense Reasoning.定义一个新任务为视觉常识推理
(2) present a large-scale multiple-choice QA dataset, VCR.提出一个数据集VCR
(3) that is automatically assigned using Adversarial Matching, a new algorithm for robust multiple-choice dataset creation.提出一个新方法对抗性匹配解决生成问题似的偏差缺陷
(4) We also propose a new model, R2C, that aims to mimic the layered inferences from recognition to cognition.提出一个新模型R2C用于分层推理
任务综述(Task Overview):
作者提出的VCR任务目的是推理出活动,人的角色,人的精神状态,事情发生的前后场景等,具体推理的分类如图所示。

视觉理解不仅要求正确的回答问题,还要有正确的理由。给定一个问题和四个答案选项,模型必须选择出正确答案,如果答案是正确的,那么再给定四个候选理由,模型必须再选出正确的理由。这中方式被称为Q->AR,只有答案和理由都选择正确,模型才算预测正确。这个任务可以分为两个多选子任务:问答(Q->A)和答案证明(QA->R)。在第一个子任务中,查询代表问题,响应代表答案,在第二个子任务中,查询代表问题和答案,响应代表理由(后边会使用查询、响应这两个词表示两个子任务共同的匹配过程)。
VCR子任务包含图像 ,目标检测序列
,目标检测序列 ,查询
,查询 ,
, 个响应。其中每个目标检测
个响应。其中每个目标检测![]() 包含一个边界框
包含一个边界框
 ,一个分割掩码
,一个分割掩码 ,一个分类标签
,一个分类标签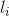 ;而查询和响应则使用自然语言和指向对象的指针混合的方式构成,即里边的每一个单词要么是词汇表
;而查询和响应则使用自然语言和指向对象的指针混合的方式构成,即里边的每一个单词要么是词汇表 中的词汇,要么指向检测序列中的一个对象(这里理解为词汇表中包含了所有的单词,如果没有指向具体的对象,则单词还会在词汇表中出现,另外按下文的理解,如果没有指向具体的对象,则会指向整个图像的边界)。
中的词汇,要么指向检测序列中的一个对象(这里理解为词汇表中包含了所有的单词,如果没有指向具体的对象,则单词还会在词汇表中出现,另外按下文的理解,如果没有指向具体的对象,则会指向整个图像的边界)。
这里作者使用N=4来评估模型,即一个问题对应4个答案,一个答案对应4个理由。每一个子任务的baseline准确率为25%(1/N),整体的baseline准确率为6.25%(1/(N^2))。
数据收集(Data Collection):
收集VCR中问题、正确答案、正确理由的关键是选择有趣的情况。因此作者从电影剪辑中提取静态图像,这些静态图像描述了复杂的情况,人类可以在没有上下文描述的情况下知道图像表达的意思,但是模型可能很难做到。
有趣和多样的情况(Interesting and Diverse Situations)。作者从大规模电影中和YouTube剪辑中选择多样的图像,并且训练一个有趣的过滤器来避免简单的图像。

众包质量标注(Crowdsourcing Quality Annotations)。由工作人员人工针对图像提一到三个问题,对于每个问题提供一个合理的答案和理由。
对抗性匹配(Adversarial Matching We):
作者将VCR任务转换为四路选择任务,如何大规模的获取错误选项是关键。这里提出一个新方法成为对抗性匹配,关键分为两个子任务:错误响应尽可能和查询上下文相关;错误响应不能过于相似于正确响应。(我的理解是,前边提到的将一个问题的正确答案重复三次作为另外三个问题的错误答案,这里另外三个问题是哪三个需要使用这种方式进行对应,并不是随便的三个问题)。

因此,这里需要两个模型,一个使用BERT模型,用来计算查询和响应之间的相关性(relevant)![]() ;一个使用ESIM+ELMo模型,用来计算两个响应之间的相似性(similar)
;一个使用ESIM+ELMo模型,用来计算两个响应之间的相似性(similar)![]() 。给定一个数据集
。给定一个数据集![]() (这里的
(这里的 和为手写体,表示泛指响应和查询,
和为手写体,表示泛指响应和查询, 和
和 分别表示第i个查询和第j个响应),通过计算最大权重二分匹配,形成一个权重矩阵,公式如下:
分别表示第i个查询和第j个响应),通过计算最大权重二分匹配,形成一个权重矩阵,公式如下:

这里 用来权衡相关性和相似性。
用来权衡相关性和相似性。
确保数据完整性(Ensuring dataset integrity)。保证训练集和测试集没有问题/答案是重叠的。
识别到认知网络(Recognition to Cognition Networks):
首先,基础,即确定查询和每个响应,比如解决问题中问的那两个人是谁;其次,置于上下文中,即将查询、响应和图像放在一起,比如解决响应中的He指的是什么以及什么情况下一个人可能指着另一个用餐者;最后,推理,即推理图像区域、问题、响应之间的相互影响,比如确定问题中提问的现状状态到底是什么。之前提到过查询和响应都是由自然语言和指向对象的指针混合而成,这里每次单词 都对应于一个指向对象的指针
都对应于一个指向对象的指针![]() ,如果这个对象存在,就指向它,不存在则指向整张图像的边界。
,如果这个对象存在,就指向它,不存在则指向整张图像的边界。

基础(Grounding)。基础模型的核心是一个双向LSTM,使用单词 和单词指针
和单词指针![]() 作为输入,输出为r响应和q查询(这里不用手写体表示这是具体的那一个查询和响应)。
作为输入,输出为r响应和q查询(这里不用手写体表示这是具体的那一个查询和响应)。
置于上下文(Contextualization)。给定查询和响应,使用注意力机制将这些句子上下文彼此之间和图像上下文进行关联。对于响应中每一个位置 (第个单词),使用如下公式定义查询表示(可以理解为更新查询q为^qj)(注意下边公式的r和q与第一个公式的不一样,这个不是手写体,rj和qj分别表示当前响应的第i个单词和当前查询的第j个单词):
(第个单词),使用如下公式定义查询表示(可以理解为更新查询q为^qj)(注意下边公式的r和q与第一个公式的不一样,这个不是手写体,rj和qj分别表示当前响应的第i个单词和当前查询的第j个单词):

为了使答案和图像相关联,作者在响应r和每个对象 的图像特征之间增加一个双线性注意力机制,结果表示为^oi(注意这个^oi表示响应r中每个单词和图像特征的注意力情况)。
的图像特征之间增加一个双线性注意力机制,结果表示为^oi(注意这个^oi表示响应r中每个单词和图像特征的注意力情况)。
推理(Reasoning)。最后根据前边生成的^qi,^oi和ri推理获得最终结果。
结果(Results):
这里作者评估各种模型在VCR数据集上的性能,要求必须在两个子任务上都选择正确才算预测正确。
基线(baselines):
分为仅文本基线(Text-only baselines)和VQA基线(VQA Baselines)。仅文本基线中BERT取得了做好的性能,VQA基线中MLB去的了最好的性能,而作者提出的R2C模型优于以上两个基线,但是仍然远低于人类的性能,相差大约30%到40%。



相关工作(Related Work):
总的来说,对于视觉常识推理还有许多值得研究的地方。