AI-NLP-1.NLP理论基础
目录
Windows安装
安装Python3.7
安装Numpy
安装NLDK
NLTK自带语料库
文本处理流程
Tokenize
中英⽂NLP区别
中文分词
分词之后的效果
有时候tokenize没那么简单
社交⽹络语⾔的tokenize
纷繁复杂的词形
词形归⼀化
NLTK实现Stemming
NLTK实现Lemma
Stopwords
NLTK去除stopwords
⼀条typical的⽂本预处理流⽔线
什么是⾃然语⾔处理?
⽂本预处理让我们得到了什么?
NLTK在NLP上的经典应⽤
应⽤:情感分析
NLTK完成简单的情感分析
Too Young Too Simple
配上ML的情感分析
应⽤:⽂本相似度
⽤元素频率表⽰⽂本特征
Frequency 频率统计
应⽤:⽂本分类
http://www.nltk.org/
Python上著名的⾃然语⾔处理库,⾃带语料库,词性分类库,⾃带分类,分词,等等功能,强⼤的社区⽀持,还有N多的简单版wrapper。比如TextBolb。
Windows安装
安装Python3.7
http://www.python.org/downloads/,注意,安装X64版本,因为要和操作系统位数一致,记得勾选pip,在Path环璋变量中加入路径:
C:\Python\Python37\
C:\Python\Python37\Scripts注意除了主目录,Scripts这个路径也是需要加入的。
安装Numpy
C:\Users\hgy413>python -m pip install numpy
Collecting numpy
Downloading https://files.pythonhosted.org/packages/8b/8a/5edea6c9759b9c569542ad4da07bba0c03ffe7cfb15d8bbe59b417e99a84/numpy-1.15.0-cp37-none-win_amd64.whl (13.5MB)
100% |████████████████████████████████| 13.5MB 2.5MB/s
Installing collected packages: numpy
The scripts conv-template.exe, f2py.exe and from-template.exe are installed in 'C:\Python\Python37\Scripts' which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
Successfully installed numpy-1.15.0
You are using pip version 10.0.1, however version 18.0 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.验证是否安装成功:没有出现异常就表示成功了。
C:\Users\hgy413>python
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import numpy
>>>
安装NLDK
C:\Users\Administrator>python -m pip install nltk
Collecting nltk
Downloading https://files.pythonhosted.org/packages/50/09/3b1755d528ad9156ee7243d52aa5cd2b809ef053a0f31b53d92853dd653a/nltk-3.3.0.zip (1.4MB)
100% |████████████████████████████████| 1.4MB 240kB/s
Collecting six (from nltk)
Downloading https://files.pythonhosted.org/packages/67/4b/141a581104b1f6397bfa78ac9d43d8ad29a7ca43ea90a2d863fe3056e86a/six-1.11.0-py2.py3-none-any.whl
Installing collected packages: six, nltk
Running setup.py install for nltk ... done
Successfully installed nltk-3.3 six-1.11.0
You are using pip version 10.0.1, however version 18.0 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.验证是否安装成功:没有出现异常就表示成功了。准备下载其他模型。
C:\Users\Administrator>python
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import nltk
>>> nltk.download()
showing info https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml会弹出一个框:把它们都 下载下来吧:修改下目录到E:\AI\NLP\NLTK\nltk_data

点击下载all,等的时间有点久,差不多有3.25G: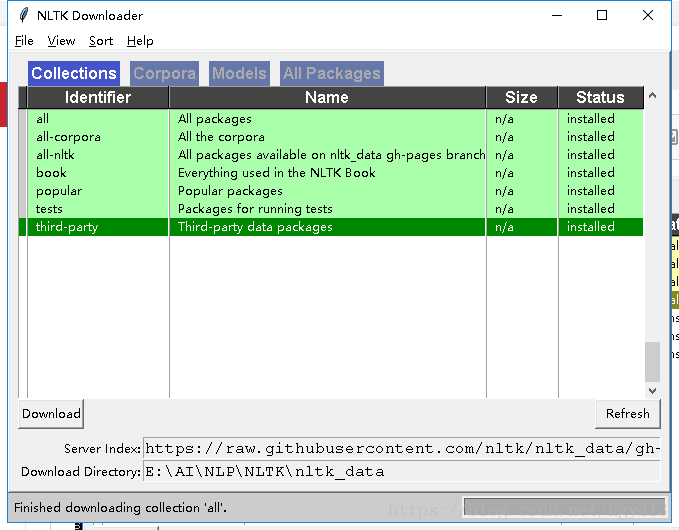
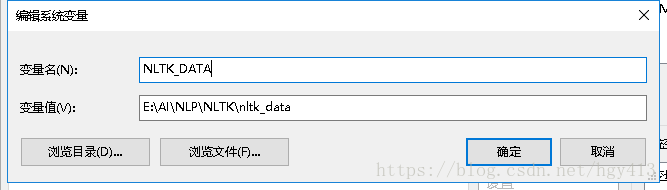
因为我们改了默认下载路径,所以需要加入环境变量NLTK_DATA
If you did not install the data to one of the above central locations, you will need to set the NLTK_DATA environment variable to specify the location of the data.
NLTK自带语料库
corpus(语料)
C:\Users\Administrator>python
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import nltk
>>> from nltk.corpus import brown
>>> brown.categories()// 类别
['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance', 'science_fiction']
>>> len(brown.sents())
57340
>>> len(brown.words())
1161192
>>>
文本处理流程
预处理----->分词预处理(Tokenize)----->特征表达式( Make Features)----->变成计算机可以理解的数字(ML)。
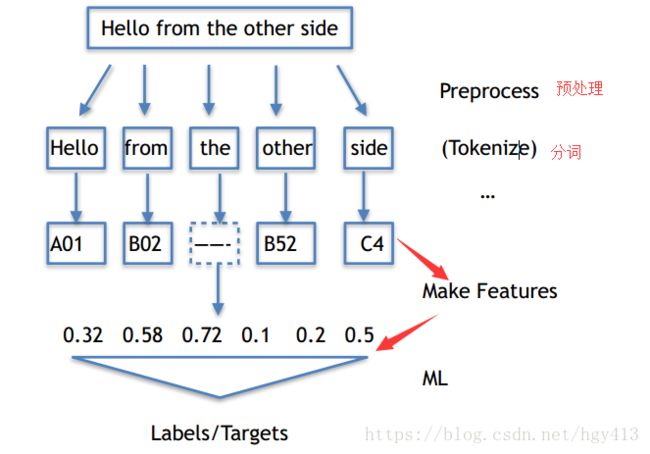
Tokenize
把长句⼦拆成有“意义”的⼩部件
C:\Users\Administrator>python
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import nltk
>>> str = "hello ,world"
>>> tokens = nltk.word_tokenize(str)
>>> tokens
['hello', ',', 'world']中英⽂NLP区别
中文因为没有空格,所以不好分词,所以给点特殊的分隔符。

启发式是从头开始找,使用字典查找的方式,找到一个单词,
今是单词吗?不是
今天是单词吗?是
今天天是单词吗?不是
。。。。
确认今天是最长的那个单词,拿下来,再从后面开始查找。
天是单词吗?不是
天气是单词吗?是
天气不是单词吗?不是
确认天气是最长的那个单词,拿下来。
。。。
中文分词类似于英文的单个字母。
中文分词
Python利用jieba(结巴)分词,安装方式和上面类似
C:\Users\Administrator>python -m pip install jieba
Collecting jieba
Downloading https://files.pythonhosted.org/packages/71/46/c6f9179f73b818d5827202ad1c4a94e371a29473b7f043b736b4dab6b8cd/jieba-0.39.zip (7.3MB)
100% |████████████████████████████████| 7.3MB 220kB/s
Installing collected packages: jieba
Running setup.py install for jieba ... done
Successfully installed jieba-0.39
You are using pip version 10.0.1, however version 18.0 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command.C:\Users\Administrator>python
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import jieba
>>> seg_list = jieba.cut("我来自西安交通大学",cut_all=True)#全模式
>>> print ("Full Mode:", "/".join(seg_list))
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.812 seconds.
Prefix dict has been built succesfully.
Full Mode: 我/来自/西安/西安交通/西安交通大学/交通/大学
>>> seg_list = jieba.cut("我来自西安交通大学",cut_all=False)#精确模式
>>> print ("Default Mode:", "/".join(seg_list))
Default Mode: 我/来自/西安交通大学
>>> seg_list=jieba.cut("他来到网易杭研大厦")#精确模式,新词识别,杭研并没在词典中,但被识别了
>>> print ("Default Mode:", "/".join(seg_list))
Default Mode: 他/来到/网易/杭研/大厦
>>> seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造"
... )#搜索引擎模式
>>> print ("Search Mode:", "/".join(seg_list))
Search Mode: 小明/硕士/毕业/于/中国/科学/学院/科学院/中国科学院/计算/计算所/,/后/在/日本/京都/大学/日本京都大学/深造
>>>
全模式:把所有可能的单词都列出来。
精确模式:只把这句话可以划分的单词列出来。
新词识别:也是精确模式,但它可以识别新词,如杭研。
搜索引擎模式:把所有的可搜的关键字全列出。
分词之后的效果
[‘what’, ‘a’, ‘nice’, ‘weather’, ‘today’]
[‘今天’, ’天⽓’, ’真’, ’不错’]
可以看出,分词之后,中文和英文没有什么区别了。
有时候tokenize没那么简单
⽐如社交⽹络上,这些乱七⼋糟的不合语法不合正常逻辑的语⾔很多:拯救 @某⼈, 表情符号, URL, #话题符号
社交⽹络语⾔的tokenize
举个栗⼦:
>>> import nltk
>>> from nltk.tokenize import word_tokenize
>>> tweet='RT @angelababy: love you baby! :D http://ah.love #168.cm'
>>> print(word_tokenize(tweet))
['RT', '@', 'angelababy', ':', 'love', 'you', 'baby', '!', ':', 'D', 'http', ':', '//ah.love', '#', '168.cm']
>>>可以看到这样划分是比较乱的。
写一个正则表达式类相关的python做处理:
import re
emoticons_str = r"""# r用于正则表达式,三个引号表示字符串跨行
(?:
[:=;] #眼睛
[oO\-]? #鼻子,
[D\)\]\(\]/\\OpP] #嘴
)"""
regex_str = [
emoticons_str,
r'<[^>]+>',# HTML tags
r'(?:@[\w_]+)',# @某人
r"(?:\#+[\w_]+[\w\'_\-]*[\w_]+)", # 话题标签
r'http[s]?://(?:[a-z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-f][0-9a-f]))+',# URLs
r'(?:(?:\d+,?)+(?:\.?\d+)?)', # 数字
r"(?:[a-z][a-z'\-_]+[a-z])", # 含有 - 和 ‘ 的单词
r'(?:[\w_]+)', # 其他
r'(?:\S)' # 其他
]
tokens_re = re.compile(r'('+'|'.join(regex_str)+')',re.VERBOSE | re.IGNORECASE)
emoticon_re = re.compile(r'^'+emoticons_str+'$', re.VERBOSE | re.IGNORECASE)
def tokenize(s):
return tokens_re.findall(s)
def preprocess(s, lowercase=False):
tokens = tokenize(s)
if lowercase:
tokens = [token if emoticon_re.search(token) else token.lower() for token in tokens]#如果在emoticon_re中,就不小写,比如笑脸符号
return tokens
tweet = 'RT @angelababy: love you baby! :D http://ah.love #168cm'
print(preprocess(tweet))
运行结果如下:
['RT', '@angelababy', ':', 'love', 'you', 'baby', '!', ':D', 'http://ah.love', '#168cm']
纷繁复杂的词形
Inflection变化: walk => walking => walked
不影响词性
derivation 引申: nation (noun名词) => national (adjective形容词) => nationalize (verb动词)
影响词性
词形归⼀化
Stemming 词⼲提取:⼀般来说,就是把不影响词性的inflection的⼩尾巴砍掉
walking 砍ing = walk
walked 砍ed = walk
Lemmatization 词形归⼀:把各种类型的词的变形,都归为⼀个形式
went 归⼀ = go
are 归⼀ = be
NLTK实现Stemming
提供了很多种方式,一般使用SnowballStemmer就好了
>>> from nltk.stem.porter import PorterStemmer
>>> porter_stemmer = PorterStemmer()
>>> porter_stemmer.stem('maximum')
'maximum'
>>> porter_stemmer.stem('presumably')
'presum'
>>> porter_stemmer.stem('multiply')
'multipli'
>>> porter_stemmer.stem('provis')
'provi'
>>> >>> from nltk.stem import SnowballStemmer
>>> snowball_stemmer = SnowballStemmer("english")
>>> snowball_stemmer.stem('maximum')
'maximum'
>>> snowball_stemmer.stem('presumably')
'presum'
>>> >>> from nltk.stem.lancaster import LancasterStemmer
>>> lasncaster_stemmer = LancasterStemmer()
>>> lasncaster_stemmer.stem('maximum')
'maxim'
>>> lasncaster_stemmer.stem('presumably')
'presum'NLTK实现Lemma
类似的
>>> from nltk.stem import WordNetLemmatizer
>>> wordnet_lemmatizer = WordNetLemmatizer()
>>> wordnet_lemmatizer.lemmatize("dogs")
'dog'
>>> wordnet_lemmatizer.lemmatize("churches")
'church'
>>> wordnet_lemmatizer.lemmatize("went")
'went'
>>> wordnet_lemmatizer.lemmatize("abaci")
'abacus'
>>> Lemma的⼩问题
比如Went,做为V(动词)它是go的过去式 做为n(名词)它是英文名:温特。
NLTK更好地实现Lemma
>>> from nltk.stem import WordNetLemmatizer
>>> wordnet_lemmatizer = WordNetLemmatizer()
>>> wordnet_lemmatizer.lemmatize('are')
'are'
>>> wordnet_lemmatizer.lemmatize('are',pos='v')
'be'
>>> 标志如下:

NLTK标注POS Tag
>>> import nltk
>>> text = nltk.word_tokenize("what does the fox say")
>>> text
['what', 'does', 'the', 'fox', 'say']
>>> nltk.pos_tag(text)
[('what', 'WDT'), ('does', 'VBZ'), ('the', 'DT'), ('fox', 'NNS'), ('say', 'VBP')]Stopwords
⼀千个HE有⼀千种指代
⼀千个THE有⼀千种指事
对于注重理解⽂本『意思』的应⽤场景来说
歧义太多
全体stopwords列表 http://www.ranks.nl/stopwords
NLTK去除stopwords
⾸先记得在console⾥⾯下载⼀下词库
或者 nltk.download(‘stopwords’)
>>> from nltk.corpus import stopwords
>>> word_list = nltk.word_tokenize("what does the fox say")
>>> word_list
['what', 'does', 'the', 'fox', 'say']
>>> filtered_words = [word for word in word_list if word not in stopwords.words('english')]
>>> filtered_words
['fox', 'say']⼀条typical的⽂本预处理流⽔线

分词-->词性归一化--->去掉Stopwords
什么是⾃然语⾔处理?
⾃然语⾔ ====》 计算机数据,也即特征工程。
⽂本预处理让我们得到了什么?

NLTK在NLP上的经典应⽤
> 情感分析
> ⽂本相似度
> ⽂本分类
应⽤:情感分析

哪些是夸你?哪些是⿊你?
最简单的 sentiment dictionary
like 1
good 2
bad -2
terrible -3
类似于关键词打分机制
⽐如: AFINN-111
http://www2.imm.dtu.dk/pubdb/views/publication_details.php?id=6010
NLTK完成简单的情感分析
import nltk
sentiment_dictionary = {}
for line in open('E:/AI/NLP/NLTK/nltk_data/AFINN/AFINN-111.txt'):
word, score = line.split('\t')
sentiment_dictionary[word] = int(score)
text = nltk.word_tokenize("bitterly blames blind")#需要测试的文本
total_score = sum(sentiment_dictionary.get(word,0) for word in text)
print(total_score)简单注意下,文件路径使用/而不是\,防止中间被视为转义了,for后面是有:的,以下是等效的
import nltk
sentiment_dictionary = {}
lines = open('E:/AI/NLP/NLTK/nltk_data/AFINN/AFINN-111.txt')
for line in lines:
word, score = line.split('\t')
sentiment_dictionary[word] = int(score)
text = nltk.word_tokenize("bitterly blames blind")#需要测试的文本
total_score = 0
for word in text:
total_score += sentiment_dictionary.get(word, 0)
print(total_score)返回结果
-5
线程 'MainThread' (0x48a8) 已退出,返回值为 0 (0x0)。Too Young Too Simple
显然这个⽅法太Naive
新词怎么办?
特殊词汇怎么办?
更深层次的玩意⼉怎么办?
配上ML的情感分析
from nltk.classify import NaiveBayesClassifier
# 随手造点训练集
s1 = 'this is a good book'
s2 = 'this is a awesome book'
s3 = 'this is a bad book'
s4 = 'this is a terrible book'
def preprocess(s):
# Func: 句⼦处理
# 这⾥简单的⽤了split(), 把句⼦中每个单词分开
# 显然 还有更多的processing method可以⽤
return {word: True for word in s.lower().split()}
# return⻓这样:
# {'this': True, 'is':True, 'a':True, 'good':True, 'book':True}
# 其中, 前⼀个叫fname, 对应每个出现的⽂本单词;
# 后⼀个叫fval, 指的是每个⽂本单词对应的值。
# 这⾥我们⽤最简单的True,来表示,这个词『出现在当前的句⼦中』的意义。
# 当然啦, 我们以后可以升级这个⽅程, 让它带有更加⽜逼的fval, ⽐如 word2vec
#输出一个试试
tokens = preprocess(s1)
for v,k in tokens.items():
print('{v}:{k}'.format(v=v,k=k))#{}为占位符
print("-----------------------------------------------------------")
# 把训练集给做成标准形式
training_data = [[preprocess(s1), 'pos'],
[preprocess(s2), 'pos'],
[preprocess(s3), 'neg'],
[preprocess(s4), 'neg']]
# 喂给model吃
model = NaiveBayesClassifier.train(training_data)
# 打出结果
print(model.classify(preprocess('this is a good book')))输出结果:
this:True
is:True
a:True
good:True
book:True
-----------------------------------------------------------
pos应⽤:⽂本相似度
⽤元素频率表⽰⽂本特征
| we | you | he | work | happy | are |
| 1 | 0 | 3 | 0 | 1 | 1 |
| 1 | 0 | 2 | 0 | 1 | 1 |
| 0 | 1 | 0 | 1 | 0 | 0 |
就是单词出现的次数。
比如第一列[1,0,3,0,1,1],可能的语句是"hehehe,we are happy"。
比如第二列[1,0,2,0,1,1],可能的语句是"hehe,we are happy"。
比如第二列[0,1,0,1,0,0],可能的语句是"you work"。
余弦相似度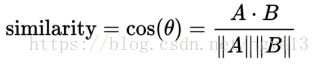
分子为向量A与向量B的点乘,分母为二者各自的L2相乘,即将所有维度值的平方相加后开方。
余弦相似度的取值为[-1,1],值越大表示越相似。
可以看到,第一列和第二列的cos夹角是相似的。
Frequency 频率统计
import nltk
from nltk import FreqDist
# 做个词库先
corpus = 'this is my sentence ' \
'this is my life ' \
'this is the day'
# 随便tokenize⼀下
# 显然, 正如上⽂提到,
# 这⾥可以根据需要做任何的preprocessing:
# stopwords, lemma, stemming, etc
tokens = nltk.word_tokenize(corpus)
print(tokens)
# 得到token好的word list
# ['this', 'is', 'my', 'sentence', 'this', 'is', 'my', 'life', 'this','is', 'the', 'day']
fdist = FreqDist(tokens)
print('---------------------------------------------------------------------')
# 它就类似于⼀个Dict
# 带上某个单词, 可以看到它在整个⽂章中出现的次数
print('is 出现的次数:',fdist['is'])
print('---------------------------------------------------------------------')
for v,k in fdist.items():
print('{v}:{k}'.format(v=v,k=k))
print('---------------------------------------------------------------------')
# 好, 此刻, 我们可以把最常⽤的50个单词拿出来
standard_freq_vector = fdist.most_common(50)
size = len(standard_freq_vector)
print(standard_freq_vector)
print('---------------------------------------------------------------------')
# Func: 按照出现频率⼤⼩, 记录下每⼀个单词的位置
def position_lookup(v):
res = {}
counter = 0
for word in v: #word即{key:value}
res[word[0]] = counter
counter += 1
return res
# 得到⼀个位置对照表
# {'this': 0, 'is': 1, 'my': 2, 'sentence': 3, 'life': 4, 'the': 5, 'day': 6}
standard_position_dict = position_lookup(standard_freq_vector)
print(standard_position_dict)
print('---------------------------------------------------------------------')
# 这时, 如果我们有个新句⼦:
sentence = "this is cool"
# 先新建⼀个跟我们的标准vector同样⼤⼩的向量
freq_vector = [0]*size
tokens = nltk.word_tokenize(sentence)
# 对于这个新句⼦⾥的每⼀个单词
for word in tokens:
try:
# 如果在我们的词库⾥出现过
# 那么就在"标准位置"上+1
freq_vector[standard_position_dict[word]] += 1
except KeyError:# key错误
# 如果是个新词
# 就pass掉
continue
print(freq_vector)
# [1, 1, 0, 0, 0, 0, 0]
# 第⼀个位置代表 this, 出现了⼀次
# 第⼆个位置代表 is, 出现了⼀次
# 后⾯都⽊有输出结果:
['this', 'is', 'my', 'sentence', 'this', 'is', 'my', 'life', 'this', 'is', 'the', 'day']
---------------------------------------------------------------------
is 出现的次数: 3
---------------------------------------------------------------------
this:3
is:3
my:2
sentence:1
life:1
the:1
day:1
---------------------------------------------------------------------
[('this', 3), ('is', 3), ('my', 2), ('sentence', 1), ('life', 1), ('the', 1), ('day', 1)]
---------------------------------------------------------------------
{'this': 0, 'is': 1, 'my': 2, 'sentence': 3, 'life': 4, 'the': 5, 'day': 6}
---------------------------------------------------------------------
[1, 1, 0, 0, 0, 0, 0]
应⽤:⽂本分类
TF-IDF
TF: Term Frequency, 衡量⼀个term在⽂档中出现得有多频繁。
TF(t) = (t出现在⽂档中的次数) / (⽂档中的term总数).
IDF: Inverse Document Frequency, 衡量⼀个term有多重要。
有些词出现的很多,但是明显不是很有卵⽤。⽐如’is', ’the‘, ’and‘之类
的。
为了平衡,我们把罕见的词的重要性(weight)搞⾼,
把常见词的重要性搞低。
IDF(t) = log_e(⽂档总数 / 含有t的⽂档总数).
TF-IDF = TF * IDF
举个栗⼦
⼀个⽂档有100个单词,其中单词baby出现了3次。
那么, TF(baby) = (3/100) = 0.03.
好,现在我们如果有10M的⽂档, baby出现在其中的1000个⽂档中。
那么, IDF(baby) = log(10,000,000 / 1,000) = 4
如果baby出现在其中的10000个⽂档中。
那么, IDF(baby) = log(10,000,000 / 1,000) =3,我们可以看到,出现的的越多的常用词IDF越低。
所以, TF-IDF(baby) = TF(baby) * IDF(baby) = 0.03 * 4 = 0.12
from nltk.text import TextCollection
# ⾸先, 把所有的⽂档放到TextCollection类中。
# 这个类会⾃动帮你断句, 做统计, 做计算
corpus = TextCollection(['this is sentence one',
'this is sentence1 two',
'this is sentence2 three'])
# 直接就能算出tfidf
# (term: ⼀句话中的某个term, text: 这句话)
print(corpus.tf_idf('sentence1', 'this is sentence1 four'))结果:
0.04993692221218681# 同理, 怎么得到⼀个标准⼤⼩的vector来表示所有的句⼦?
# 对于每个新句⼦
new_sentence = 'this is sentence five'
# 遍历⼀遍所有的vocabulary中的词:
for word in standard_vocab:
print(corpus.tf_idf(word, new_sentence))
# 我们会得到⼀个巨⻓(=所有vocab⻓度)的向量接下来?
使用向量代入ML模式
可能的ML模型:
SVM
LR
RF
MLP
LSTM
RNN
….