Delta Lake 基本操作(Scala)
文章目录
- Maven配置
- 数据源
- Source表
- Merge表
- 操作
- 生成Delta表
- Update数据
- Delete数据
- Merge数据
- 问题
- 版本回溯(Time Travel)
- 查看版本号为0的数据
- 查看版本号为3的数据
- 并发写入测试
- 操作相同数据
- 操作不同数据
- 原因
- 详情见官方文档
Maven配置
<dependency>
<groupId>io.deltagroupId>
<artifactId>delta-core_2.11artifactId>
<version>0.4.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.4.3version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>2.4.3version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>2.4.3version>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-reflectartifactId>
<version>2.11.8version>
dependency>
数据源
Source表
001,张三,男,23,1000
002,李四,女,23,1500
003,王五,男,22,1000
004,马六,女,22,1000
005,何何,男,22,1000
006,家家,女,22,1000
007,乐乐,男,22,1000
Merge表
001,张三,9999
002,李四,9999
004,马六,9999
006,家家,9999
007,乐乐,9999
008,aa,9999
009,bb,9999
010,cc,9999
操作
生成Delta表
case class Source(id: String, name: String, sex: String, age: String, money: String)
import sparkSession.implicits._
val sc = sparkSession.sparkContext
// sourceDF
val sourceDF = sc.textFile("C:\\develop\\IDEA_Pro\\Spark2\\src\\data2\\source.txt")
.map(line => {
val arr = line.split(",")
Source(arr(0), arr(1), arr(2), arr(3), arr(4))
}).toDF
// write DataFrame as Delta
sourceDF
.write
.format("delta")
.mode("overwrite")
.save("C:\\develop\\IDEA_Pro\\Spark2\\src\\data2\\source")
查看表目录

查看事务日志
{"commitInfo":{"timestamp":1573556153112,"operation":"WRITE","operationParameters":{"mode":"Overwrite","partitionBy":"[]"},"isBlindAppend":false}}
{"protocol":{"minReaderVersion":1,"minWriterVersion":2}}
{"metaData":{"id":"7947cb54-8865-46ce-b55e-d70223820ff1","format":{"provider":"parquet","options":{}},"schemaString":"{\"type\":\"struct\",\"fields\":[{\"name\":\"id\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"sex\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"age\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"money\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}}]}","partitionColumns":[],"configuration":{},"createdTime":1573556149918}}
{"add":{"path":"part-00000-0094a4cf-b47b-490e-b0fe-f1dc67567d16-c000.snappy.parquet","partitionValues":{},"size":1288,"modificationTime":1573556151195,"dataChange":true}}
Update数据
val sourceTable = DeltaTable.forPath(sparkSession, "C:\\develop\\IDEA_Pro\\Spark2\\src\\data2\\source")
//sex='男' money字段后拼接'-11'
sourceTable.update(expr("sex=='男'"), Map("money" -> expr("concat(money, '-11')")))
sourceTable.toDF.show(false)
查看数据

查看表目录

查看事务日志
{"commitInfo":{"timestamp":1573556678631,"operation":"UPDATE","operationParameters":{"predicate":"(sex#664 = 男)"},"readVersion":0,"isBlindAppend":false}}
{"remove":{"path":"part-00000-0094a4cf-b47b-490e-b0fe-f1dc67567d16-c000.snappy.parquet","deletionTimestamp":1573556678114,"dataChange":true}}
{"add":{"path":"part-00000-74b118fb-3229-4b5c-afc8-7e9b8e0ba241-c000.snappy.parquet","partitionValues":{},"size":1300,"modificationTime":1573556678597,"dataChange":true}}
可以看到事务日志中记录remove旧文件, add新文件, 但是remove文件只是在逻辑上删除, 并不会在磁盘上删除, 如需要可以调用vacuum()方法删除磁盘文件
Delete数据
val sourceTable = DeltaTable.forPath(sparkSession, "C:\\develop\\IDEA_Pro\\Spark2\\src\\data2\\source")
sourceTable.delete(expr("sex=='男'"))
sourceTable.toDF.show(false)
查看数据

查看表目录

查看事务日志
{"commitInfo":{"timestamp":1573556959653,"operation":"DELETE","operationParameters":{"predicate":"[\"(`sex` = '男')\"]"},"readVersion":1,"isBlindAppend":false}}
{"remove":{"path":"part-00000-74b118fb-3229-4b5c-afc8-7e9b8e0ba241-c000.snappy.parquet","deletionTimestamp":1573556959641,"dataChange":true}}
{"add":{"path":"part-00000-59c055a4-cb8a-4517-9728-b8560ea39eda-c000.snappy.parquet","partitionValues":{},"size":1244,"modificationTime":1573556959619,"dataChange":true}}
Merge数据
val sourceTable = DeltaTable.forPath(sparkSession, "C:\\develop\\IDEA_Pro\\Spark2\\src\\data2\\source")
val mergeTable = DeltaTable.forPath(sparkSession, "C:\\develop\\IDEA_Pro\\Spark2\\src\\data2\\merge")
sourceTable.as("source")
.merge(mergeTable.toDF.coalesce(1).as("merge"), "source.id=merge.id")
.whenMatched()
.update(Map("money" -> col("merge.money")))
.execute()
sourceTable.toDF.show(false)
查看数据
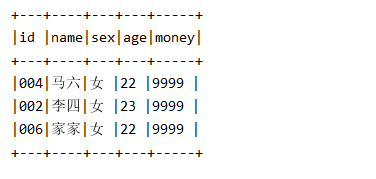
查看表目录
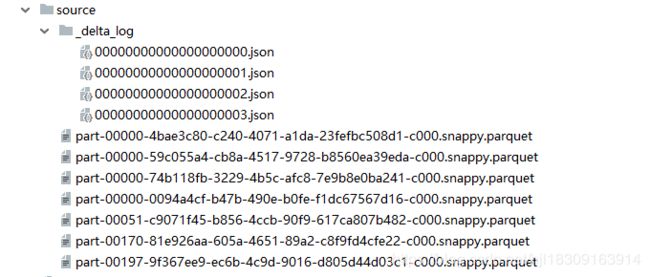
查看事务日志
{"commitInfo":{"timestamp":1573557302752,"operation":"MERGE","operationParameters":{"predicate":"(source.`id` = merge.`id`)"},"readVersion":2,"isBlindAppend":false}}
{"remove":{"path":"part-00000-59c055a4-cb8a-4517-9728-b8560ea39eda-c000.snappy.parquet","deletionTimestamp":1573557302730,"dataChange":true}}
{"add":{"path":"part-00000-4bae3c80-c240-4071-a1da-23fefbc508d1-c000.snappy.parquet","partitionValues":{},"size":577,"modificationTime":1573557299796,"dataChange":true}}
{"add":{"path":"part-00051-c9071f45-b856-4ccb-90f9-617ca807b482-c000.snappy.parquet","partitionValues":{},"size":1207,"modificationTime":1573557302538,"dataChange":true}}
{"add":{"path":"part-00170-81e926aa-605a-4651-89a2-c8f9fd4cfe22-c000.snappy.parquet","partitionValues":{},"size":1207,"modificationTime":1573557302646,"dataChange":true}}
{"add":{"path":"part-00197-9f367ee9-ec6b-4c9d-9016-d805d44d03c1-c000.snappy.parquet","partitionValues":{},"size":1207,"modificationTime":1573557302709,"dataChange":true}}
问题
在merge的时候source.merge(mergeDF),会导致merge之后的结果产生很多个小文件, 如上图事务日志中merge更新了几条数据就产生四个文件, 如果更新几十万或者几百万文件是否会产生几百万个小文件
查遍了官方文档和社区也没找到解决方法, 可能在后续版本中会有所改进吧
但是如果需要将merge之后的结果转存到另一个表中倒是可以这么写
val sourceTable = DeltaTable.forPath(sparkSession, "C:\\develop\\IDEA_Pro\\Spark2\\src\\data2\\source")
val mergeTable = DeltaTable.forPath(sparkSession, "C:\\develop\\IDEA_Pro\\Spark2\\src\\data2\\merge")
sourceTable.as("source")
.merge(mergeTable.toDF.coalesce(1).as("merge"), "source.id=merge.id")
.whenMatched()
.update(Map("money" -> col("merge.money")))
.execute()
sourceTable.toDF
.coalesce(1)
.write
.format("delta")
.mode("overwrite")
.save("C:\\develop\\IDEA_Pro\\Spark2\\src\\data2\\result")
sourceTable.toDF.show(false)
版本回溯(Time Travel)
查看版本号为0的数据
sparkSession
.read
.format("delta")
.option("versionAsOf", 0)
.load("C:\\develop\\IDEA_Pro\\Spark2\\src\\data2\\source")
.show()
查看数据

查看版本号为3的数据
sparkSession
.read
.format("delta")
.option("versionAsOf", 3)
.load("C:\\develop\\IDEA_Pro\\Spark2\\src\\data2\\source")
.show()
查看数据

并发写入测试
先后启动两个程序,模拟两个用户
两个用户读取版本为0的数据(同源)
操作相同数据
User1对sex为男的数据操作
User2对sex为男的数据操作
常识告诉我们这样子的不允许的
// User1和User2的代码相同
// 分别放在两个程序中执行
val sourceTable = DeltaTable.forPath(sparkSession, "C:\\develop\\IDEA_Pro\\Spark2\\src\\data2\\source")
sourceTable.update(expr("sex=='男'"), Map("money" -> expr("concat(money, '-100')")))
sourceTable.toDF.show(false)
查看事务日志, 看到除了数据源之外, 只产生了一次提交, 另一次提交引起冲突异常了
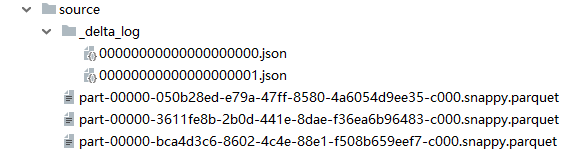
User1执行结果:

User2执行结果:

由控制台日志可知, User2的提交与User1的提交冲突, 原因是操作了相同数据
操作不同数据
User1对sex为男的数据操作
User2对sex为女的数据操作
常识告诉我们这样子是允许的, 不同用户操作不同数据互相写数据的不冲突的
// 要分别放在两个程序中执行
// User1
val sourceTable = DeltaTable.forPath(sparkSession, "C:\\develop\\IDEA_Pro\\Spark2\\src\\data2\\source")
sourceTable.update(expr("sex=='男'"), Map("money" -> expr("concat(money, '-100')")))
sourceTable.toDF.show(false)
// User2
val sourceTable = DeltaTable.forPath(sparkSession, "C:\\develop\\IDEA_Pro\\Spark2\\src\\data2\\source")
sourceTable.update(expr("sex=='女'"), Map("money" -> expr("concat(money, '-100')")))
sourceTable.toDF.show(false)
User1执行结果

User2执行结果

查看事务日志, 除了版本0的数据源之外, 还产生了两次提交
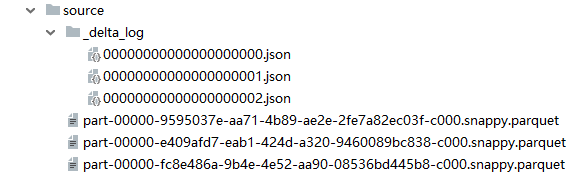
由执行结果可见, 两个User同时读取同一份数据源, User1先完成提交更新了数据, User1更新的数据对User2来说是可见的
因为User2在提交的时候,会检查目前最新的表中是否有数据变动, 如变动会读取最新的数据, 然后再次提交
当然上述结果产生的前提就是, 多个用户之间的操作不会冲突
原因
Delta Lake表在多用户提交的场景中
多个用户可以同时写一个表, 但是在同一时间只能一个用户提交事务成功(乐观锁 - 允许多个线程同时读同一份数据, 但是只允许一个线程写数据)
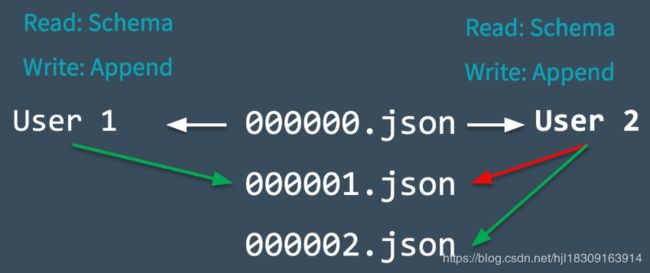
- User1和User2同时读取000000.json
- User1和User2尝试同时往表中写入数据, 这里产生冲突
- Delta Lake通过锁机制解决冲突, 只能有一个User提交成功, 假设User1提交成功, 写入日志为000001.json
- User2在提交失败后会检查之前读到的数据源有无变化, 如有变化会更新读到的数据, 然后再最新数据的基础上尝试重新提交000002.json
绝大多数情况下, 这种解决冲突的方式是很快进行的
但是出现了无法解决的冲突(上述例子)(User1删除了User2也要删除的文件), 这种情况下就会抛出异常