爬虫技术概览
爬虫介绍
简介
自动化、半自动化从互联网上采集数据的程序。
爬虫框架
一个简单的爬虫框架:
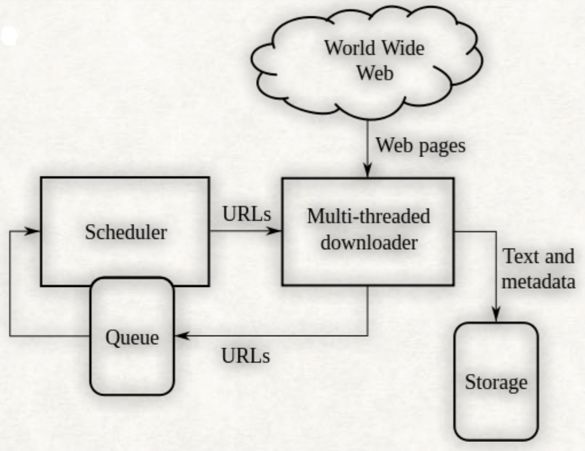
如上图,通常爬虫会有一份种子URL,放在待抓取队列,通过scheduler调度这些url,交由downloader去下载网页数据,
进行数据的清洗解析,获取到所需要的信息进行存储,并将新解析出的有用URL放入待抓取队列。
爬虫的各个阶段
调度阶段
下图是调度系统通常需要考虑的一些事情。

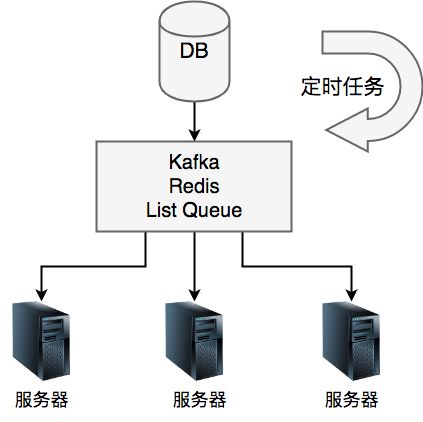
下图是一个简单的调度模块,由一个Crane定时任务+queue队列来实现一个基本的调度。
下载阶段
通常通过封装HttpClient、HttpUrlConnection来实现下载器。
HttpClient的应用举例
//HttpClient的使用样例,下面是一个GET请求,PostMethod可以发送post请求,同理也可发送delete、put、head请求。
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.collections.ListUtils;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpException;
import org.apache.commons.httpclient.HttpMethod;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.lang.StringUtils;
import java.io.IOException;
public static void main(String[] args) {
HttpClient httpClient = new HttpClient();
HttpMethod httpMethod = new GetMethod("http://www.sina.com.cn");
httpMethod.addRequestHeader("Content-Type", "text/html;charset=utf-8"); //这里设置字符编码,避免乱码
int statusCode = -1;
byte[] result = null;
try {
statusCode = httpClient.executeMethod(httpMethod);
if (statusCode != HttpStatus.SC_OK) {//判断返回
System.out.println("get failure!");
return;
}
if (httpMethod.getResponseBody() != null) {//获取页面数据
result = httpMethod.getResponseBody();//hm.getStatusLine()――http状态和请求结果
}
} catch (HttpException e1) {
e1.printStackTrace();
} catch (IOException e2) {
e2.printStackTrace();
} finally {
httpMethod.releaseConnection();
}
if (result != null) {
try {
String data = new String(result, "UTF-8");//字符编码设置
System.out.println(data);//测试输出
} catch (Exception e) {
LOGGER.info("an exception! e = {}", e);
}
}
}
//jar包依赖
/*
commons-httpclient
commons-httpclient
3.1
*/
-
post请求可以用于模拟登录网页等操作,是常用到的一种请求方式,post请求一般需要携带header、cookie等信息。
-
此类方式抓到的数据都是未经过JS渲染的。
-
todo增加一篇详细的httpclient等下载方式的介绍。以及模拟登录的实现样例。
解析阶段
此阶段主要是将下载阶段获取的html文本或者其他格式的数据进行格式化,抽取出我们要求的信息。
常见的解析手段
正则
todo正则表达式的详细介绍
Xpath
即XML路径语言(XMLPathLanguage),它是一种用来确定XML文档中某部分位置的语言。
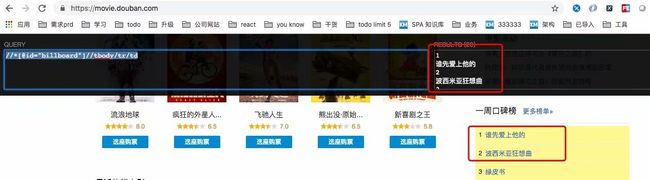
比如要定位https://movie.douban.com/ 中右侧的一周口碑榜
只需要一句话:
//*[@id=“billboard”]//tbody/tr/td
如下图:
Jsoup
如果要解析一篇文章,由于文章内容分散在各个节点上,此时用正则或者xpath就不太方便了,还是得用Jsoup递归一下所有节点。
todo jsoup的详细介绍
4>其他
其它方式如string.index。
###存储阶段
####es
####db
####hive
####其他
此阶段不过多介绍。
常见的数据抓取方式
web/i版网页抓取
web网页和i版网页是相对比较好抓取的一种页面。通常情况下,数据会存在于html文本、ajax请求中,不过也会遇到一些情况使得抓取变得相当复杂:数据进行了加密、数据存在于图片等载体、请求有验签、未知含义cookie等等。
举例
腾讯视频的播放数、评论数抓取:https://v.qq.com/x/cover/rvkqtjee5rvbj38/f0521wc8x2i.html
-
首先根据页面展示关键字去搜索播放、评论数是否存在于html文本中,参见 view-source:https://v.qq.com/x/cover/rvkqtjee5rvbj38/f0521wc8x2i.html,显然播放数存在于html文本中,而评论数不存在。
-
打开审查元素(chrome下,左键选择检查),然后进行下面的操作。
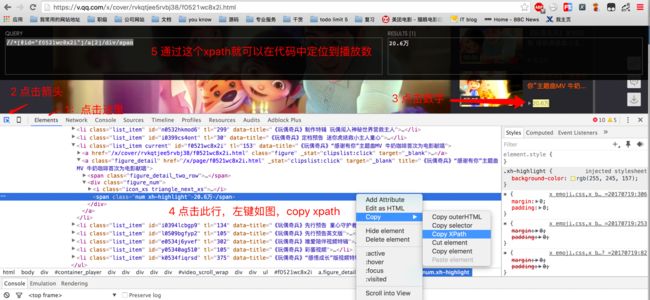
3.如上已经拿到了播放数,此时下拉网页,拉的快的话,可以发现评论区没有数据,过了半秒的样子刷新出了数据,此时可以很明显的判断出这是一个ajax请求。
4.此时打开审查元素,切换到Network页面,刷新下网页可以发现有许多的请求,一个html页面会有许多请求。其中有一个 https://coral.qq.com/article/1886906224/commentnum?callback=jQuery112405035975130740553_1504434583371&_=1504434583372 此请求中包含所需要的评论数。
url中的1886906224为评论id,需要在请求主页面的返回结果中获取,1504434583372为时间戳。
模拟浏览器抓取
通过web/i版页面进行抓取有许多的限制,比如有较多的cookie信息需要破解、拼凑,数据加密,拿到的数据非JS渲染后的页面等等。
此时我们可以通过真实的浏览器去做数据抓取,此时强大的selenuim就要出场了!
selenuim包括一些浏览器driver,这些driver可以做一些浏览器所做的事情,通过一些api实现浏览器的控制操作。
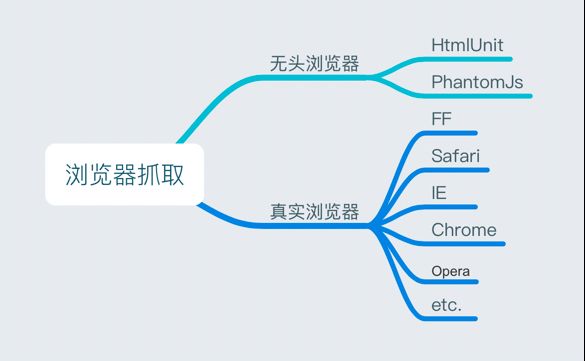
无头浏览器(伪浏览器),没有GUI,而是具有支持html、js等解析能力的类浏览器程序,支持页面元素的查找、JS的执行等。
由于不进行GUI渲染,所以运行效率上会比真实浏览器要快很多。
在真实的抓取中,考虑到效率问题以及服务器没有界面,我们通常采用无头浏览器,其中htmlunit的js解析引擎是Rhino,对JS的支持不好。所以大多数人采用的是PhantomJS。
| 常见应用 | 举例 |
|---|---|
| 绕过复杂请求 | 模拟打开指定网页,通过api获取网页数据进行解析。 |
| 获取cookie | 通过api模拟登录指定网站,获取登录cookie用于请求对方API接口,抓取该网站的数据。 |
| 破解验证码 | 对于拖拽式、点击式验证码,通过phantomJs可以较容易的绕过。 |
PhantomJs登录微博获取Cookie举例
//文件一:
package com.xxx.service.movie.loki.spider.weibo;
import com.xxx.service.movie.loki.utils.SeleniumUtils;
import org.openqa.selenium.By;
import org.openqa.selenium.Cookie;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.awt.image.BufferedImage;
import java.util.Set;
/**
* Created by xiehonghao on 17/4/25.
*/
public class WeiboLoginCookieSpider {
private static final Logger LOGGER = LoggerFactory.getLogger(WeiboLoginCookieSpider.class);
private static final WebDriver driver = SeleniumUtils.getPhantomJSDriver();
public void getLoginCookie() {
driver.get("http://weibo.com/tv/v/F07DPgqEG?from=vfun#_loginLayer_1493102099143");
BufferedImage image = SeleniumUtils.getScreenshot(driver);
tryLogin();
Set cookieSet = driver.manage().getCookies();
int kk = 10;
}
private static boolean tryLogin() {
boolean hasLogined = true;
//寻找登录窗口元素
WebElement userNameElement = SeleniumUtils.findElement(driver, By.xpath("//*[@id=\"loginname\"]"));
if (userNameElement != null) {
userNameElement.sendKeys("[email protected]");
hasLogined = false;
}
if (hasLogined) {
return true;
}
WebElement passwordElement = SeleniumUtils.findElement(driver, By.name("password"));
if (passwordElement != null) {
passwordElement.sendKeys("maizangsb");
} else {
LOGGER.error("tryLogin to baidu failure, not found element TANGRAM_12__password");
return false;
}
WebElement submitElement = SeleniumUtils.findElement(driver, By.xpath("//*[@id=\"pl_login_form\"]/div/div[3]/div[6]/a"));
if (submitElement != null) {
submitElement.click();
} else {
LOGGER.error("tryLogin failure");
return false;
}
return true;
}
public static void main(String[] args) {
WeiboLoginCookieSpider weiboLoginCookieSpider = new WeiboLoginCookieSpider();
weiboLoginCookieSpider.getLoginCookie();
}
}
//文件二:
package com.xxx.service.movie.loki.utils;
import org.openqa.selenium.By;
import org.openqa.selenium.OutputType;
import org.openqa.selenium.TakesScreenshot;
import org.openqa.selenium.TimeoutException;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.ByteArrayInputStream;
import java.io.InputStream;
/**
* Created by xiehonghao on 17/3/15.
*/
public class SeleniumUtils {
private static final Logger LOGGER = LoggerFactory.getLogger(SeleniumUtils.class);
static {
System.setProperty("phantomjs.binary.path", "你的phantomJs路径");
}
public static WebDriver getPhantomJSDriver() {
WebDriver driver = null;
try {
driver = new PhantomJSDriver();
} catch (Exception e) {
LOGGER.error("phantomJs driver initialization failure!");
return null;
}
driver.manage().window().maximize();
return driver;
}
public static WebElement findElement(WebDriver driver, By by) {
try {
return driver.findElement(by);
} catch (Exception e) {
LOGGER.info("find element throws an exception!, e = {}", e);
return null;
}
}
public static void waitUntilAppear(WebDriver driver, By by, int timeOutInSeconds) {
WebDriverWait wait = new WebDriverWait(driver, timeOutInSeconds);
try {
wait.until(ExpectedConditions.visibilityOfElementLocated(by));
} catch (TimeoutException e) {
LOGGER.info("wait element appear throws an exception!, e = {}", e);
}
}
public static BufferedImage getScreenshot(WebDriver driver) {
BufferedImage bufferedImage = null;
TakesScreenshot shot = ((TakesScreenshot) driver);
InputStream inputStream = null;
try {
byte[] bytes = shot.getScreenshotAs(OutputType.BYTES);
inputStream = new ByteArrayInputStream(bytes);
bufferedImage = ImageIO.read(inputStream);
} catch (Exception e) {
LOGGER.error("getScreenshot throws an exception! e = {}", e);
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (Exception e) {
LOGGER.error("close inputStream throws an exception! e = {}", e);
}
}
}
return bufferedImage;
}
}
客户端接口抓取
当一些信息存在于客户端,这时候就要涉及客户端抓取了,客户端的数据一般是JSON结构,更加容易解析,不过抓包相对web/i版会比较麻烦,另外对于https抓包还需要在手机上安装抓包工具生成的证书。
常见的抓包工具,这些工具支持i版、web版、客户端等类型的抓包。
| 抓包工具 | 介绍 |
|---|---|
| charles | mac下的一款小巧强大的抓包工具,支持分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据等功能 |
| fiddler | 和charles支持功能差不多。 |
| wireshark | 到任何协议的数据(不过除了http、https协议,其它协议的数据也看不懂…)。 |
抓到数据后,其它流程就和web版、i版抓取类似了。注意抓包时,手机和电脑要在同一个局域网内。
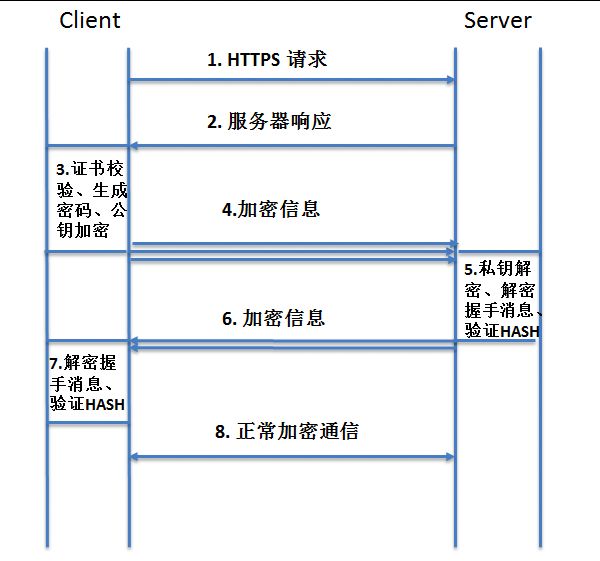
现在拿https抓包做个分析,看下抓包的原理:中间人攻击
首先来看下正常的请求流程。
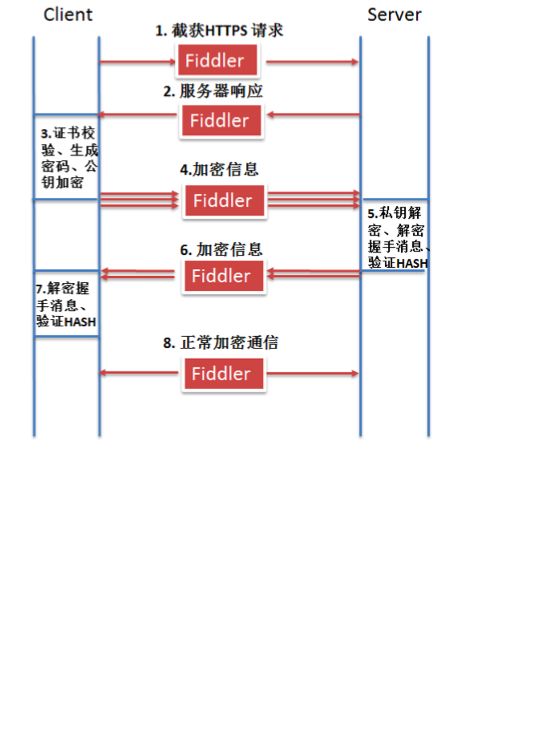
下面是中间人攻击抓包的原理图:
APP破解抓取
当一些数据仅存在于APP中,且数据请求非http、https或者存在数据加密等难题时,这时候可以尝试下通过破解APP来获取app内已经解析出的数据。
我们来看下我们目前在用的一种破解方法:动态hook修改原代码的执行逻辑,在这之前先来了解一些一下Xposed框架、UIAutomator。
Xposed框架
####介绍:
Xposed框架是一款可以在不修改APK的情况下影响程序、系统运行的框架服务,基于它可以制作出许多功能强大的模块,且在功能不冲突的情况下同时运作。
原理:
通过替换 /system/bin/app_precesss 程序控制zygote进程,
使得它在系统启动的过程中会加载Xposed框架的jar文件即XposedBridge.jar,
从而完成对Zygote进程及其创建的Dalvik虚拟机的劫持,并且能够允许开发者独立的替代任何class,从后修改framework本身、系统UI又或者随意的一个app。
我们通常用它来实现对一个APP的方法劫持(HOOK),在方法前后嵌入自己的逻辑。
使用方法:
http://blog.csdn.net/p106786860/article/details/52213695
###UIAutomator
一个自动化测试框架,通过该框架可以实现操纵手机,比如进行点击、拖动、输入、打开关闭APP等各种操作。
一个操作流程需要自己去写代码去组合实现,相对按键精灵等工具,这种方式写的程序更加健壮。
todo 教程 UIAutomator模拟淘票票下单
效果演示 http://v.meituan.net/movie/videos/9e2d1f074f2c4568a22792dafc87b963.mp4
破解流程
1.首先APP破解通过需要经过反编译(如果加壳了,需要在反编译前进行脱壳),获取反编译后的代码。
常见的反编译软件有:
1) APKtool
2) dex2jar
3) jd-gui
4) 签名工具
2.分析反编译后的代码,找到目标类和方法,此时的代码是高度混淆的,类名、方法名、变量名都是简短的字符如a 、aa、f、ab等。
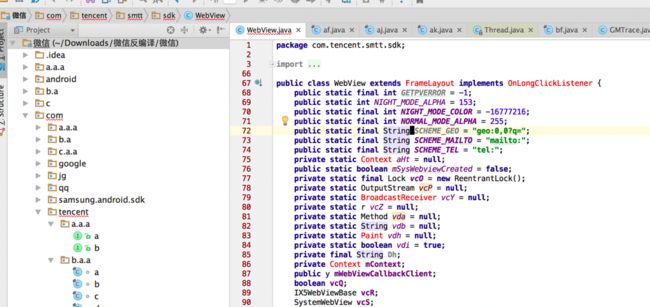
此时有一些小技巧用来定位想要的类方法。
1)关键字搜索。
2)找到输出日志方法,hook该方法分析请求日志)
3) hook相关调用的底层方法,并在其中抛出异常,打出调用栈。
3.定位到想要的方法后,通过Xposed hook框架hook指定代码,在指定方法前后嵌入自己的逻辑。
4.通过UIAutomator等工具实现定时自动触发操作进行数据抓取。
应用举例
抓取淘票票卖品、影票基础价、活动价等数据,在淘票票app上下单后可以展现卖品、价格等数据。通过如下流程进行数据的抓取
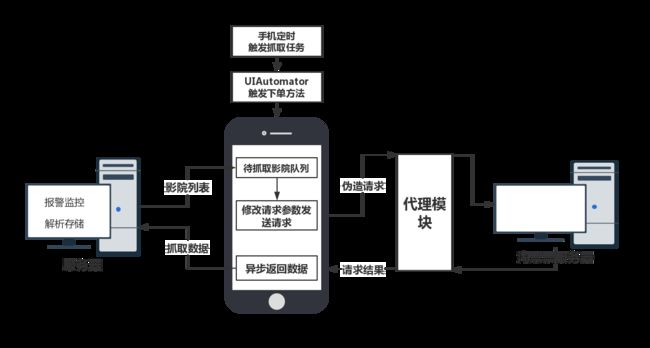
- 首先UIAutomator模拟点击至下单页面,触发请求卖品数据的方法A的上一层方法B(B方法已经被HOOK)。
- 在B方法中请求内部服务器获取待抓取影院队列。此时替换B方法中的影院id等参数,循环调用A方法(即请求淘票票卖品、票价数据的方法)。
- 通过对接收请求结果的方法的HOOK,我们可以拿到淘票票异步返回的卖品数据,然后上传至清洗服务器。
以上为个人学习测试所操作,请勿模仿或用于商业用途,本人不负任何法律责任。
#爬虫的对抗
在爬虫的世界,存在着一个死循环:爬虫、反爬虫、反反爬虫、反反反爬虫…
| 反爬虫策略 | 介绍 | 反反爬虫策略 |
|---|---|---|
| 阈值:如ip请求次数超过限制。 | 常见于 用户请求限制 ip请求次数限制 |
1.降低请求频率。 2.ip代理池。 |
| Heads:请求必须要携带某些请求header。 | 通常不正常的header会被判定为爬虫。 | 1.对于user agent使用user agent池。 2.根据具体网站设置refer信息。 3.其它header信息视情况而定。 |
| ajax请求 | ajax请求 一个网页的数据会包含多个ajax请求。 | 1.分析所有请求,定位真正返回数据的请求,构造请求参数。 2.无头浏览器。 |
| 验签 | 通常由前端生成信息,后端进行验证。 | 1.调试前端代码,定位验证逻辑代码进行分析出逻辑或定位到代码后直接在工程内通过javascript引擎执行。 2.无头浏览器、app破解。 |
| cookie | 通常登录、发送请求都需要传递cookie,且有些连续请求页面需要依赖前面请求产生的cookie。 | 1.若需要登录cookie,且难以实现模拟登录,可以手动触发登录获取cookie放入配置中心,定时更换。 2.若需要连续请求,依次模拟请求,并将获取的cookie在后续请求中使用。 3.无头浏览器、app破解。 |
| socket层协议 | 有些APP不通过常用的http、https协议,而是socket连接来传输二进制数据。 | 1.通过app破解,在app内部将数据截获。 |
| 数据图片 | 数据以图片的方式进行展示 | 1.OCR识别。 2.机器学习。 |
| 验证码 | 通常登录时需要输入验证码, 被封禁时也时常弹出验证码, 分为字符验证码、动作验证码,动作验证码即拖动验证、点击验证。 |
1.字符验证码:卷积神经网络、OCR识别、打码平台。 2.动作验证码:app自动化测试工具、浏览器自动化测试工具。 |
| 数据加密 | 1.分析解密… 2.尝试绕过如app破解、无头浏览器。 |
|
| 行为特征 | 如果用户只请求一个页面,或者有规律的请求,明显不是正常用户。 | 1.尽量随机化操作、随机时间、模拟人类真实操作。 |
| 蜜罐 | 设置一些用户触及不到的网页,等着爬虫去爬,爬到了就属于非正常用户。 | 没有好的解决方法。。。。。。 |
| 投毒 | 即假数据 | 结合上面的反反爬虫策略,尝试不被对方发现。 |
ps 本文未经本人同意,不可转载。 by chasexie
以上操作均为测试,未