Oracle 一 sqlplus环境与基本查询
目录
1.sqlplus命令(工具命令,非sql语句)
1.1 登陆
切换用户:
断开连接
1.2录屏
1.3清屏
1.4当前用户
1.5 显示表结构
1.6设置行宽
1.7 设置列宽
类似的可以设置页大小:
1.8 pagesize页行数
1.9 newpage
1.10 pause
1.11 numformat变量
1.12修改写错的sql语句
2.常用SQL*Plus命令
2.1help命令
2.2 describe命令
2.3其他命令
1.define定义变量
2.show命令
3.ed[it]命令 见前面修改命令
4.save命令
5.get命令
6.start和@命令
2.4格式化查询结果
2.4.1 column命令
1.format 格式化指定的列
2.heading定义列标题
3.null
4. ON|OFF
5.wrapped/word_wrapped
6.ttitle|btitle
7.交互式输入
3.sql基本查询语句 和mysql基本一样 不再赘述
1.sqlplus命令(工具命令,非sql语句)
1.1 登陆
sqlplus scott/tiger如果建立过除orcl以外的数据库(如用dbca建立了YGGL),然后又删了改数据库,默认连接的会是新数据库,此时必须显式指定连接哪个数据库 @数据库名即可 (本质上似乎是连接串名,和数据名相同罢了)
sqlplus scott/tiger@orcl
切换用户:
conn 用户名/密码 [as sysdba]
conn sys/orcl as sysdba;
同理有时要显式指定连接的数据库:
conn sys/orcl@orcl as sysdba;

断开连接
--以下两种写法都行 disconn disconnect
退出sqlplus
exit

1.2录屏
spool G:\基本查询.txt
。。。。。
spool off将spool G:\基本查询下一句至spool off的所有cmd窗口内容写到文件“G:\基本查询.txt”里,相当于录屏
1.3清屏
host cls其实host 后面接该操作系统的各种命令都行,host就是执行主机命令 如:host dir host date
1.4当前用户
oracle下一个数据库有多个用户,用户下才有表
show user当前用户下的表和视图:
select * from tab;当前用户下的表
select table_name from user_tables;
-- user_tables是一张特殊的表 可以查询该表结构
desc user_tables;1.5 显示表结构
desc 表名;
desc emp;1.6设置行宽(cmd窗口一行能显示的字符数)
缺省80个字符
show linesize; --显示行宽
set linesize 150; --设置行宽为150未设置行宽前:
设置行宽后:
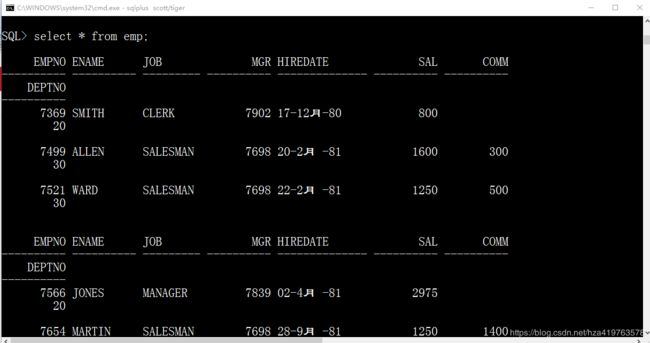
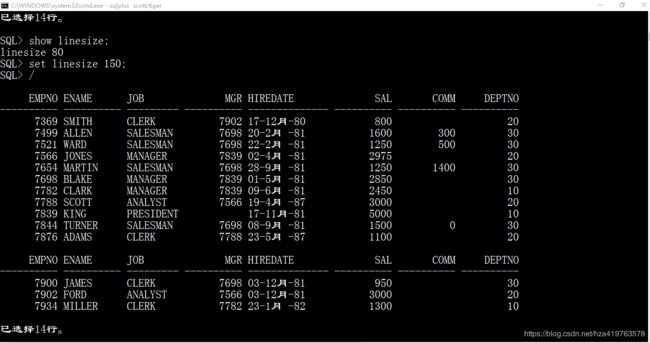
/ 表示执行上一条sql语句
1.7 设置列宽(表的单个列所占的字符宽度 设置的宽度不够还是会原样输出)
--设置ename(字符型)列占8个字符
col ename format a8
--设置sal(数字型)占4位 1个9代表一个数字
col sal format 9999
--format可以直接写for 如下
col ename for a8
col sal for 9999类似的可以设置页大小:
show pagesize;
set pagesize 30;
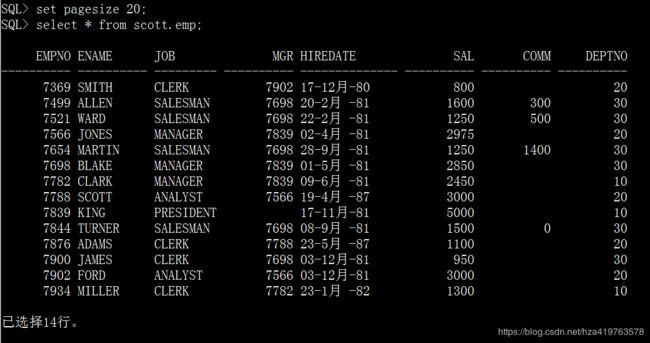
--省得每次分页多输出一行----------------------------------------------------和列名1.8 pagesize页行数
顶部分页至页结束之间的行数
一个分页就有一个标题头,如下框出了两个分页
默认情况下sql缓冲区显示页的行数是24,其中22行显示数据,2行显示标题和横线,我们可以将pagesize设置大些以减少提示标题和横线
show pagesize; select * from scott.emp;
set pagesize 20; select * from scott.emp;
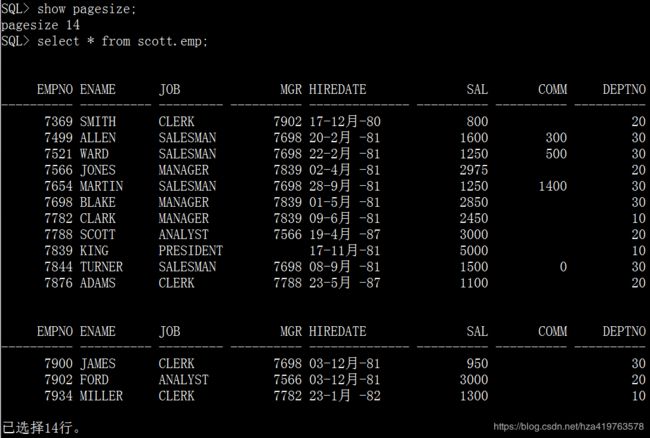
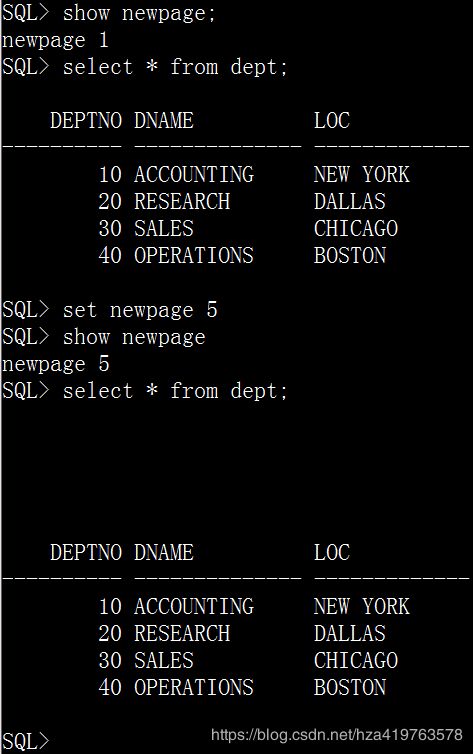
1.9 newpage
设置一页中空行的数量
set newpage value
value默认值为1set newpage 5 select * from dept;
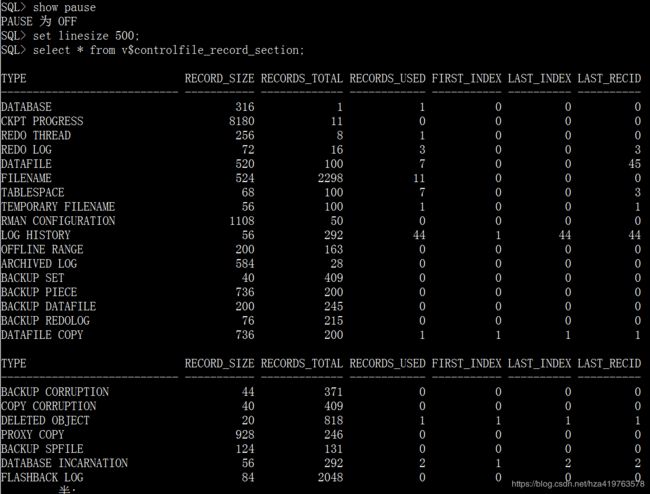
1.10 pause
设置输出结果是否滚动显示,也即select语句后是否
需要按一次enter显示一页,而不是一次显示完所有默认OFF
--未设置前 show pause set linesize 500; select * from v$controlfile_record_section;
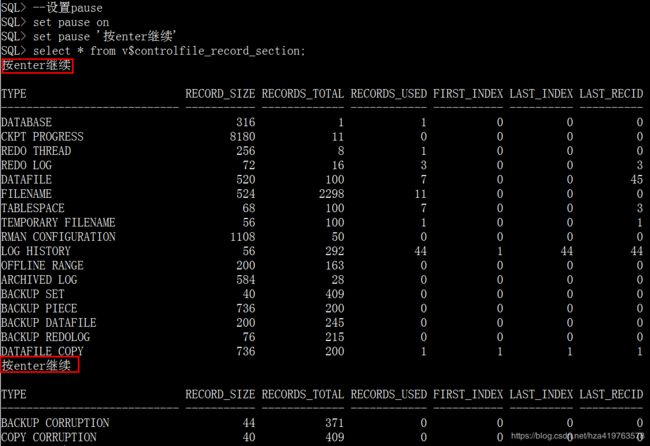
设置pause 此命令可以结合set pagesize 命令一起使用
--设置pause set pause on set pause '按enter继续' select * from v$controlfile_record_section;
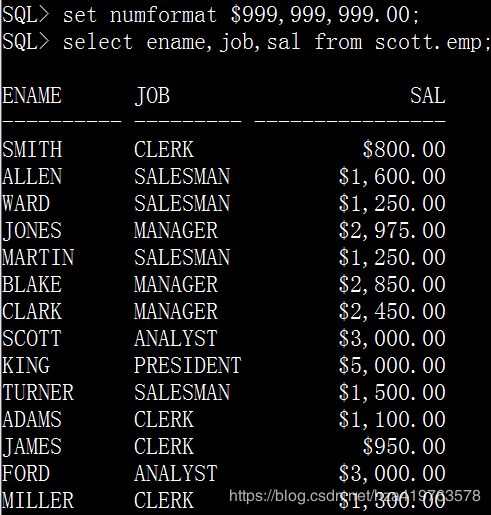
1.11 numformat变量
设置显示数值的缺省格式
set numformat format;
format为数值掩码:
999
999.00
$999
S999
999,99(注意,此参数比较坑,一改全改,即所有的数字都会以指定的格式显示,不管是金额还是编号,慎用)
默认:
select ename,job,sal from scott.emp;
s
设置默认数值格式
set numformat $999,999,999.00; select ename,job,sal from scott.emp;
1.12修改写错的sql语句
--edit 会将上一条语句写入记事本供你修改 改完后直接×掉1
ed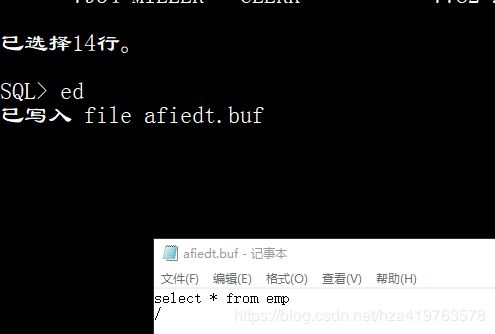
2.常用SQL*Plus命令
2.1help命令
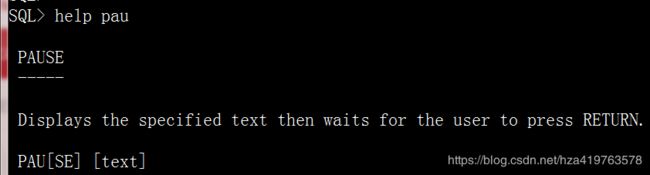
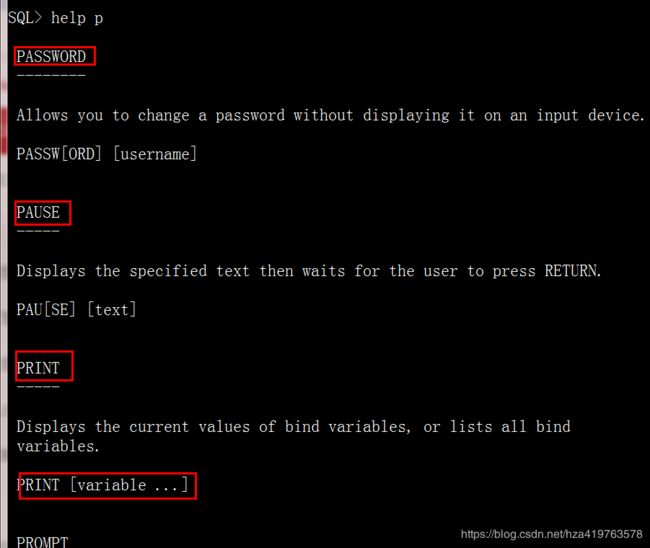
help 部分命令字符 --模糊查询命令格式 eg:help pau help p --打印所有p开头的命令格式
help 命令全名 --查询该命令格式 eg:help pause
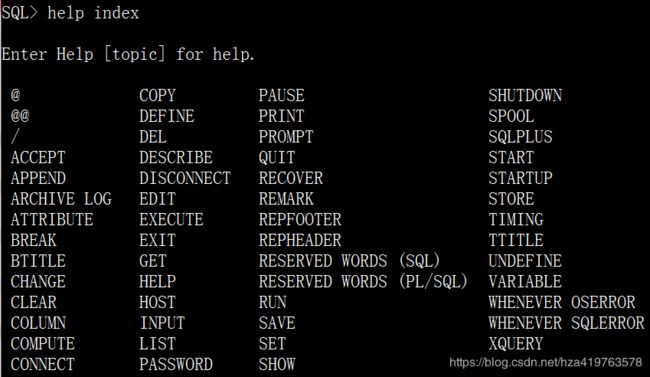
help index --查询sql*plus命令清单 eg:help index
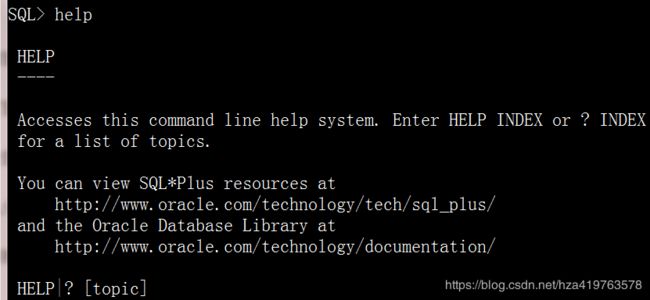
help --输出help本身的命令格式 eg:help
无意中发现password命令,可以很轻易修改当前用户密码,管理员可以修改任何用户密码
password 修改当前用户密码
password scott; --管理员身份下可以修改任意用户密码 如修改scott用户密码
2.2 describe命令
查询指定对象的组成结构
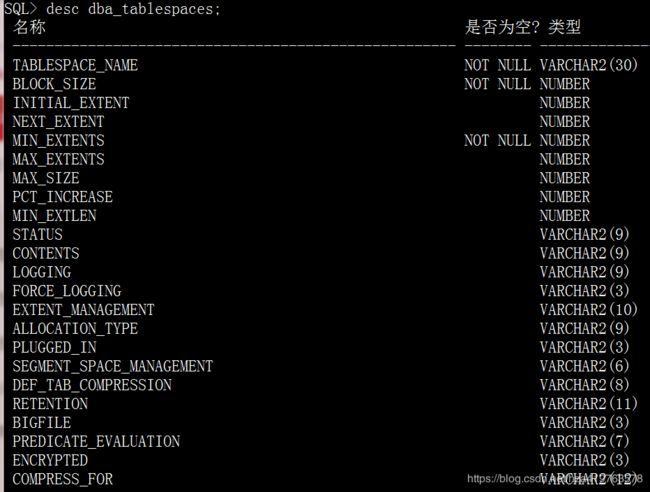
1.查询数据字典表的结构
desc dba_tablespaces;
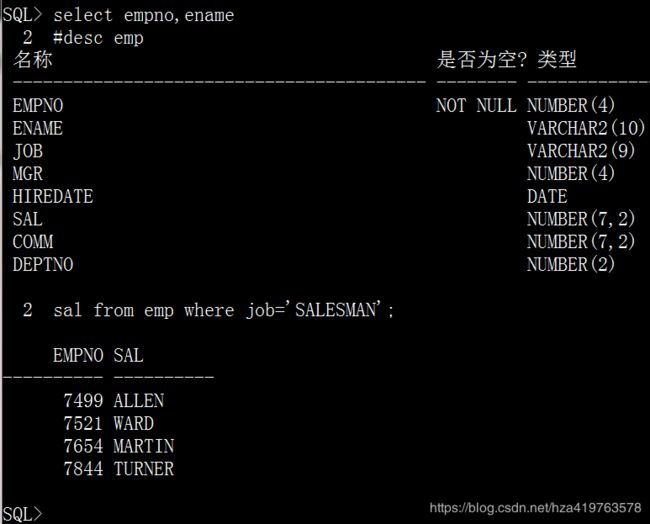
2.查询scott.emp表中销售员salesman的编号、姓名和工资(查询过程中忘了某列的名字咋办?#desc 表名临时查询)
select empno,ename #desc emp sal from emp where job='SALESMAN';
2.3其他命令
1.define定义变量
define var='SALESMAN';--定义变量var 且赋值'SALESMAN'
define var; --输出变量vardefine var='SALESMAN'; define var;
&变量名 可以在sql语句内应用变量的值
define var='SALESMAN'; select * from emp where job='&var';
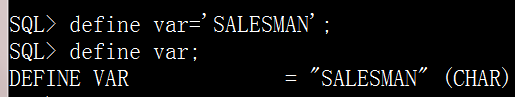

2.show命令
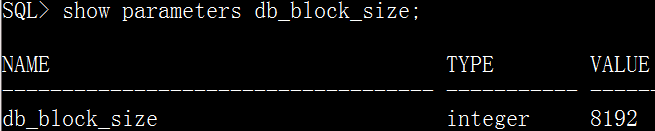
显示sql*plus系统变量或者环境变量的值
sho[w] option
option是要显示的系统选项,常用的有all,parameters[parameter_name]、sga、spool、user等
查询当前数据库实例的数据块大小
show parameters db_block_size;
3.ed[it]命令 见前面修改命令
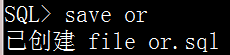
4.save命令
将sql缓冲区中的最近一条sql语句或pl/sql块保存到一个文件中,其语法格式如下。
save file_name
不写后缀名,默认后缀名为.sql 不写目录,默认存到当前用户主目录下
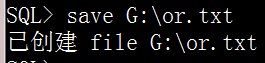
select * from scott.emp; save or
可以指定后缀名
save G:\or.txt
5.get命令
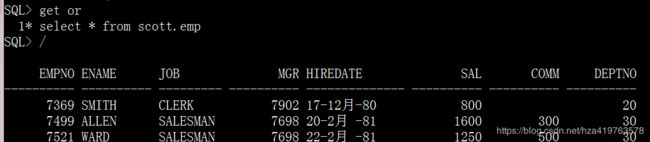
把一个sql脚本文件的内容放进sql缓冲区
get [file] file_name[.ext] [list|nolist]
filename:要检索的文件名,省略拓展名,则默认为.sql
list:指定文件的内容加载到缓冲区时显示文件的内容
nolist:指定文件的内容加载到缓冲区时不显示文件的内容
不写后缀名则默认为.sql,不写路径,则默认为当前用户主目录 get命令不会立即执行,只是放到了缓冲区,想要执行还要/
get or /
get G:\or.txt /
6.start和@命令
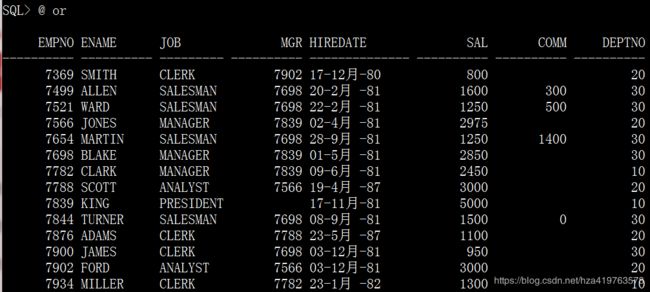
执行一个sql脚本文件
基本和get相同,但是这两个命令不用加/,直接就可以执行脚本内容
一下3条语句执行结果相同
@or @ or start or
2.4格式化查询结果
2.4.1 column命令
col [column_name|alias|option]
column_name:用于指定要设置的列的名称
alias:用于指定列的别名,通过它可以把英文标题设置为汉字
option:用于指定某个列的显示格式
下面就具体option选项一一列举
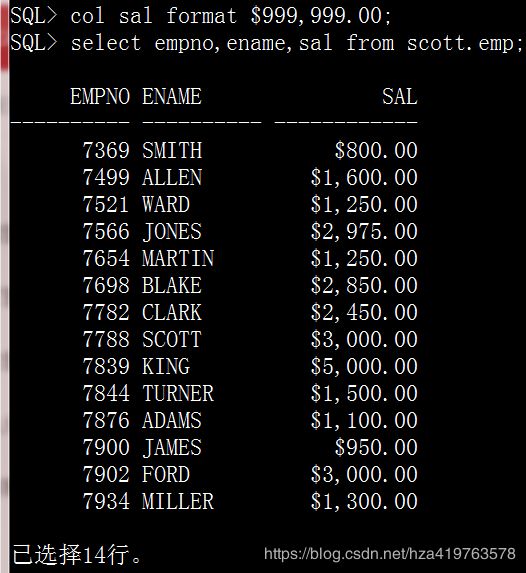
1.format 格式化指定的列
替代命令set numformat $999,999,999.00;
col sal format $999,999.00; select empno,ename,sal from scott.emp;
2.heading定义列标题
类似select语句取别名
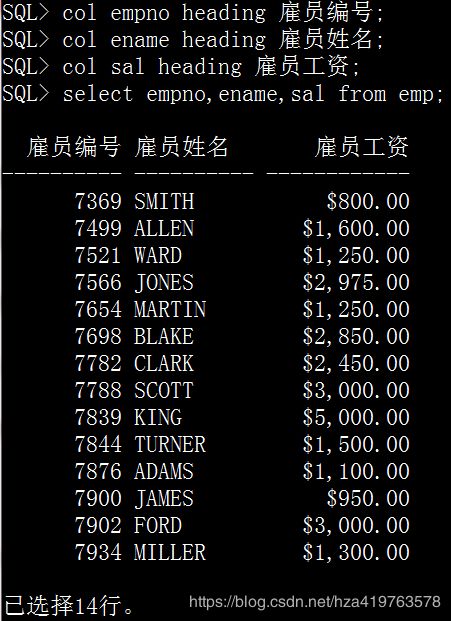
col empno heading 雇员编号; col ename heading 雇员姓名; col sal heading 雇员工资; select empno,ename,sal from emp;
3.null
col 列名 null '字符串' --若列值为null 则显示null后的字符串值
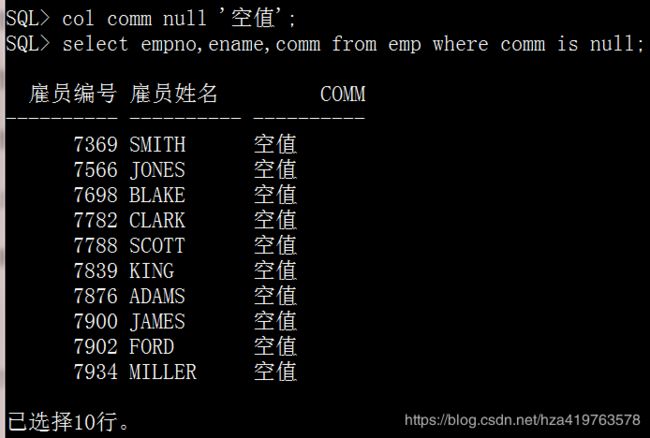
col comm null '空值'; select empno,ename,comm from emp where comm is null;
4. ON|OFF
col sal off; -- 所有对sal列定义的显示属性都不起作用
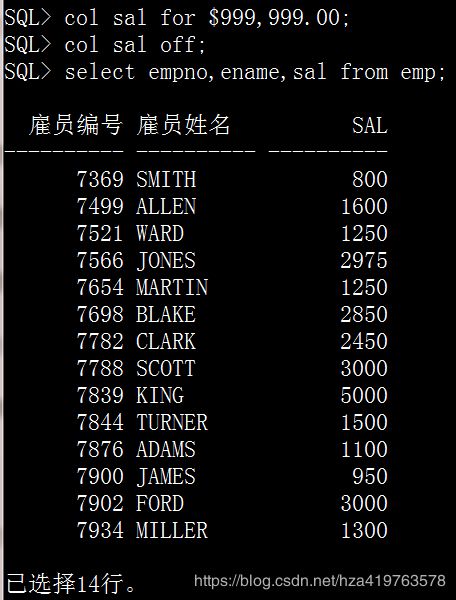
col sal for $999,999.00; col sal off; select empno,ename,sal from emp;
5.wrapped/word_wrapped
两个选项都用来折行,wrapped按照指定长度折行。word_wrapped按照完整字符串折行
准备工作:
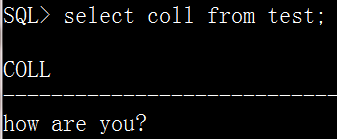
create table test( coll varchar2(50) ); insert into test values('how are you?');select coll from test;
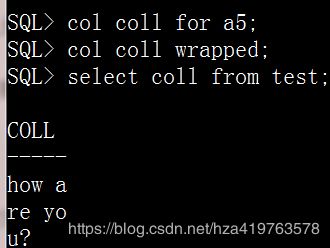
eg:每行显示5个来折行
col coll for a5; col coll wrapped; select coll from test;
按照完整字符串折行,比较好
col coll word_wrapped /

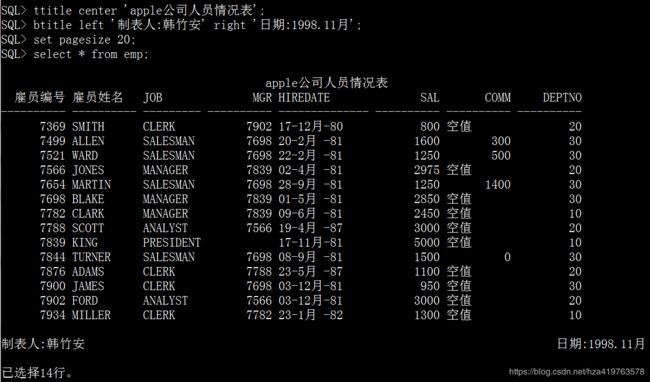
6.ttitle|btitle
ttitle [center|left|right]string 顶部标题
btitle [center|left|right]string 底部标题
ttitle center 'apple公司人员情况表'; btitle left '制表人:韩竹安' right '日期:1998.11月'; set pagesize 20; select * from emp;
ttitle off | btitle off 就是关闭表名称的打印,否则后面所有的查询结果都将打印同样的表标题
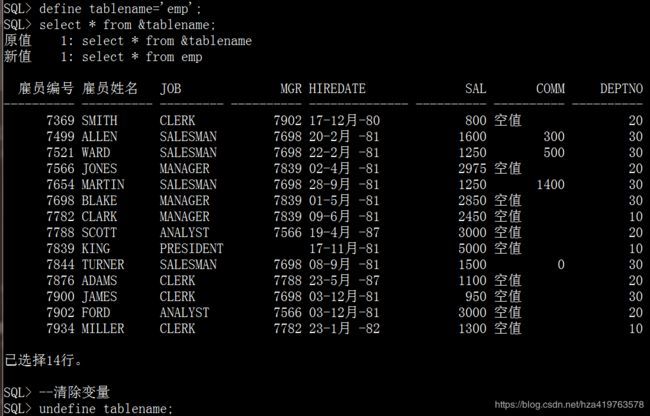
7.交互式输入
define tablename='emp'; select * from &tablename; --等价于select * from emp;
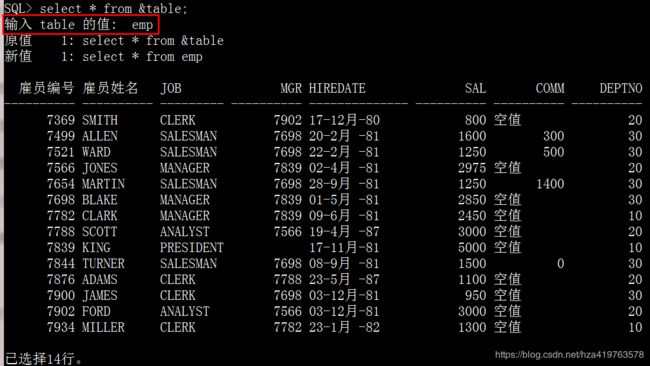
动态输入参数值:
select * from &table; emp
以下无关:
3.sql基本查询语句 和mysql基本一样 不再赘述
--查询所有的员工信息
select * from emp;
--通过列名查询
select empno,ename,job,mgr,hiredate,sal,comm,deptno
from emp;
/*
SQL优化的原则:
1.尽量使用列名
*/
--查询员工信息:员工号 姓名 月薪
select empno,ename,sal
from emp;
--查询员工信息:员工号 姓名 月薪 年薪
select empno,ename,sal,sal*12
from emp;
--查询员工信息:员工号 姓名 月薪 年薪 奖金 年收入
select empno,ename,sal,sal*12,comm,sal*12+comm
from emp;
--上面写法有问题 comm为null的年收入也算为null了
/*
SQL中的null值:
1. 包含null的表达式都为null
2. null永远!=null
*/
select empno,ename,sal,sal*12,comm,sal*12+nvl(comm,0)
from emp;
-- nvl(comm,0) 若comm奖金为null返回0,否则返回comm
--2. null永远!=null
--查询奖金为null的员工
-- 错误写法
select *
from emp
where comm=null;
-- 正确写法
select *
from emp
where comm is null;
--distinct 去掉重复记录
select deptno from emp;
select distinct deptno from emp;
select job from emp;
select distinct job from emp;
--distinct 作用于后面所有的列
select distinct deptno,job from emp;
--连接符 ||
-- concat
select concat('Hello',' World') from emp;
--虚表 dual
select concat('Hello',' World') from dual;
select 3+2 from dual;
--dual表:伪表
--伪列
select 'Hello'||' World' 字符串 from dual;
输出:
字符串
------------
Hello World
--查询员工信息:***的薪水是****
select ename||'的薪水是'||sal 信息 from emp;
运行结果:
信息
----------------------------------------------------------
SMITH的薪水是800
ALLEN的薪水是1600
WARD的薪水是1250
JONES的薪水是2975
MARTIN的薪水是1250
BLAKE的薪水是2850
--字符串
spool off