【超越CycleGAN】这个人体动态迁移技术让白痴变舞王(视频)

IT派 - {技术青年圈}
持续关注互联网、区块链、人工智能领域


【导读】伯克利的研究人员提出了一种简单的“动作迁移法”,可以将源视频中一个人的动作和姿态,迁移到新的视频对象上,让后者也具有同样流畅优美的动作,整个过程只需要几分钟就成完成。论文地址:https://arxiv.org/pdf/1808.07371.pdf
说起去年让“马变斑马”的CycleGAN,大家应该还记忆犹新。

CycleGAN利用pixel2pixel技术,能自动将某一类图片转换成另外一类图片,过度真实自然,可以说是2017年最受关注的模型之一。CycleGAN论文的第一作者、加州大学伯克利分校的朱俊彦(现已在MIT CSAIL担任博士后),也由此获得了SIGGRAPH 2018的杰出博士论文奖。
现在,同样是伯克利的Caroline Chan、ShiryH Ginosar、Tinghui Zhou、Alexel A. Efros提出了或许更有意思的一篇论文,不仅是图像,而是实现不同视频之间的人物动作姿态转换,而且面部也能逼真合成效果,整个过程只需要几分钟就能完成。
将专业舞者的动作迁移到其他人身上,让每个人都能成为顶级舞者
作者在论文摘要中这样介绍:
本文提出一种简单的 “跟我做”(do as I do)的动作迁移方法:给定一个人跳舞的源视频,我们可以在目标人物表演标准动作几分钟后将该表演迁移到一个新的目标身上(业余舞者)。
我们将这个问题视为一个具有时空平滑的每帧 image-to-image 转换问题。利用姿势检测作为原和目标之间的中间表示,我们学习了从姿势图像到目标对象外观的映射。
我们利用这样的设置实现了连贯时间的视频生成,并且包括逼真的面部合成。
伯克利研究者提出了一种在不同视频中转移人体动作的方法。
他们要实现的目的很简单——给定两个视频:一个是目标人物,我们想合成他的表演;另一个是源视频,我们想将他的动作转移到目标人物身上。
这与过去使用最近邻搜索或 3D 重定向运动的方法不同。在伯克利研究人员提出的框架下,他们制作了各种各样的视频,让业余舞蹈爱好者能够像芭蕾舞演员一样旋转、跳跃,表演武术,跳舞。

最初,为了逐帧地在两个视频的主体之间迁移运动,研究人员认为他们必须学习两个人的图像之间的映射。因此,目标是在源集和目标集之间发现图像到图像的翻译(image-to-image translation)。
但是,他们并没有用两个实验对象对应的相同动作来直接监督学习这种翻译。即使两个实验对象都做同样的动作,由于每个实验对象的体型和风格差异,仍然不太可能有帧到帧的 body-pose 对应的精确框架。
于是,他们观察了基于人体姿态关键点(keypoint),关键点本质上是编码身体的位置而不是外观,可以作为任何两个主体之间的中间表示。而姿势可以随着时间的推移保持动作特征,同时尽可能地抽象出对象身份标识。因此,我们将中间的表示设计为火柴人自试图,如下图所示。
将源视频中人物(左上)动态的姿态关键点(左下)作为转化,迁移到目标视频人物(右)。
从目标视频中,我们得到每一帧的姿势检测,得到一组(姿势火柴人,目标人物形象)的对应数据。有了这些对齐的数据,我们就可以在有监督的情况下,学习一种在火柴人和目标人物图像之间的 image-to-image 的转换模型。
因此,模型经过训练,可以生成特定目标对象的个性化视频。然后,将动作从源迁移到目标,将姿势火柴人图形输入到训练模型中,得到与源姿势相同的目标对象的图像。
为了提高结果的质量,研究人员还添加了两个组件:
为了提高生成的视频的时间平滑度,我们在每一帧都将预测设置在前一帧的时间步长上。
为了在结果中增加人脸的真实感,我们加入了一个专门训练来生成目标人物面部的 GAN。
这种方法生成的视频,可以在各种视频主体之间迁移运动,而无需昂贵的 3D 或动作捕捉数据。
作者在论文中写道:“我们的主要贡献是一个基于学习的视频之间人体运动迁移的 pineline,所得结果的质量展示了现实的详细视频中的复杂运动迁移。”
首先,我们需要准备两种视频素材:
一个是你理想舞者表演的视频:
一个是你自己随性 “凹” 出的动作视频:
最终的目标,就是让你能够跳出梦寐以求的曼妙舞姿:
为了实现这一目标,可以将 pipeline 分为三个阶段:
1、姿势检测:根据源视频中给定的帧,使用预训练好的姿势检测器来制作姿势线条图;
2、全局姿势归一化:该阶段考虑了源视频与目标视频中人物身形的不同,以及在各自视频中位置的差异;
3、将归一化的姿势线条图与目标人物进行映射:该阶段通过对抗性学习设计了一个系统,来将归一化的姿势线条图与目标人物进行映射。
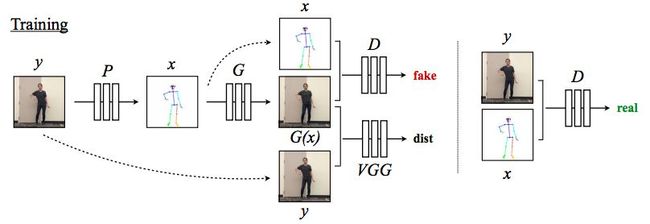
完整的训练过程
模型根据源视频中给定的帧,使用预训练好的姿势检测器 P 来制作姿势线条图。在训练期间,学习了一种映射 G 和一个对抗性鉴别器 D,来试图区分哪些匹配是真,哪些是假。

完整的转换过程
模型使用一个姿势检测器 P : Y′ → X′来获取源视频中人物的姿势关节,这些关节通过归一化,转换为姿势条形图中目标人物的关节。而后,我们使用训练好的映射 G。
好了,现在“炫酷舞姿”的问题解决了,剩下的就是将目标视频中因为动作改变而随之模糊的脸部变得更加逼真而清晰。
为了实现这一点,研究人员将 pix2pixHD 的对抗性训练设置修改为:
(1) 产生时间相干视频帧;
(2) 合成逼真的人脸图像。
接下来将详细描述原始目标和对它的修改。
pix2pixHD 框架
方法是基于 pix2pixHD 中的目标提出来的。在初始条件 GAN 设置中,生成器网络 G 对多尺度鉴别器 D = (D1,D2,D3) 进行极大极小博弈。
其中,![]() 是对抗性损失:
是对抗性损失:
![]()
让动作更加连贯
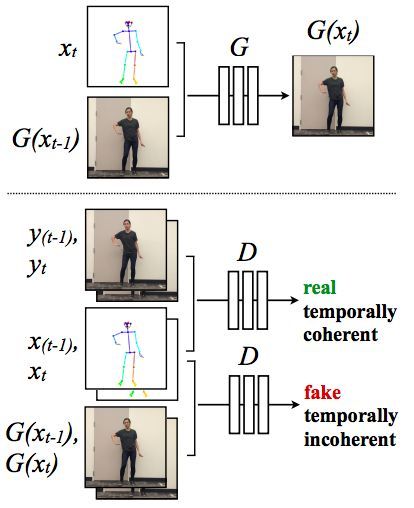
时间平滑(Temporal Smoothing)设置
Face GAN
我们添加了一个专门的 GAN 设置,用于为面部区域添加更多细节和真实感,如下图所示。
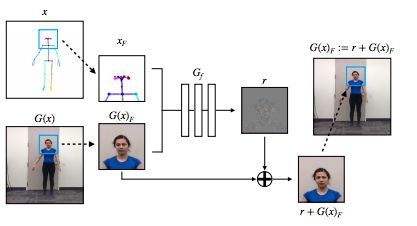
Face GAN 设置
在 Face GAN 中,通过生成器![]() 预测残差,并将其添加到来自主生成器的原始面部预测中。
预测残差,并将其添加到来自主生成器的原始面部预测中。
我们探讨了对 pix2pixHD baseline 的修改效果,并根据收集的数据集评估结果的质量。
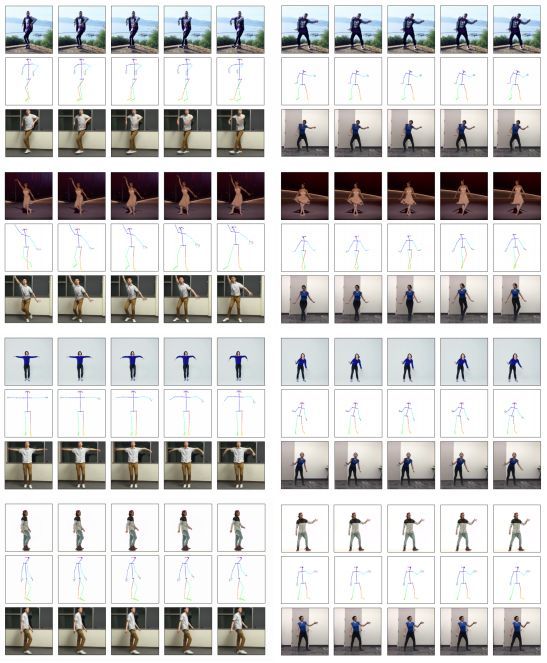
迁移的结果。每个部分显示 5 个连续的帧。上面一行显示 source subject,中间一行显示规范化的 pose stick figures,下面一行显示目标人物的模型输出。

不同模型合成结果的比较
总的来说,新的这个动作迁移模型能够创建合理的、将任意长度的目标人物跳舞的视频,其中他们的舞姿跟随另一个跳舞者的输入视频。虽然我们的设置在很多情况下都可以产生可信的结果,但偶尔会遇到几个问题。
从根本上说,作为输入的 pose stick figures 依赖于噪声姿态估计,这些估计不会逐帧携带时间信息。在姿势检测中丢失关键点,关键点位置不正确,会将错误引入到输入中,并且这些失败通常会延续到结果中,虽然我们尝试了通过时间平滑设置来减轻这些限制。但即使我们试图在设置中注入时间连贯性(temporal coherence),以及预平滑关键点,结果经常仍然会受到抖动的影响。
虽然我们的全局姿势归一化方法合理地调整了任何源对象的运动,使其与训练中看到的目标人物的体型和位置相匹配,但这种简单缩放和平移解决方案并未考虑不同的肢长和摄像机位置或角度。这些差异也会导致在训练和测试时看到的运动之间存在更大的差距。
另外,2D 坐标和缺失检测限制了在对象之间重新定位运动的方式,这些方法通常在 3D 中工作,需要有完美的关节位置和时间连贯运动。
为了解决这些问题,需要在时间上连贯的视频生成和人体运动表示方面做更多的工作。虽然整体上 pose stick figures 产生了令人信服的结果,但我们希望在未来的工作中,通过使用为运动迁移特别优化的时间连贯输入和表示来避免它所带来的限制。
尽管存在这些挑战,但我们的方法能够在给出各种输入的情况下制作吸引人的视频。
难度被誉为最高的芭蕾舞黑天鹅48圈转,可以换上自己的脸,想想还是有些小激动呢。
论文地址:https://arxiv.org/pdf/1808.07371.pdf
∞∞∞∞∞

公众号回复“IT派”,
邀你加入IT派 { 技术青年圈}