分布式机器学习平台大比拼
本文选自纽约州里大学计算机系教授Murat和学生的论文,主要介绍了分布式机器学习平台的实现方法并提出了未来的研究方向。
论文>>https://www.cse.buffalo.edu/~demirbas/publications/DistMLplat.pdf
机器学习特别是深度学习为语音识别、图像识别、自然语言处理、推荐系统和搜索引擎等领域带来的革命性的突破。这些技术将会广泛用于自动驾驶、医疗健康系统、客户关系管理、广告、物联网等场景。在资本的驱动下机器学习的发展十分迅速,近年来我们看到了各个公司和研究机构纷纷推出了自己的机器学习平台。
由于需要训练的数据集合模型十分巨大,机器学习平台通常采用分布式的架构来实现,会采用成百上千的机器来训练模型。在不远的未来,涉及机器学习的计算将会成为数据中心的主要任务。
由于作者分布式系统的专业背景,本文从分布式系统的角度来研究这些机器学习平台,并分析他们在通信和控制方面的瓶颈。同时我们还研究并比较了这些平台的容错性以及编程实现的难易程度。
根据实现原理和架构的不同,我们将分布式机器学习平台分为三种不同的基本类型:
-
基础数据流模式
-
参数服务器模型
-
先进的数据流模式
对于三种主流的实现方式做了简短的介绍,分别利用Spark、PMLS和Tensorflow(MXNet)来对三种类型进行解读。我们对不同的平台进行了比较,详细的结果见论文。
在文章的最后我们总结了分布式机器学习平台并对未来给出了一些建议,如果你很熟悉机分布式器学习平台的话可以跳过这部分。
Spark
在Spark里计算通过有向无环图来建模,其中每一个顶点代表一个弹性分布式数据集(Resilient Distributed Dataset, RDD) ,而每条边表示一种对于RDD的操作。RDD是一组分配在不同逻辑分区里的对象,这些逻辑分区直接在内存里储存并处理,当内存空间不够的时候,部分分区会被存放在硬盘上,需要的时候再和内存里的分区替换位置。
在有向无环图中,从A定点指向B定点的E边表示RDD A 通过E操作得到了RDD B。其中包含两类操作:转换类和动作类。转换类操作意味着会产生新的RDD。
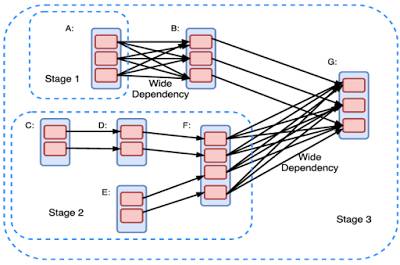
Spark的用户通过建立对有向无环图上RDD的转换或者运行操作来实现计算。有向无环图被编译为一个个不同的级别,每一个级别包含一系列可以并行计算的任务(每个分区中一个任务)。任务间较弱的依赖性有利于高效的执行,而较强的依赖性则会因为大量的通信造成性能的严重下降。

Spark通过将这些有向无环图分级分配到不同的机器上来实现分布式计算,上图显示了主节点的清晰的工作架构。驱动包含两个部分的调度器单元,DAG调度器和任务调度器,同时运行和协调不同机器间的工作。
Spark的设计初衷是用于通用的数据处理,并没有针对机器学习的特殊设计。但是在MKlib工具包的帮助下,也能在Spark上实现机器学习。通常来说,Spark将模型参数存储于驱动节点上,每一个机器在完成迭代之后都会与驱动节点通信更新参数。对于大规模的应用来说,模型参数可能会存在一个RDD上。由于每次迭代后都会引入新的RDD来存储和更新参数,这会引入很多额外的负载。更新模型将会在机器和磁盘上引入数据的洗牌操作,这限制了Spark的大规模应用。这是基础数据流模型的缺陷,Spark对于机器学习的迭代操作并没有很好的支持。
PMLS
PMLS是为机器学习量身打造的平台,通过引入了参数服务器抽象概念来处理机器学习训练过程中频繁的迭代。
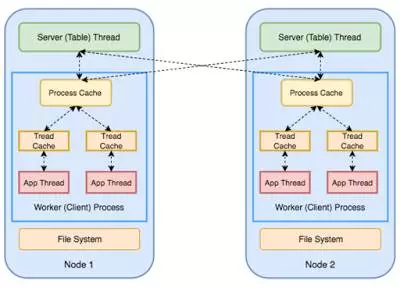
上图中的绿色框表示系统的参数服务器,并保存为分布式的键值存储。PS包含两个方面的任务——复制和分片:每一个节点都是模型的一个分片的主要节点,其次,这个节点还是有别的分片的备份。因此,参数服务器的性能和节点数量是持正比的。
PS节点存储并且更新模型的参数,同时对机器的请求作出相应。每台机器会将自己本地PS的参数模型更新到PS节点,同时获取分配到需要进行计算的数据集。
PMLS 同时采用了Stale Synchronous Parallelism (SSP) 模型,相比于Bulk Synchronous Parellelism (BSP) 模型它放宽了每一个机器在每一次迭代结束时同步的要求。S由于处理过程在误差允许的范围内,这样松弛的连续模型对于机器学习依然有效。我曾经发表了一篇博客验证了这一机制。
博客>>https://muratbuffalo.blogspot.com/2016/04/petuum-new-platform-for-distributed.html
TensorFlow
谷歌有过一个基于参数服务器的分布式机器学习模型——DistBelief,但它最大的劣势在于需要很多底层的编程来实现机器学习。谷歌希望员工可以在不需要精通分布式知识的情况下编写机器学习代码,所以开发了Tensorflow来实现这一目标。基于同样的理由,谷歌也曾经为大数据处理提供了MapReduce的分布式框架。
Tensorflow虽然采用了数据流机制,但采用了更先进的计算图模型。我认为Naiad的设计对TensorFlow产生了很大的影响。
Tensorflow利用有向图的节点和边实现计算。节点代表需要实现的计算而边则代表在节点间进行通信的高维矩阵(张量)用户需要静态地申明符号化的计算图,同时利用图的复写和分区来实现分布式计算(MXNet和部分的DyNet则会动态地申明图来改善程序的灵活性)。
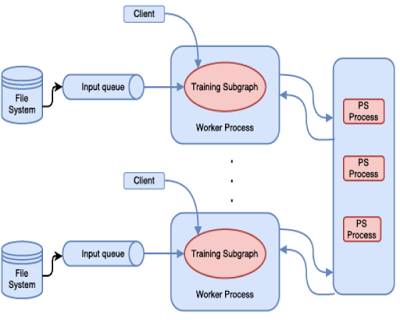
TensorFlow通过使用上图中的参数服务器来实现对模型的训练。当你在TensorFlow中使用参数服务器抽象概念时,你同时可以使用参数服务器和数据并行。Tensorflow可以实现更为复杂的操作,但是需要用户自己编写程序去探索和实现。
一些评测结果
我们使用亚马逊的云服务来进行试验,利用了Amazon EC2 m4.xlarge 实例 每个包含 Intel Xeon E5-2676 v3 处理器 and 16GiB RAM. 750Mbps的带宽. 我们利用二分类逻辑回归和多层神经网络的图像分类问题来进行评价。下文只是简要的列出了实验结果的图表,欲知详情请查阅论文。我们的试验受限于机器规模的限制,同时我们仅仅测试了三种分布式平台在CPU上的表现,并没有测GPU的。
下图描述了各个平台进行逻辑回归的速度,Spark

下图显示了各个平台对于DNNs的处理速度。其中Spark在处理两层网络时的性能下降主要来自于大量的迭代计算。

下图是不同平台对于CPU的利用率。Spark的使用率最高,主要来自于大量的串联负载。我们先前的工作对这一问题进行过讨论。
https://muratbuffalo.blogspot.com/2017/05/paper-summary-making-sense-of.html

结论与展望
现在的ML/DL 应用基本都是平行运算,而且从算法角度看不是很有趣。我们可以很有把握的说参数服务器在分布式机器学习平台上是更好的方案。
目前网络通信还是分布式机器学习系统的瓶颈。与其致力于更先进的通用数据流平台,不吐集中精力来实现更好的数据/模型分级,提高数据/模型的重视度。
在Spark系统中CPU的开销则是先于网络限制的瓶颈。编程语言的性能同样的影响着系统的表现。十分需要更高的工具来监测并且预测分布式机器学习系统的表现,最近出现了如Ernest和CherryPick等工具来处理这一问题。
对于机器学习的运行时间依然存在许多悬而未决的问题,例如资源调度和运行时间表现的改善。通过对应用运行时间的监控和分析,下一代分布式机器学习系统将会运行时间的弹性预测以及对于计算资源、内存、网站资源的弹性调度。同时编程和软件工程方面也存在一些需要解决的问题。什么是适合分布式机器学习抽象编程语言?这还需要研究人员进行大量的验证和测试来回答。
摘自:微信公众号:将门创投(thejiangmen)
原文链接:http://t.cn/R96Izk8