CIFAR-10数据集
一、CIFAR-10
CIFAR-10数据集由10类32x32的彩色图片组成,一共包含60000张图片,每一类包含6000图片。其中50000张图片作为训练集,10000张图片作为测试集。
CIFAR-10数据集被划分成了5个训练的batch和1个测试的batch,每个batch均包含10000张图片。测试集batch的图片是从每个类别中随机挑选的1000张图片组成的,训练集batch以随机的顺序包含剩下的50000张图片。不过一些训练集batch可能出现包含某一类图片比其他类的图片数量多的情况。训练集batch包含来自每一类的5000张图片,一共50000张训练图片。
下图显示的是数据集的类,以及每一类中随机挑选的10张图片:

二、CIFAR-10数据集解析
官方给出了多个CIFAR-10数据集的版本,以下是链接:
Version Size md5sum
CIFAR-10 python version 163 MB c58f30108f718f92721af3b95e74349a
CIFAR-10 Matlab version 175 MB 70270af85842c9e89bb428ec9976c926
CIFAR-10 binary version (suitable for C programs) 162 MB c32a1d4ab5d03f1284b67883e8d87530
此处我们下载python版本。
下载完成后,解压,得到如下目录结构的文件夹:
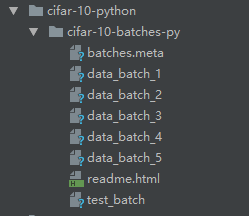
其中:
| 名称 | 作用 |
|---|---|
| batches.meta | 程序中不需要使用该文件 |
| data_batch_1 | 训练集的第一个batch,含有10000张图片 |
| data_batch_2 | 训练集的第二个batch,含有10000张图片 |
| data_batch_3 | 训练集的第三个batch,含有10000张图片 |
| data_batch_4 | 训练集的第四个batch,含有10000张图片 |
| data_batch_5 | 训练集的第五个batch,含有10000张图片 |
| readme.html | 网页文件,程序中不需要使用该文件 |
| test_batch | 测试集的batch,含有10000张图片 |
上述文件结构中,每一个batch文件包含一个python的字典(dict)结构,结构如下:
| 名称 | 作用 |
|---|---|
| b’data’ | 是一个10000x3072的array,每一行的元素组成了一个32x32的3通道图片,共10000张 |
| b’labels’ | 一个长度为10000的list,对应包含data中每一张图片的label |
| b’batch_label’ | 这一份batch的名称 |
| b’filenames’ | 一个长度为10000的list,对应包含data中每一张图片的名称 |
真正重要的两个关键字是data和labels,剩下的两个并不是十分重要。
# -*- coding: utf-8 -*-
"""
Created on Wed Apr 11 14:51:27 2018
@author: Administrator
"""
'''
用于加载数据集合
数据集下载地址:http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
CIFAR-10数据集介绍:https://blog.csdn.net/davincil/article/details/78793067
一、CIFAR-10
CIFAR-10数据集由10类32x32的彩色图片组成,一共包含60000张图片,每一类包含6000图片。其中50000张图片作为训练集,10000张图片作为测试集。
CIFAR-10数据集被划分成了5个训练的batch和1个测试的batch,每个batch均包含10000张图片。
测试集batch的图片是从每个类别中随机挑选的1000张图片组成的,一共10000张测试图片,
训练集batch包含来自每一类的5000张图片,一共50000张训练图片。
训练集batch以随机的顺序包含剩下的50000张图片。
不过一些训练集batch可能出现包含某一类图片比其他类的图片数量多的情况。
'''
'''
文件下载之后,解压 主要包括以下文件
名称 作用
batches.meta 程序中不需要使用该文件
data_batch_1 训练集的第一个batch,含有10000张图片
data_batch_2 训练集的第二个batch,含有10000张图片
data_batch_3 训练集的第三个batch,含有10000张图片
data_batch_4 训练集的第四个batch,含有10000张图片
data_batch_5 训练集的第五个batch,含有10000张图片
readme.html 网页文件,程序中不需要使用该文件
test_batch 测试集的batch,含有10000张图片
上述文件结构中,每一个batch文件包含一个python的字典(dict)结构,结构如下:
名称 作用
b'data’ 是一个10000x3072的array,每一行的元素组成了一个32x32的3通道图片,共10000张
b'labels’ 一个长度为10000的list,对应包含data中每一张图片的label
b'batch_label' 这一份batch的名称
b'filenames' 一个长度为10000的list,对应包含data中每一张图片的名称
'''
import pickle
import numpy as np
import cv2
from skimage import io
class datagenerator(object):
def __init__(self):
pass
def unpickle(self,filename):
'''
batch文件中真正重要的两个关键字是data和labels
反序列化出对象
每一个batch文件包含一个python的字典(dict)结构,结构如下:
名称 作用
b'data’ 是一个10000x3072的array,每一行的元素组成了一个32x32的3通道图片,共10000张
b'labels’ 一个长度为10000的list,对应包含data中每一张图片的label
b'batch_label' 这一份batch的名称
b'filenames' 一个长度为10000的list,对应包含data中每一张图片的名称
'''
with open(filename,'rb') as f:
#默认把字节转换为ASCII编码 这里设置encoding='bytes'直接读取字节数据 因为里面含有图片像素数据 大小从0-255 不能解码为ascii编码,因此先转换成字节类型 后面针对不同项数据再解码,转换为字符串
dic = pickle.load(f,encoding='bytes')
return dic
def get_image(self,image):
'''
提取每个通道的数据,进行重新排列,最后返回一张32x32的3通道的图片
在字典结构中,每一张图片是以被展开的形式存储(即一张32x32的3通道图片被展开成了3072长度的list),
每一个数据的格式为uint8,前1024个数据表示红色通道,接下来的1024个数据表示绿色通道,最后的1024
个通道表示蓝色通道。
image:每一张图片的数据 数据按照R,G,B通道依次排列 长度为3072
'''
assert len(image) == 3072
#对list进行切片操作,然后reshape
r = image[:1024].reshape(32,32,1)
g = image[1024:2048].reshape(32,32,1)
b = image[2048:].reshape(32,32,1)
#numpy提供了numpy.concatenate((a1,a2,...), axis=0)函数。能够一次完成多个数组的拼接。其中a1,a2,...是数组类型的参数
#沿着某个轴拼接,默认为列方向(axis=0)
img = np.concatenate((r,g,b),-1)
return img
def get_data_by_keyword(self,keyword,filelist=[],normalized=False,size=(32,32),one_hot=False):
'''
按照给出的关键字提取batch中的数据(默认是训练集的所有数据)
args:
keyword:'data’ 或 'labels’ 或 'batch_label' 或 'filenames' 表示需要返回的项
filelist:list 表示要读取的文件集合
normalized:当keyword = 'data',表示是否需要归一化
size:当keyword = 'data',表示需要返回的图片的尺寸
one_hot:当keyword = 'labels'时,one_hot=Flase,返回实际标签 True时返回二值化后的标签
return:
keyword = 'data' 返回像素数据
keyword = 'labels' 返回标签数据
keyword = 'batch_label' 返回batch的名称
keyword = 'filenames' 返回图像文件名
'''
#keyword编码为字节
keyword = keyword.encode('ascii')
assert keyword in [b'data',b'labels',b'batch_label',b'filenames']
assert type(filelist) is list and len(filelist) != 0
assert type(normalized) is bool
assert type(size) is tuple or type(size) is list
ret = []
for i in range(len(filelist)):
#反序列化出对象
dic = self.unpickle(filelist[i])
if keyword == b'data':
#b'data’ 是一个10000x3072的array,每一行的元素组成了一个32x32的3通道图片,共10000张
#合并成一个数组
for item in dic[b'data']:
ret.append(item)
print('总长度:',len(ret))
elif keyword == b'labels':
#b'labels’ 一个长度为10000的list,对应包含data中每一张图片的label
#合并成一个数组
for item in dic[b'labels']:
ret.append(item)
elif keyword == b'batch_label':
#b'batch_label' 这一份batch的名称
#合并成一个数组
for item in dic[b'batch_label']:
ret.append(item.decode('ascii')) #把数据转换为ascii编码
else:
#b'filenames' 一个长度为10000的list,对应包含data中每一张图片的名称
#合并成一个数组
for item in dic[b'filenames']:
ret.append(item.decode('ascii')) #把数据转换为ascii编码
if keyword == b'data':
if normalized == False:
array = np.ndarray([len(ret),size[0],size[1],3],dtype = np.float32)
#遍历每一张图片数据
for i in range(len(ret)):
#图像进行缩放
array[i] = cv2.resize(self.get_image(ret[i]),size)
return array
else:
array = np.ndarray([len(ret),size[0],size[1],3],dtype = np.float32)
#遍历每一张图片数据
for i in range(len(ret)):
array[i] = cv2.resize(self.get_image(ret[i]),size)/255
return array
pass
elif keyword == b'labels':
#二值化标签
if one_hot == True:
#类别
depth = 10
m = np.zeros([len(ret),depth])
for i in range(len(ret)):
m[i][ret[i]] = 1
return m
pass
#其它keyword直接返回
return ret
import os
import pickle
def save_images():
'''
报CIFAR-10数据集图片提取出来保存下来
1.创建一个文件夹 CIFAR-10-data 包含两个子文件夹test,train
2.在文革子文件夹创建10个文件夹 文件名依次为0-9 对应10个类别
3.训练集数据生成bmp格式文件,存在对应类别的文件下
4.测试集数据生成bmp格式文件,存在对应类别的文件下
生成两个文件train_label.pkl,test_label.pkl 分别保存相应的图片文件路径以及对应的标签
'''
#根目录
root = 'CIFAR-10-data'
#如果存在该目录 说明数据存在
if os.path.isdir(root):
print(root+'目录已经存在!')
return
'''
如果文件夹不存在 创建文件夹
'''
#'data'目录不存在,创建目录
os.mkdir(root)
#创建文件失败
if not os.path.isdir(root):
print(root+'目录创建失败!')
return
#创建'test'和'train'目录 以及子文件夹
train = os.path.join(root,'train')
os.mkdir(train)
if os.path.isdir(train):
for i in range(10):
name = os.path.join(train,str(i))
os.mkdir(name)
test = os.path.join(root,'test')
os.mkdir(test)
if os.path.isdir(test):
for i in range(10):
name = os.path.join(test,str(i))
os.mkdir(name)
'''
把训练集数据转换为图片
'''
data_dir = 'cifar-10-batches-py' #数据所在目录
filelist = []
for i in range(5):
name = os.path.join(data_dir,str('data_batch_%d'%(i+1)))
filelist.append(name)
data = datagenerator()
#获取训练集数据
train_x = data.get_data_by_keyword('data',filelist,
normalized=True,size=(32,32))
#标签
train_y = data.get_data_by_keyword('labels',filelist)
#读取图片文件名
train_filename = data.get_data_by_keyword('filenames',filelist)
#保存训练集的文件名和标签
train_file_labels = []
#保存图片
for i in range(len(train_x)):
#获取图片标签
y = int(train_y[i])
#文件保存目录
dir_name = os.path.join(train,str(y))
#获取文件名
file_name = train_filename[i]
#文件的保存路径
file_path = os.path.join(dir_name,file_name)
#保存图片
io.imsave(file_path,train_x[i])
#追加第i张图片路径和标签 (文件路径,标签)
train_file_labels.append((file_path,y))
if i % 1000 == 0:
print('训练集完成度{0}/{1}'.format(i,len(train_x)))
for i in range(10):
print('训练集前10张图片:',train_file_labels[i])
#保存训练集的文件名和标签
with open('CIFAR-10-train-label.pkl','wb') as f:
pickle.dump(train_file_labels,f)
print('训练集图片保存成功!\n')
'''
把测试集数据转换为图片
'''
filelist = [os.path.join(data_dir,'test_batch')]
#获取训练集数据 数据标准化为0-1之间
test_x = data.get_data_by_keyword('data',filelist,
normalized=True,size=(32,32))
#标签
test_y = data.get_data_by_keyword('labels',filelist)
#读取图片文件名
test_filename = data.get_data_by_keyword('filenames',filelist)
#保存测试卷的文件名和标签
test_file_labels = []
#保存图片
for i in range(len(test_x)):
#获取图片标签
y = int(test_y[i])
#文件保存目录
dir_name = os.path.join(test,str(y))
#获取文件名
file_name = test_filename[i]
#文件的保存路径
file_path = os.path.join(dir_name,file_name)
#保存图片 这里要求图片像素值在-1-1之间,所以在获取数据的时候做了标准化
io.imsave(file_path,test_x[i])
#追加第i张图片路径和标签 (文件路径,标签)
test_file_labels.append((file_path,y))
if i % 1000 == 0:
print('测试集完成度{0}/{1}'.format(i,len(test_x)))
print('测绘集图片保存成功!\n')
#保存测试卷的文件名和标签
with open('CIFAR-10-test-label.pkl','wb') as f:
pickle.dump(test_file_labels,f)
for i in range(10):
print('测试集前10张图片:',test_file_labels[i])
def load_data():
'''
加载数据集
返回训练集数据和测试卷数据
training_data 由(x,y)元组组成的list集合
x:图片路径
y:对应标签
'''
#加载使用的训练集文件名和标签 [(文件路径,标签),....]
with open('CIFAR-10-train-label.pkl','rb') as f:
training_data = pickle.load(f)
#加载使用的测试集文件名和标签
with open('CIFAR-10-test-label.pkl','rb') as f:
test_data = pickle.load(f)
return training_data,test_data
def get_one_hot_label(labels,depth):
'''
把标签二值化 返回numpy.array类型
args:
labels:标签的集合
depth:标签总共有多少类
'''
m = np.zeros([len(labels),depth])
for i in range(len(labels)):
m[i][labels[i]] = 1
return m
def get_image_data_and_label(value,image_size='NONE',depth=10,one_hot = False):
'''
获取图片数据,以及标签数据 注意每张图片维度为 n_w x n_h x n_c
args:
value:由(x,y)元组组成的numpy.array类型
x:图片路径
y:对应标签
image_size:图片大小 'NONE':不改变图片尺寸
one_hot:把标签二值化
depth:数据类别个数
'''
#图片数据集合
x_batch = []
#图片对应的标签集合
y_batch = []
#遍历每一张图片
for image in value:
if image_size == 'NONE':
x_batch.append(cv2.imread(image[0])/255) #标准化0-1之间
else:
x_batch.append(cv2.resize(cv2.imread(image[0]),image_size)/255)
y_batch.append(image[1])
if one_hot == True:
#标签二值化
y_batch = get_one_hot_label(y_batch,depth)
return np.asarray(x_batch,dtype=np.float32),np.asarray(y_batch,dtype=np.float32)
'''
测试 保存所有图片
'''
save_images()
---------------------
原文:https://blog.csdn.net/davincil/article/details/78793067