【HDFS】【HDFS架构】【HDFS Architecture】【架构】
目录
1 Introduction 介绍
2 Assumptions and Goals 假设和目标
Hardware Failure 硬件故障
Streaming Data Access 流式数据访问
Large Data Sets 大型数据集
Simple Coherency Model 简单凝聚力模型
“Moving Computation is Cheaper than Moving Data”“移动计算比移动数据更便宜”
Portability Across Heterogeneous Hardware and Software Platforms跨异构硬件和软件平台的可移植性
3 NameNode and DataNodes NameNode和DataNode
4 The File System Namespace文件系统命名空间
5 Data Replication 数据复制
Replica Placement: The First Baby Steps专辑名称:The First Baby Steps
Replica Selection 副本选择
Block Placement Policies块放置策略
Safemode 安全模式
6 The Persistence of File System Metadata文件系统元数据的持久化
7 The Communication Protocols的通信协议
8 Robustness 稳健性
Data Disk Failure, Heartbeats and Re-Replication数据磁盘故障、心跳和重新复制
Cluster Rebalancing 集群再平衡
Data Integrity 数据完整性
Metadata Disk Failure 元数据磁盘故障
Snapshots 快照
9 Data Organization 数据组织
Data Blocks 数据块
Replication Pipelining 复制流水线
10 Accessibility 无障碍
FS Shell FS外壳
DFSAdmin
Browser Interface 浏览器界面
11 Space Reclamation 空间回收
File Deletes and Undeletes文件删除和取消删除
Decrease Replication Factor降低复制因子
1 Introduction 介绍
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware.
HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS relaxes a few POSIX requirements to enable streaming access to file system data.
HDFS was originally built as infrastructure for the Apache Nutch web search engine project. HDFS is part of the Apache Hadoop Core project. The project URL is Apache Hadoop.
Hadoop分布式文件系统(HDFS)是一种设计用于在商用硬件上运行的分布式文件系统。
它与现有的分布式文件系统有许多相似之处。然而,与其他分布式文件系统的差异是显著的。HDFS具有高度容错性,旨在部署在低成本硬件上。
HDFS提供对应用程序数据的高吞吐量访问,适用于具有大型数据集的应用程序。HDFS放宽了一些POSIX要求,以支持对文件系统数据的流式访问。
HDFS最初是作为Apache Nutch Web搜索引擎项目的基础设施而构建的。HDFS是Apache Hadoop Core项目的一部分。项目URL是http://hadoop.apache.org/。
2 Assumptions and Goals 假设和目标
Hardware Failure 硬件故障
Hardware failure is the norm rather than the exception. An HDFS instance may consist of hundreds or thousands of server machines, each storing part of the file system’s data. The fact that there are a huge number of components and that each component has a non-trivial probability of failure means that some component of HDFS is always non-functional. Therefore, detection of faults and quick, automatic recovery from them is a core architectural goal of HDFS.
硬件故障是常态而不是例外。HDFS实例可能由数百或数千个服务器机器组成,每个服务器机器存储文件系统的部分数据。事实上,有大量的组件,每个组件都有一个不平凡的失败概率,这意味着HDFS的一些组件总是不起作用的。因此,故障检测和快速自动恢复是HDFS的核心架构目标。
Streaming Data Access 流式数据访问
Applications that run on HDFS need streaming access to their data sets. They are not general purpose applications that typically run on general purpose file systems. HDFS is designed more for batch processing rather than interactive use by users. The emphasis is on high throughput of data access rather than low latency of data access. POSIX imposes many hard requirements that are not needed for applications that are targeted for HDFS. POSIX semantics in a few key areas has been traded to increase data throughput rates.
在HDFS上运行的应用程序需要流式访问其数据集。它们不是通常在通用文件系统上运行的通用应用程序。HDFS更多地是为批处理而设计的,而不是供用户交互使用。重点是数据访问的高吞吐量,而不是数据访问的低延迟。POSIX强加了许多针对HDFS的应用程序不需要的硬性要求。在一些关键领域,POSIX语义已经被用来提高数据吞吐率。
Large Data Sets 大型数据集
Applications that run on HDFS have large data sets. A typical file in HDFS is gigabytes to terabytes in size. Thus, HDFS is tuned to support large files. It should provide high aggregate data bandwidth and scale to hundreds of nodes in a single cluster. It should support tens of millions of files in a single instance.
在HDFS上运行的应用程序具有大型数据集。HDFS中的典型文件大小为千兆字节到兆兆字节。因此,HDFS被调整为支持大文件。它应该提供高聚合数据带宽,并可扩展到单个集群中的数百个节点。它应该在单个实例中支持数千万个文件。
Simple Coherency Model 简单凝聚力模型
HDFS applications need a write-once-read-many access model for files. A file once created, written, and closed need not be changed except for appends and truncates. Appending the content to the end of the files is supported but cannot be updated at arbitrary point. This assumption simplifies data coherency issues and enables high throughput data access. A MapReduce application or a web crawler application fits perfectly with this model.
HDFS应用程序需要一个一写多读的文件访问模型。一个文件一旦被创建、写入和关闭,除了追加和截断之外,就不需要再进行更改。支持将内容保留到文件末尾,但不能在任意点进行更新。这种假设简化了数据一致性问题,并支持高吞吐量数据访问。MapReduce应用程序或网络爬虫应用程序非常适合这种模型。
“Moving Computation is Cheaper than Moving Data”
“移动计算比移动数据更便宜”
A computation requested by an application is much more efficient if it is executed near the data it operates on. This is especially true when the size of the data set is huge. This minimizes network congestion and increases the overall throughput of the system. The assumption is that it is often better to migrate the computation closer to where the data is located rather than moving the data to where the application is running. HDFS provides interfaces for applications to move themselves closer to where the data is located.
应用程序请求的计算如果在它所操作的数据附近执行,效率会高得多。当数据集很大时尤其如此。这最小化了网络拥塞并增加了系统的总吞吐量。这里的假设是,将计算迁移到更靠近数据所在的位置,而不是将数据移动到应用程序运行的位置,通常会更好。HDFS为应用程序提供接口,使其更接近数据所在的位置。
Portability Across Heterogeneous Hardware and Software Platforms
跨异构硬件和软件平台的可移植性
HDFS has been designed to be easily portable from one platform to another. This facilitates widespread adoption of HDFS as a platform of choice for a large set of applications.
HDFS被设计为可以从一个平台轻松移植到另一个平台。这促进了HDFS作为大量应用程序的首选平台的广泛采用。
3 NameNode and DataNodes NameNode和DataNode
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
HDFS有一个主/从架构。HDFS集群由一个NameNode组成,NameNode是一个主服务器,它管理文件系统命名空间并管理客户端对文件的访问。此外,还有许多DataNode,通常集群中每个节点一个,用于管理连接到它们运行的节点的存储。HDFS公开了文件系统命名空间,并允许用户数据存储在文件中。在内部,文件被分割成一个或多个块,这些块存储在一组DataNode中。NameNode执行文件系统命名空间操作,如打开、关闭和重命名文件和目录。它还确定块到DataNode的映射。DataNode负责处理来自文件系统客户端的读写请求。DataNode还根据NameNode的指令执行块创建、删除和复制。
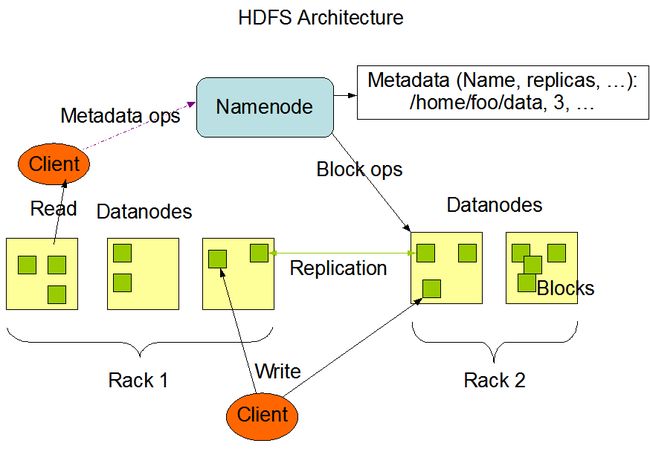
The NameNode and DataNode are pieces of software designed to run on commodity machines. These machines typically run a GNU/Linux operating system (OS). HDFS is built using the Java language; any machine that supports Java can run the NameNode or the DataNode software. Usage of the highly portable Java language means that HDFS can be deployed on a wide range of machines. A typical deployment has a dedicated machine that runs only the NameNode software. Each of the other machines in the cluster runs one instance of the DataNode software. The architecture does not preclude running multiple DataNodes on the same machine but in a real deployment that is rarely the case.
NameNode和DataNode是设计用于在商用机器上运行的软件。这些机器通常运行GNU/Linux操作系统(OS)。HDFS使用Java语言构建;任何支持Java的机器都可以运行NameNode或DataNode软件。使用高度可移植的Java语言意味着HDFS可以部署在各种机器上。典型的部署有一个专用的机器,只运行NameNode软件。集群中的其他每台机器都运行DataNode软件的一个实例。该架构不排除在同一台机器上运行多个DataNode,但在真实的部署中,这种情况很少发生。
The existence of a single NameNode in a cluster greatly simplifies the architecture of the system. The NameNode is the arbitrator and repository for all HDFS metadata. The system is designed in such a way that user data never flows through the NameNode.
集群中单个NameNode的存在大大简化了系统的架构。NameNode是所有HDFS元数据的仲裁器和存储库。系统的设计方式是用户数据永远不会流经NameNode。
4 The File System Namespace
文件系统命名空间
HDFS supports a traditional hierarchical file organization. A user or an application can create directories and store files inside these directories. The file system namespace hierarchy is similar to most other existing file systems; one can create and remove files, move a file from one directory to another, or rename a file. HDFS supports user quotas and access permissions. HDFS does not support hard links or soft links. However, the HDFS architecture does not preclude implementing these features.
HDFS支持传统的分层文件组织。用户或应用程序可以创建目录并在这些目录中存储文件。文件系统命名空间层次结构与大多数其他现有文件系统类似;可以创建和删除文件,将文件从一个目录移动到另一个目录,或者重命名文件。HDFS支持用户配额和访问权限。HDFS不支持硬链接或软链接。然而,HDFS架构并不排除实现这些功能。
While HDFS follows