基于Tensorflow的神经网络解决用户流失概率问题

沙韬伟,苏宁易购高级算法工程师。
曾任职于Hewlett-Packard、滴滴出行。
数据学院特邀讲师。
主要研究方向包括风控、推荐和半监督学习。目前专注于基于深度学习及集成模型下的用户行为模式的识别。
用户流失一直都是公司非常重视的一个问题,也是AAARR中的Retention的核心问题,所以各大算法竞赛都很关注。比如最近的:KKBOX的会员流失预测算法竞赛(https://www.kaggle.com/c/kkbox-churn-prediction-challenge),如何能够搭建一个精准的模型成了大家探索的重要问题。
本文主要讲解神经网络、TensorFlow的概述、如何利用python基于TensorFlow神经网络对流失用户进行分类预测,及可能存在的一些常见问题,作为深度学习的入门阅读比较适合。
通常的行业预测用户流失大概分以下几种思路:
1、利用线性模型(比如Logistic)+非线性模型Xgboost判断用户是否回流逝
这种方法有关是行业里面用的最多的,效果也被得意验证足够优秀且稳定的。核心点在于特征的预处理,Xgboost的参数挑优,拟合程度的控制,这个方法值得读者去仔细研究一边。问题也是很明显的,会有一个行业baseline,基本上达到上限之后,想有有提升会非常困难,对要求精准预测的需求会显得非常乏力。
2、规则触发
这种方法比较古老,但是任然有很多公司选择使用,实现成本较低而且非常快速。核心在于,先确定几条核心的流失指标(比如近7日登录时长),然后动态的选择一个移动的窗口,不停根据已经流失的用户去更新流失指标的阈值。当新用户达到阈值的时候,触发流失预警。效果不如第一个方法,但是实现简单,老板也很容易懂。
3、场景模型的预测
这个方法比较依赖于公司业务的特征,如果公司业务有部分依赖于评论,可以做文本分析,比如我上次写的基于word2vec下的用户流失概率分析(http://www.jianshu.com/p/413cff5b9f3a)。如果业务有部分依赖于登录打卡,可以做时间线上的频次预估。这些都是比较偏奇门易巧,不属于通用类别的,不过当第一种方法达到上线的时候,这种方法补充收益会非常的大。
其实还有很多其它方法,我这边也不一一列出了,这个领域的方法论还是很多的。

神经网络流程
上面这张图片诠释了神经网络正向传播的流程,先通过线性变换(上图左侧)Σxw+b将线性可分的数据分离,再通过非线性变换(上图右侧)Sigmoid函数将非线性可分的数据分离,最后将输入空间投向另一个输出空间。
根据上面所说,我们可以知道,通过增加左侧线性节点的个数,我们可以强化线性变换的力度;而通过增加层数,多做N次激活函数(比如上面提到的Sigmoid)可以增强非线性变换的能力。
通过矩阵的线性变换+激活矩阵的非线性变换,将原始不可分的数据,先映射到高纬度,再进行分离。但是这边左侧节点的个数,网络的层数选择是非常困难的课题,需要反复尝试。
刚才我们了解了整个训练的流程,但是如何训练好包括线性变换的矩阵系数是一个还没有解决的问题。
我们来看下面的过程:
input ==> Σxw+b(线性变换) ==> f(Σxw+b)(激活函数) ==> ...(多层的话重复前面过程) ==> output(到此为止,正向传播结束,反向修正矩阵weights开始) ==> error=actual_output-output(计算预测值与正式值误差)==>output处的梯度==>调整后矩阵weight=当前矩阵weight+errorx学习速率xoutput处的负梯度。
核心目的在于通过比较预测值和实际值来调整权重矩阵,将预测值与实际值的差值缩小。
比如:梯度下降的方法,通过计算当前的损失值的方向的负方向,控制学习速率来降低预测值与实际值间的误差。
利用一行代码来解释就是
synaptic_weights += dot(inputs, (real_outputs - output) * output * (1 - output))*η
这边output * (1 - output))是在output处的Sigmoid的倒数形式,η是学习速率。
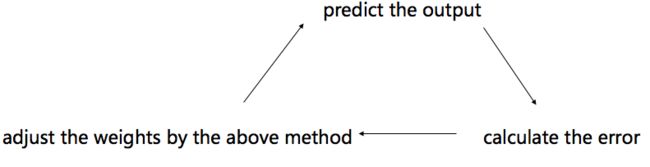
weight的循环流程
1数据集获取(有监督数据整理) 2神经网络参数确定,有多少层,多少个节点,激活函数是什么,损失函数是什么 3数据预处理,pca,标准化,中心化,特征压缩,异常值处理 4初始化网络权重 5网络训练 5.1正向传播 5.2计算loss 5.3计算反向梯度 5.4更新梯度 5.5重新正向传播
这边只是简单介绍了神经网络的基础知识,针对有一定基础的朋友唤醒记忆,如果纯小白用户,建议从头开始认真阅读理解一遍过程,避免我讲的有偏颇的地方对你进行误导。
理论上讲,TensorFlow工具可以单独写一本书,用法很多而且技巧性的东西也非常的复
杂,这边我们主要作为工具进行使用,遇到新技巧会在code中解释,但不做全书的梳理,建议去买一本《TensorFlow实战Google深度学习框架》,简单易懂。
TensorFlow是谷歌于2015年11月9日正式开源的计算框架,由Jeff Dean领导的谷歌大脑团队改编的DistBelief得到的,在ImageNet2014、YouTube视频学习,语言识别错误率优化,街景识别,广告,电商等等都有了非常优秀的产出,是我个人非常喜欢的工具。
除此之外,我在列出一些其他的框架工具供读者使用:


接下来看一下最基本的语法,方便之后我们直接贴代码的时候可以轻松阅读。
-
张量:可以理解为多维array 或者 list,time决定张量是什么
tf.placeholder(time,shape,name)
-
变量:同一时刻下的不变的数据
tf.Variable(value,name) -
常量:永远不变的常值
tf.constant(value) -
执行环境开启与关闭,在环境中才能运行TensorFlow语法
sess=tf.Session()
sess.close()
sess.run(op) -
初始化所有权重:类似于变量申明
tf.initialize_all_variables() -
更新权重:
tf.assign(variable_to_be_updated,new_value) -
加值行为,利用feed_dict里面的值来训练[output]函数
sess.run([output],feed_dict={input1:value1,input2:value2})
利用input1,input2,来跑output的值 -
矩阵乘法,类似于dot
tf.matmul(input,layer1) -
激活函数,relu
tf.nn.relu(),除此之外,还有tf.nn.sigmoid,tf.nn.tanh等等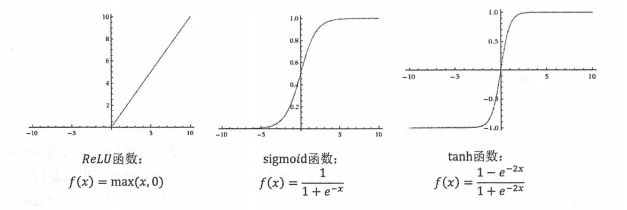
说了那么多前置的铺垫,让我们来真实的面对我们需要解决的问题:
首先,我们拿到了用户是否流失的历史数据集20724条,流失与飞流失用户占比在1:4,这部分数据需要进行一下预处理,这边就不细讲预处理过程了,包含缺失值填充(分层填充),异常值处理(isolation foest),数据平衡(tomek link),特征选择(xgboost importance),特征变形(normalizing),特征分布优化等等,工程技巧我之前的文章都有讲解过,不做本文重点。
taiking is cheap,show me the code.

#author:shataowei #time:20170924 #基础包加载 import numpy as np import pandas as pd import tensorflow as tf import math from sklearn.cross_validation import train_test_split
#数据处理
data = pd.read_table('/Users/slade/Desktop/machine learning/data/data_all.txt')
data = data.iloc[:,1:len(data.columns)]
data1 = (data - data.mean())/data.std()
labels = data['tag'] items = data1.iloc[:,1:len(data1.columns)]
all_data = pd.concat([pd.DataFrame(labels),items],axis = 1)
#数据集切分成训练集和测试集,占比为0.8:0.2
train_X,test_X,train_y,test_y = train_test_split(items,labels,test_size = 0.2,random_state = 0) #pandas读取进来是dataframe,转换为ndarray的形式
train_X = np.array(train_X)
test_X = np.array(test_X)
#我将0或者1的预测结果转换成了[0,1]或者[1,0]的对应形式,读者可以不转
train_Y = [] for i in train_y:
if i ==0:
train_Y.append([0,1])
else:
train_Y.append([1,0])
test_Y = [] for i in test_y:
if i ==0:
test_Y.append([0,1])
else:
test_Y.append([1,0])
下面我们就要开始正式开始训练神经网络了.
input_node = 9 #输入的feature的个数,也就是input的维度
output_node = 2 #输出的[0,1]或者[1,0]的维度
layer1_node = 500 #隐藏层的节点个数,一般在255-1000之间,读者可以自行调整
batch_size = 200 #批量训练的数据,batch_size越小训练时间越长,训练效果越准确(但会存在过拟合)
learning_rate_base = 0.8 #训练weights的速率η
regularzation_rate = 0.0001 #正则力度
training_steps = 10000 #训练次数,这个指标需要类似grid_search进行搜索优化 #设定之后想要被训练的x及对应的正式结果y_
x = tf.placeholder(tf.float32,[None,input_node])
y_ = tf.placeholder(tf.float32,[None,output_node])
#input到layer1之间的线性矩阵
weight weight1 = tf.Variable(tf.truncated_normal([input_node,layer1_node],stddev=0.1))
#layer1到output之间的线性矩阵
weight weight2 = tf.Variable(tf.truncated_normal([layer1_node,output_node],stddev=0.1))
#input到layer1之间的线性矩阵的偏置
biases1 = tf.Variable(tf.constant(0.1,shape = [layer1_node]))
#layer1到output之间的线性矩阵的偏置
biases2 = tf.Variable(tf.constant(0.1,shape=[output_node]))
#正向传播的流程,线性计算及激活函数relu的非线性计算得到result
def interence(input_tensor,weight1,weight2,biases1,biases2):
layer1 = tf.nn.relu(tf.matmul(input_tensor,weight1)+biases1)
result = tf.matmul(layer1,weight2)+biases2
return result
y = interence(x,weight1,weight2,biases1,biases2)
正向传播完成后,我们要反向传播来修正weight
global_step = tf.Variable(0,trainable = False)
#交叉熵,用来衡量两个分布之间的相似程度
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels = y_,logits=y) cross_entropy_mean = tf.reduce_mean(cross_entropy)
#l2正则化,这部分的理论分析可以参考我之前写的:http://www.jianshu.com/p/4f91f0dcba95 regularzer = tf.contrib.layers.l2_regularizer(regularzation_rate)
regularzation = regularzer(weight1) + regularzer(weight2)
#损失函数为交叉熵+正则化
loss = cross_entropy_mean + regularzation
#我们用learning_rate_base作为速率η,来训练梯度下降的loss函数解
train_op = tf.train.GradientDescentOptimizer(learning_rate_base).minimize(loss,global_step = global_step)
#y是我们的预测值,y_是真实值,我们来找到y_及y(比如[0.1,0.2])中最大值对应的index位置,判断y与y_是否一致
correction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
#如果y与y_一致则为1,否则为0,mean正好为其准确率
accurary = tf.reduce_mean(tf.cast(correction,tf.float32))
模型训练结果
#初始化环境,设置输入值,检验值
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
validate_feed = {x:train_X,y_:train_Y}
test_feed = {x:test_X,y_:test_Y}
#模型训练,每到1000次汇报一次训练效果
for i in range(training_steps):
start = (i*batch_size)%len(train_X)
end = min(start+batch_size,16579)
xs = train_X[start:end]
ys = train_Y[start:end]
if i%1000 ==0:
validate_accuary = sess.run(accurary,feed_dict = validate_feed)
print 'the times of training is %d, and the accurary is %s' %(i,validate_accuary) sess.run(train_op,feed_dict = {x:xs,y_:ys})
训练的结果如下:
2017-09-24 12:11:28.409585: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations. 2017-09-24 12:11:28.409620: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations. 2017-09-24 12:11:28.409628: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations. 2017-09-24 12:11:28.409635: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations. the times of training is 0, and the accurary is 0.736775 the times of training is 1000, and the accurary is 0.99246 the times of training is 2000, and the accurary is 0.993003 the times of training is 3000, and the accurary is 0.992943 the times of training is 4000, and the accurary is 0.992943 the times of training is 5000, and the accurary is 0.99234 the times of training is 6000, and the accurary is 0.993124 the times of training is 7000, and the accurary is 0.992943 the times of training is 8000, and the accurary is 0.993124 the times of training is 9000, and the accurary is 0.992943
初步看出,在训练集合上,准确率在能够99%以上,让我们在看看测试集效果。
test_accuary = sess.run(accurary,feed_dict = test_feed)
Out[5]: 0.99034983,也是我们的测试数据集效果也是在99%附近,可以看出这个分类的效果还是比较高的。
初次之外,我们还可以得到每个值被预测出来的结果,也可以通过工程技巧转换为0-1的概率:
result_y = sess.run(y,feed_dict={x:train_X}) result_y_update=[] for i in result_y: if i[0]>=i[1]: result_y_update.append([1,0]) else: result_y_update.append([0,1])
==>
Out[7]: array([[-1.01412344, 1.21461654], [-3.66026735, 3.81834102], [-3.78952932, 3.79097509], ..., [-3.71239662, 3.65721083], [-1.59250259, 1.89412308], [-3.35591984, 3.24001145]], dtype=float32)
以上就实现了如果用TensorFlow里面的神经网络技巧去做一个分类问题,其实这并不TensorFlow的全部,传统的Bp神经网络,SVM也可以到达近似的效果,在接下来的文章中,我们将继续看到比如CNN图像识别,LSTM进行文本分类,RNN训练不均衡数据等复杂问题上面的优势。
在刚做神经网络的训练前,要注意一下是否会犯以下的错误。
1、数据是否规范化
模型计算的过程时间长度及模型最后的效果,均依赖于input的形式。大部分的神经网络训练过程都是以input为1的标准差,0的均值为前提的;除此之外,在算梯度算反向传播的时候,过大的值有可能会导致梯度消失等意想不到的情况,非常值得大家注意。
2、batch的选择
在上面我也提了,过小的batch会增加模型过拟合的风险,且计算的时间大大增加。过大的batch会造成模型的拟合能力不足,可能会被局部最小值卡住等等,所以需要多次选择并计算尝试。
3、过拟合的问题
是否在计算过程中只考虑了损失函数比如交叉熵,有没有考虑l2正则、l2正则,或者有没有进行dropout行为,是否有必要加入噪声,在什么地方加入噪声(weight?input?),需不需要结合Bagging或者bayes方法等。
4、激活函数的选择是否正确
比如relu只能产出>=0的结果,是否符合最后的产出结果要求。比如Sigmoid的函数在数据离散且均大于+3的数据集合上会产生梯度消失的问题,等等。
到这里,我觉得一篇用TensorFlow来训练分类模型来解决用户流失这个问题就基本上算是梳理完了。很多简单的知识点我没有提,上面这些算是比较重要的模块,希望对大家有所帮助,最后谢谢大家的阅读。
原文链接:http://www.jianshu.com/p/f26e232bff57
 BY
简书
BY
简书
往期精彩回顾

深度学习视频(一) | 免费放送—深度学习的应用场景和数学基础
深度学习视频(二) | 免费放送—卷积神经网络(一)
深度学习视频(三) | 免费放送—卷积神经网络(二)
深度学习视频(四) | 免费放送—深度学习的具体模型和方法
深度学习视频(五) | 免费放送—上机实操(一)


点击“阅读原文”直接打开【北京站 | GPU CUDA 进阶课程】报名链接