语义搜索(semantic searching)简介
2000s 以来,“语义搜索”是信息检索和知识图谱等领域的一类重要话题。一言蔽之,“语义”即“某种表达的含义”。“让计算机更好地理解人类”是学术界和产业界的共同愿景,以至于有人提出,机器的“理解力”≈“智能”水平,一旦解决了“理解”问题,人类就具备了制造“通用人工智能”的能力。
本文将对“语义搜索”做一个蜻蜓点水式的简单介绍。可能需要读者对信息检索/自然语言处理/知识图谱/数据库/机器学习等领域有最基础的了解。
概念 & 背景
语义搜索(Semantic Search)正式提出大概在2007~2009年。与之对应的是词法搜索(lexical search),即采用字面值一一对应或字符串相似度等进行资源召回的方式。这类方法的缺点显而易见——无法处理同名、别名和复杂情形,例如你在中国大陆使用一个通用 web 搜索引擎时:
-
菠萝、凤梨,猕猴桃、奇异果所指代的对象理论上是相同的
-
“中国”的返回结果中最可能排首位的是“中华人民共和国”,而不是“中国地区”(日本)或“发展中国家”
-
“第92届奥斯卡最佳影片是什么”,用户希望得到一个准确的电影的名字,而不是诸如
2020年第92届奥斯卡金像奖获奖名单已经公布,名单上都有哪些获奖作品呢?下面跟小编一起来看看吧。blahblahblah
这样的废话。
前面说过,“语义搜索”希望利用某种表达的“含义”而非字面值去寻找与之匹配的资源。既然使用“含义”而非字面值,那么它至少应当具备
- 异名同义归一化(disambiguation)
- 必要时将关键词(keyword)映射为特定实体(entity)
- 根据知识库(knowledge base)回答 5W1H 问题
这三种能力。
学术界对语义搜索的定义暂时还未达成大范围的共识(笔者理解为对技术路线仍有较大争议),不同研究方向的人看法差别较大。对此,(Bast, 2016) 建议“搁置争议、抽取共识”[2]:
Semantic Search is simply “SEARCH WITH MEANING”.
这样讲通俗易懂,但对 “meaning” 理解不同,仍然会产生较大的分歧。仅供读者参考。
(Li, 2014) 提出了一种侧面刻画。作者认为“语义搜索”和“语义匹配(semantic matching)”存在这样的差异[1]:
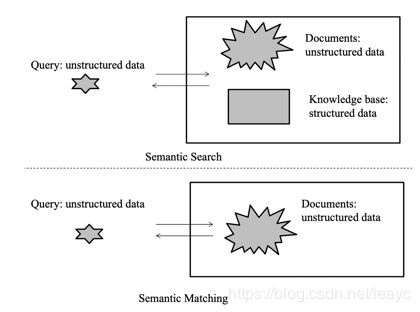
(图中的结构化(structured)数据与非结构化(unstructured)数据将在后文稍作解释。)
不过这两种情况均被 (Bast, 2016) 所包含,可见上文中所说的“分歧”。
不得不承认,Google 诞生后,在信息检索领域工业界相对学术界的优势越发显著。2010s 后,Google 通过大张旗鼓地收购开源知识库、建设知识图谱,已经实现了“语义搜索”的一部分能力,例如使用英文检索 [2]
computer scientists
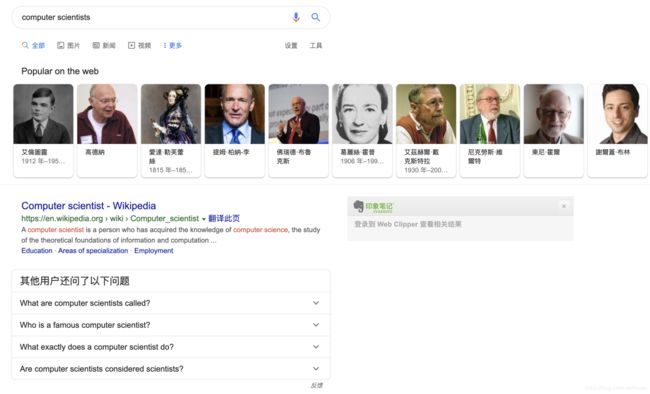
与以往一般的搜索返回不同,最上方出现了一组卡片。读者可以自行尝试点击卡片,【印象笔记】下会出现这位 computer scientist 的维基百科摘要。如果用户完全不了解背后的技术细节,ta 很可能会认为,Google 理解了 ta 所要寻找的对象(一类人)并返回了一组与之高度相关的结果。
但是且慢,再试试这个:
female computer scientists working on semantic search
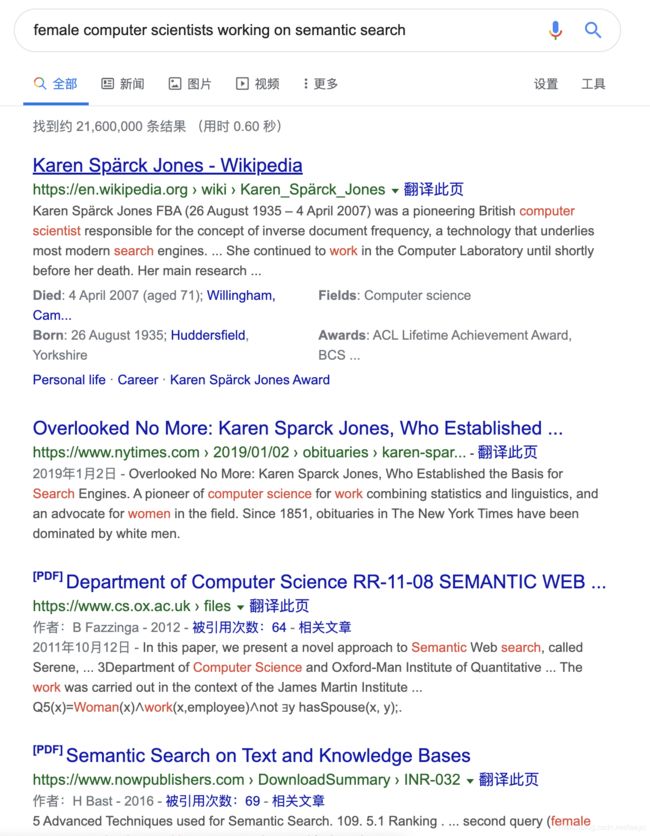
人工智障瞬间打回原形。
虽然第一条结果确实完全满足用户的搜索条件,但是维基百科在 Google 的排序中优先级较高,第四条更明示了本次搜索并没有“语义”的参与(如不理解请参考[2]原文)。
再看一个 case:
杨利伟的生日是什么时候?
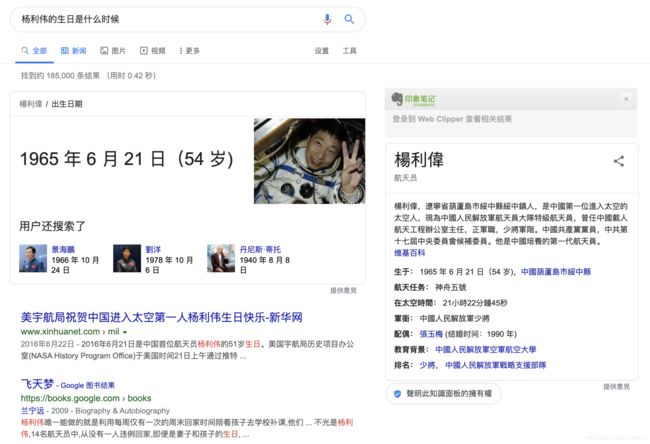
这样的“复杂 query”是知识图谱领域所试图解决的一类问题,即“基于知识库的自然语言问答”。
如果读者在2010年以前就经常使用 Google、百度等搜索引擎,也许会记得一些“搜索小技巧”,如把问题拆分成关键词、使用限定符号。随着搜索引擎技术的进步和互联网数据的指数增加,这些技巧逐渐变得无关紧要,用户也能询问更加复杂的问题,背后体现的正是“词法搜索”向“语义搜索”转变的趋势:搜索引擎变得更清晰地理解用户的查询意图,并返回相关度更高、质量也更好的资源。
分类
“理解”非一日之功;“语义搜索”背后是一系列庞大复杂的技术体系。为了更细致地梳理相关工作,Bast 等将语义搜索按照数据(data)和搜索方式(Search)两个维度分成了九种情况[2]:

具体来说,Bast 认为,最基本的数据可以分为文本(text)和知识库(knowledge base)两类,随着语义网/知识图谱的发展,还出现了混合数据(combined data),即带有语义标记的文本,最典型的如 html5;搜索则通常可以分为关键词搜索、结构化搜索和自然语言搜索。两两组合,就有图上九种情况。
除此之外,还有分面搜索(facet search)和表示搜索(representation search)等方式。分面搜索其实相当常用:
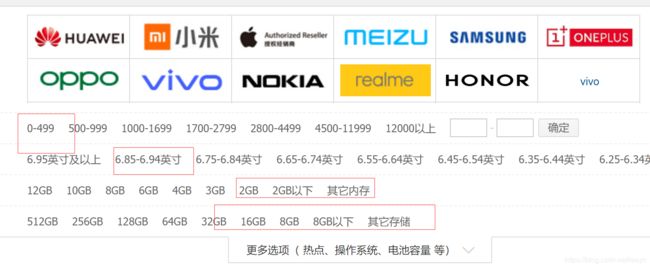
在购物或生活服务网站逐层点击有限标签得到相应结果,就是最典型的分面搜索。至于表示搜索,现在一般指把知识图谱中的节点、关系等进行低维嵌入(embedding)后再做处理的方式。
回到前面的九类基本语义搜索。
读者比较熟悉的有“文本数据上的关键词搜索”和“文本数据上的 QA”:前者即传统搜索的“关键词 Query 召回文档资源”流程,后者的实现方式大多是先把用户的问题句子转化为一组关键词,后续处理与前者相同。以下为了方便起见,用“类型”+序号标识:
- 基于文本的关键词搜索
- 基于知识库的结构化搜索
- 从文本中抽取结构化数据
- 基于知识库的关键词搜索
基于混合数据的关键词搜索基于混合数据的半结构化搜索- 基于文本的 QA
- 基于知识库的 QA
基于混合数据的 QA
其中,混合数据的三种类型没有必要在本文中解释,略去不谈。
类型1
词法搜索是 web 搜索的基础。虽说语义搜索的目标是理解,但请读者试想,要用怎样的方式让计算机学会人脑处理信息的方式呢?想不出来是对的。
词法搜索积累丰富历史悠久,关注的是搜索质量,一般分为召回/匹配和排序两个步骤。这方面比较新的话题是 learning to match 和 learning to rank,即将机器学习算法融合到流程中。
类型2
类型2在中文资料中往往与“知识图谱”一同出现,简称 KBQA 。知识库中存储了大量的实体、关系对,一般表现为 SPO 三元组,形如 <毕志飞,导演,逐梦演艺圈>。在这类数据上查询大都需要编写专用的查询指令,如 SPARQL,乍一看跟 SQL 挺像:
SELECT ?a WHERE {
mymo:489e1493d8b34285b5a24017e574c0f5 mymo:有导演 ?a.
}
类型2是另外两种知识库查询的基础设施,即类型4和8在实践中需要首先把输入转化为结构化查询语句,再按照类型2执行查询。
类型3
将文本数据抽取为结构化数据从而构建知识库显然不是一种搜索,而是基础设施建设。
类型7
类型7的描述容易造成一种误解:如果文档的标题就是用户的“Q”,这属于类型1中的特殊情况——关键词全文召回。上文中已经说过,类型7指的是采取一些方式,从用户完整的语句输入中抽出关键词,再按照类型1查询。
相关技术
前文说过,语义搜索背后是一系列庞大复杂的体系,需要多领域技术的支撑,如信息检索(information retrieval,IR)、自然语言处理(natural language processing,NLP)、语义网/知识图谱、数据库(用来存储、索引数据)、用户界面设计等。其中 NLP 技术又最为基础:
- 分词(chunking)和词性标注(PoS)
- 命名实体识别(NER)&实体消歧(NED)
- 句法分析(parsing)
- 词向量
不难想到它们各自的作用。在此之上,更复杂的话题包括
- 文档/实体排序
- 索引
- (当有多个知识库时的)本体匹配与融合
- 知识推理
每一类技术都相当复杂,此处也不再展开。
项目分析
本节以开源 demo 为例[3],分析一个最简单的语义搜索引擎是如何构建的。读者可下载代码自行尝试。项目作者也撰写了系列文章(但文章和代码都没有完成)。见[4]。
项目的显示效果如下图:

该系统从百度百科爬取数据构建知识库,用户输入问题如“《美人鱼》的导演是谁?”,系统应当回答“周星驰”。这是项目的结构,包括本体库构建、服务端、客户端三部分。
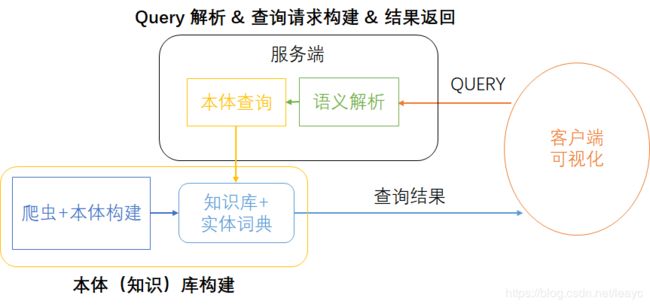
本体库构建
作者分析了一部分百度百科页面源码,手动建立了九种本体模板(人物、电影、音乐、动画等),通过爬虫下载网页,从中按照模板将文本提取为结构化数据:

结构化数据通过 Jena API 写入本体库(规模较小,直接生成为 owl 文件),同时更新实体词典(表格文档):
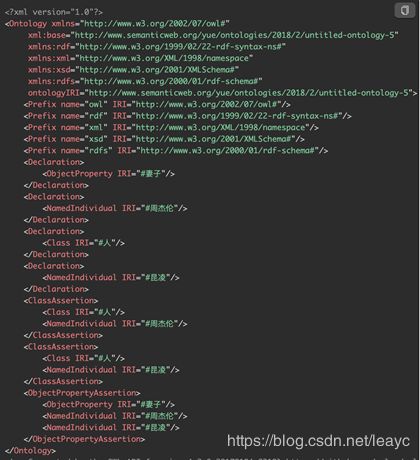

这条管道完成了本体(知识)库的建设。
服务端
语义解析
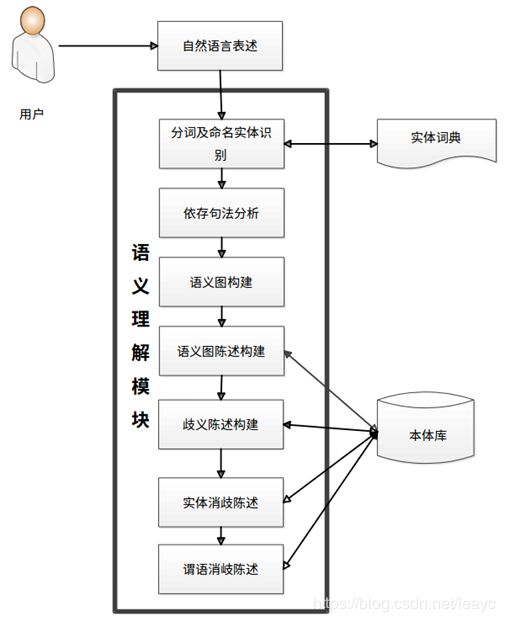
大体上,语义解析分如下步骤:
- 分词 & NER
- 句法分析
- 从语义图构建陈述
- 消歧
- 同名消歧
- 别名消歧
- 谓词消歧
先介绍一下陈述(statement)。陈述是 RDF 框架(一种知识图谱的构建方式)中的概念,一条陈述声明了某个资源的某个事实,形式上即 SPO 三元组,所以得到陈述就得到了 SPARQL 语句。
假设用户 Query 是“XX电影的导演是谁?”,那么分词和 NER 需要将用户 Query 中的电影实体识别出来;句法分析能够得到每个词的词性以及它们之间的依赖关系,该项目采用了[5]提出的方法,根据句法分析结果构建语义图:

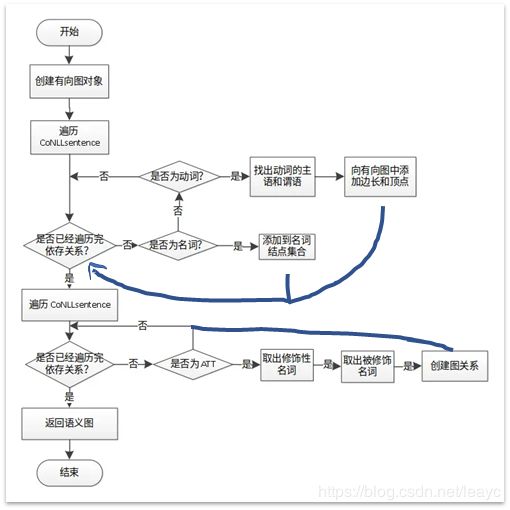
作者博客中的流程图有漏,笔者稍作补充。从语义图构建陈述的步骤是:
-
发现名词性节点和动词性节点
-
为名词性节点找到依存关系
-
为动词性节点找到 S、O
-
建立语义图
选择名词性节点和动词性节点的理由是,[5] 的作者经过统计(他们自己的数据),问句中的实体,近90%是名词,80%的关系是动词或者名词。这当然是不严谨的,这里仅作为最小实现中的一环。
语义图:
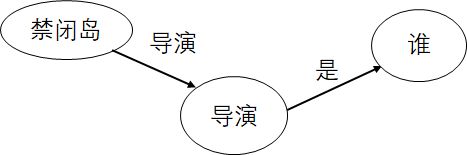
得到语义图,表明用户问句成分完整,于是重新拆分成

需要说明的是,这里的“导演”既是一种关系也是一个实体,与系统的实现方式有关。由于存储的数据形如
<禁闭岛, 有导演, 马丁·斯科塞斯>
直接形成
禁闭岛S -> 导演P -> 谁?O
也是可行的。
现在可以构建 SPARQL 语句了吗?先等等。尚不明确、需要做的事情分别还有:
- 怎么确定“禁闭岛”指的就是电影呢?—>同名消歧
- 知识库里一定有“禁闭岛”这个本体吗?它不能叫别的名字?—>别名消歧
- 有”导演“这条关系吗?—>谓词消歧
这三个步骤又涉及到许多方法。细心的读者可能会发现:名词消歧跟 NER 是不是重复了?
的确,NER、NED(命名实体消歧)通常指的是同一个过程。工业级应用中,NER 与 NED 往往同时进行涉及相当多的方法。本文介绍的项目为了降低实现难度,将 NED 拆分出来,放到了后面进行,也不算错。
同名实体 NED 的方法有很多。在这里最简单的办法是利用前面构建本体库时编写的模板。每一种模板定义了不同类型的本体,体现在不同类型的本体所包含的关系相差很大,比如电影名《禁闭岛》一定有”导演“这条关系(边),但作为地名的“禁闭岛”(如果有地方叫这个名字的话)一定不会有“导演”。
别名消歧,在实践中也并不一定使用多么高大上的技术,最简单的方式依然是扩充别名库。好比《追忆似水流年》与《追忆失去时光》指的是同一本书,那么搜其中一个只返回它自己就是不合适的。
谓词需要消歧,通常是因为知识库中的关系与句法分析得到的谓词不一定完全对应,最简单的方法是文本相似度计算。
本体查询
经过这一系列操作,得到陈述
<489e1493d8b34285b5a24017e574c0f5, 有导演, ?a>
借助 Jena API 可以直接生成 SPARQL 语句:
SELECT ?b WHERE {
mymo:489e1493d8b34285b5a24017e574c0f5 mymo:有导演 ?a.
?a mymo:是 ?b.
}
再调用 Jena API 对知识库查询即可。
总结
从词法搜索到语义搜索是一个渐进的过程,真正的“理解”还遥遥无期,是最终的目标。
语义搜索是多领域技术的综合产物,工程属性极强。落地应当采用什么技术,需要根据自身业务场景和成本综合考虑。
由于语义搜索的复杂性,使用场景至关重要,这一点本文没有涉及。除了对用户 Query 的直接解析,场景特性,用户的习惯、使用方式、历史信息,交互方式和界面设计,都值得深入思考研究。
参考文献
[1] Li, Hang, and Jun Xu. “Semantic matching in search.” Foundations and Trends® in Information Retrieval 7.5 (2014): 343-469.
[2] Bast, Hannah, Björn Buchhold, and Elmar Haussmann. “Semantic search on text and knowledge bases.” Foundations and Trends® in Information Retrieval 10.2-3 (2016): 119-271.
[3] https://github.com/YueHub/Answer
[4] https://www.jianshu.com/p/0293a2f605af
[5] 许坤,冯岩松,赵东岩,陈立伟,邹磊.面向知识库的中文自然语言问句的语义理解[J].北京大学学报(自然科学版),2014,50(01):85-92.