基于机器学习的工控安全风险评估
1 引言
随着工业控制网络与企业信息网络的不断融合,工业控制系统的安全管理受到了重大的挑战。工控系统安全等级评估是安全管理的重要内容,传统的安全等级评估方法主要有故障树分析法、层次分析法、模糊综合评判法、基于D-S证据理论的评估方法。传统的评估方法过多地依赖专家的经验,根据专家的经验确定评估模型的相关参数,模型的性能较差。近几年基于大规模数据分析的机器学习评估方法受到众多学者的关注,下面简要阐述。
2评估流程
工业控制系统安全等级评估的一般流程流程如下图所示。
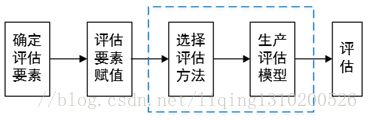
注:机器学习用于工控安全风险评估,可在上图中蓝色方框处改进。
3评估要素
工业控制系统安全风险评估要素大同小异,如下图所示。

4 评估模型
基于机器学习的安全等级评估方法把安全等级评估模型看作是一类分类模型,通过训练大量带标签的样本数据使用机器学习算法学习得到模型,下面简介5种,并列表进行对比。
4.1 基于SVM的评估模型
与传统的靠专家经验指定参数差别较大。支持向量机(Support VectorMachines, SVM)是一种通用的机器学习算法,它的一个显著特点是用满足Mercer条件的核函数代替原模式空间的矢量数积运算实现非线性变换,它的实质是将原模式空间变换至一个高维空间,使模式在高维空间中线性可分。
使用SVM进行评估的目标就是通过对训练样本的学习,求得评估函数f(x),该函数能在测试集上尽可能正确分类,从而实现对工业控制系统安全等级的分类预测。使用SVM求评估函数f(x)的模型结构如下图所示。

4.2 基于C4.5决策树评估模型
基于C4.5决策树分类算法是基于信息增益率构建决策树,在训练阶段和测试阶段都只要进行简单的比较,因此计算比较简单且对数据类别无要求。
相对于其他的机器学习分类算法, ISRAD(intelligent informationsecurity risk assessment based on decision tree algorithm , 基于决策树的智能信息安全风险评估方法)方法将C4.5决策树的分类方法应用于信息安全风险评估,对评估结果进行量化描述,在处理离散型数据时, ISRAD 方法在识别正确率和速度上独有优势。
ISRAD 方法利用定性和定量相结合的综合评估方法中的层次分析法对影响信息安全风险评估的要素进行分解 ,对层次分解后的评估要素及评估结果进行专家评分 , 用 C4.5决策树对评分得到的数据进行训练与测试。基于C4. 5决策树的分类算法对数据分布无任何要求, 其信息安全风险评估方法具有良好的发展前景 ,兼有较高的实用价值 ,可以在实际的风险评估工作中广泛应用。
4.3 基于 BP 神经网络评估模型
应用BP(Back Propagation,反向传播)网络进行风险评估的基本原理是: 把用于描述评估的各风险因素的风险等级作为神经网络的输入向量, 将对系统的风险评估值作为神经网络的输出。使用网络前, 用一些传统方法评估取得成功的系统样本训练这个网络, 使它所特有的权值系数值经过自适应学习后得到正确的内部关系, 训练好的神经网络便可作为风险评估的有效工具了。
反向传播神经网络(Back Propagation Neural Network)是目前最成熟, 应用最广泛的人工神经网络之一, 其基本的网络是三层前馈网络。包括输入层、隐含层、输出层。对于输入信号, 要先向前传播到隐含节点,经过函数作用后, 再把隐含节点的输出信息传递到输出节点,最后得到输出变量结果, 神经元节点函数通常取为 S 型函数。BP 网可以实现从输入到输出的任意复杂的非线性映射关系,并具有良好的泛化能力, 能够完成复杂模式识别的任务。 BP 网的典型结构如图 5所示。

算法的学习过程由正向传播过程和反向传播过程组成, 在前一个过程中, 输入信息从输入层经隐含单元逐层处理, 并传向输出层, 每一层神经元的状态只影响下一层的神经元状态。如果在输出层不能得到期望的输出, 则转入反向传播, 将误差信号沿原来的连接通路返回, 通过修改各层神经元的权值, 使得误差信号最小。
4.4 基于朴素贝叶斯评估模型
朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。朴素贝叶斯算法成立的前提是各属性之间互相独立。当数据集满足这种独立性假设时,分类的准确度较高,否则可能较低。核心算法为贝叶斯公式:
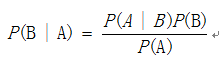
换个表达形式就会明朗很多,如下:

4.5 基于KNN评估模型
KNN(K Nearest Neighbor)算法,又称K邻近算法,kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。KNN算法模型如下图所示。

5 五种模型优缺点
针对上文5种方法,优缺点对比如下表所示。
评估模型 |
优点 |
缺点 |
SVM |
主观性小 对小样本适应性强 可用于线性/非线性分类 |
计算次数多 对参数和核函数的选择比较敏感 |
C4.5决策树 |
计算简单,易于理解 对数据类别无要求 准确率较高 |
构造树时需对数据集多次扫描和排序,算法效率低 数据量较大时,不易求解 |
BP网络 |
避免主观性、简单性 结果更有效客观 |
选取样本数据量有限 |
朴素贝叶斯 |
对小规模的数据表现很好 适合多分类任务 |
对输入数据的表达形式很敏感 |
KNN |
思想简单,理论成熟 可用于非线性分类 对数据类别无要求 |
计算量大 样本不平衡问题 需要大量的内存 |