使用Python requests和BeautifulSoup库爬取去哪儿网
功能说明:爬取去哪儿网城市下面若干条景点详细信息并将数据导入Excel表(使用xlwt库)
爬取去哪儿网的教程参考自 https://blog.csdn.net/gscsd_t/article/details/80836613
xlwt库使用方法参考自: https://my.oschina.net/dddttttt/blog/466103
第一次学爬虫,代码可能写得不太好,注释比较详细,勉强能看吧....
爬取景点的程序大致是参考上面教程的,只不过我自己增加了一些爬取的数据,改了下爬取范围,然后那个教程里面是把爬取的数据写到mysql数据库里,我这里是写到excel表格中。
上面教程已经把爬虫过程说的比较清楚了,这里再简单叙述一遍补充下,顺便加深下印象(下面是爬取结果)
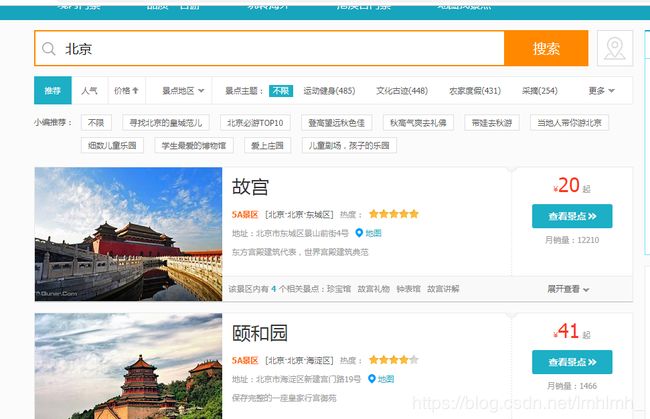
上图:去哪儿网北京景点截图
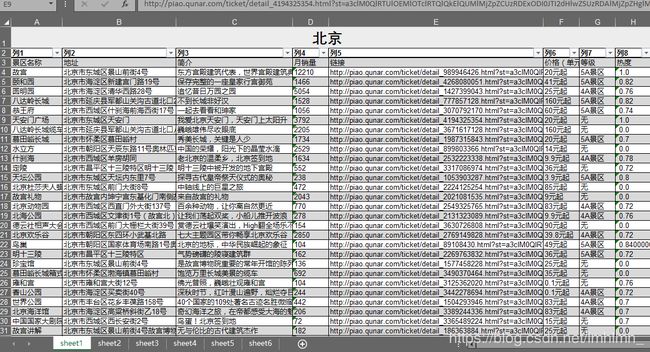
上图:爬取结果(表格的样式是我为了好看手动加的,代码里并没有,要想有的话可以用xlwt来设置)
下面开始教程。
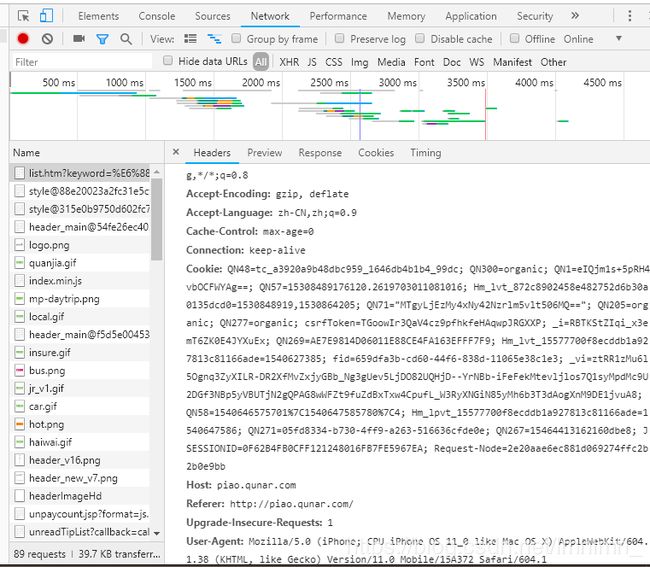
先去http://piao.qunar.com/ticket/list.htm?keyword=%E6%88%90%E9%83%BD®ion=%E6%88%90%E9%83%BD&from=mpshouye_hotcity,或者其它任意一个城市页面里,打开调试工具,刷新,查看第一个请求的html页面,点开看里面的请求头,
把User-Agent那段复制粘贴下来,当做python请求的header,这样就能伪装成浏览器访问服务器,绕过最简单的一个反爬虫机制。
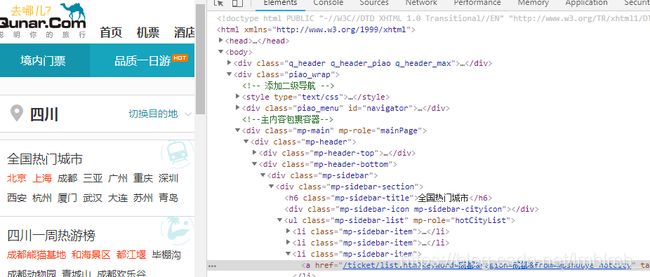
要爬取的是北京,上海,成都,三亚等若干个热门城市。首先需要获取它们的url,每个城市都是一个li标签,里面的a标签对于的href属性就能拿到url中的地址,再拼接上去哪儿的主机名就是完整url,然后一个for循环遍历每个城市进行解析。
特别注意:‘keyword=成都®ion=成都’这部分python获取到后在控制台打印变成了keyword=成都®ion=成都,估计可能是因为有些特殊符号编码的问题,比如&会编码成& 不过具体我也不太懂,所以这里就直接用字符串替换把®替换回去了。

点开某一个景点比如成都,滑动到最下面打开浏览器的开发工具,选中任意页码,就出现上图信息,可以看到,每一页的信息封在类似http://piao.qunar.com/ticket/list_%E6%88%90%E9%83%BD_%E6%88%90%E9%83%BD.html?from=mpshouye_hotcity&page=5 的url中,最后参数的page就代表页码,所以如果需要前5页数据,就for循环5次,每次url修改page的值即可得到对于页面地址,然后再去解析每页数据即可
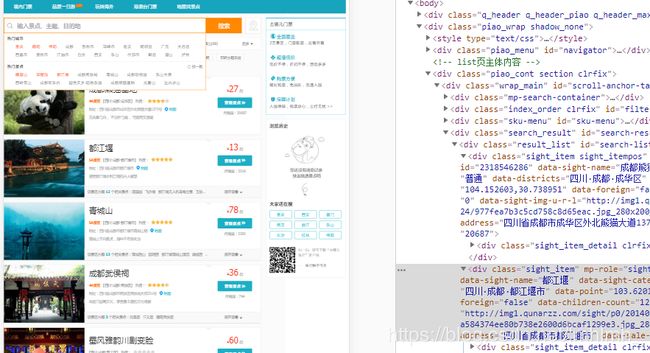
如上图,每一个景点都是一个class为sight_item的div标签,所以直接用beautifulSoup的find_all就可以查找到所有对应标签, 再一个for循环处理每个景点sight,再用类似的方法去看每个景点想爬的信息在什么标签下面直接去取就是。
最后用xlwt提供的write(rowIndex,colIndex,value),write_merge(rowTop,bottomTop,leftCol,rightCol,value)来往excel中写数据即可。具体用法看下手册就是,就那么几个API比较简单。
import requests
import xlwt
from bs4 import BeautifulSoup
# 解析首页每个城市
def parseAllCities(url):
html = requests.get(url,headers=headers).text
bs = BeautifulSoup(html)
cities = bs.find_all('li',class_='mp-sidebar-item') # 所有城市标签
cities = cities[:cityNum] # 取前3个城市(北京,上海,成都)
print('城市检验:',cities)
global currentCityIndex
for city in cities:
currentCityIndex = currentCityIndex + 1
global currentRowIndex
currentRowIndex = 2
cityName = city.a.string # 城市名
print('城市名校验:',cityName)
cityUrl = 'http://piao.qunar.com' + city.a.get('href') # 获取不含主机名的url
cityUrl = cityUrl.replace('®','®') # 避免转义
print(cityName,':\n')
global currentSheet
currentSheet = workBook.add_sheet('sheet' + str(currentCityIndex),cell_overwrite_ok=True) # 创建sheet
currentSheet.write_merge(0,0,0,7,cityName) # 合并单元格,填写城市名
# 填写表头(景区名称,地址,简介,月销量,链接...)
tableList = ['景区名称','地址','简介','月销量','链接','价格(单元:元)','等级','热度']
for i,val in enumerate(tableList):
currentSheet.write(1,i,val)
parseSingleCity(cityName,cityUrl)
print('\n\n\n')
# 解析每个单一的城市(解析多页)
def parseSingleCity(cityName,cityUrl):
# 解析城市前5页内容
global pageSize
for i in range(1,1+pageSize):
pageUrl = cityUrl + '&page=' + str(i)
print('第%d页:'%(i))
print('网址::', pageUrl)
parsePageInfo(pageUrl) # 解析具体信息
# 解析每一页的具体信息
def parsePageInfo(pageUrl):
html = requests.get(pageUrl,headers=headers).text
bs = BeautifulSoup(html)
sightList = bs.find_all('div',class_='sight_item') # 所有景点信息
# 遍历每个景点
for sight in sightList:
sightName = sight.find_all('a',class_='name')[0].string # 景区名
# 景区等级,有些景区无等级所以可能异常
try:
sightLevel = sight.find_all('span',class_='level')[0].string
except:
sightLevel = '无'
sightAddress = sight.find_all('p',class_='address')[0].span.string[3:] # 地址,去掉'地址'二字
sightDesc = sight.find_all('div',class_='intro')[0].string # 景区介绍
# 获取景区最低价格
try:
sightPrice = sight.find_all('span',class_='sight_item_price')[0].em.string + '元起'
except:
sightPrice = '免费'
# 获取月销量
try:
sightNum = sight.find_all('span',class_='hot_num')[0].string
except:
sightNum = 0
# 获取景区热度
sightStarLevel = sight.find_all('span',class_='product_star_level')[0].text[2:]
# 获取景区详细页Url
sightDetailUrl = sight.find_all('a',class_='sight_item_do')[0].get('href')
baseUrl = 'http://piao.qunar.com'
sightDetailUrl = baseUrl + sightDetailUrl
# 打印结果
print('{0},{1},{2},{3},{4},{5},{6}'.format(sightName,sightAddress,sightDesc,sightNum,sightDetailUrl,sightPrice,sightLevel))
# 结果导入excel
tableList = [sightName,sightAddress,sightDesc,sightNum,sightDetailUrl,sightPrice,sightLevel,sightStarLevel]
global currentSheet
global currentRowIndex
for i,val in enumerate(tableList):
currentSheet.write(currentRowIndex,i,val) # 填写每一行数据
currentRowIndex = currentRowIndex + 1
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36'
}
cityNum = 6 # 查询的城市数
pageSize = 10 # 查询的页数
startUrl = 'http://piao.qunar.com/'
currentCityIndex = 0 # 当前处理的城市下标
currentRowIndex = 2 # 当前在excel中的行号
workBook = xlwt.Workbook() # 创建excel表格
currentSheet = None
print('开始')
parseAllCities(startUrl)
workBook.save('testPy.xls')