编译原理项目--比特大战
1.介绍
1.1游戏简介

1.2游戏的策略

1.3问题的描述

1.项目设计
2.1设计目标
这里设计了一个编译语言称作C-Minus(或简称为C-),这是一种适合编译器设计方案的语言,它比TINY语言更复杂,包括函数和数组。本质上它是C的一个子集,但省去了一些重要的部分,因此得名。首先,我们列出了语言惯用的词法,包括语言标记的描述。其次,给出了每个语言构造的BNF描述。同时还有相关语义的英语描述,包括语言标记的表述,再者给出了C-的几个示例程序。最后生成目标可执行代码(汇编代码)。
2.2项目环境
2.2.1开发与运行平台
Windows
2.2.2开发工具
VC6.0、Masm6.15以上版本
2.2.3项目设计模型
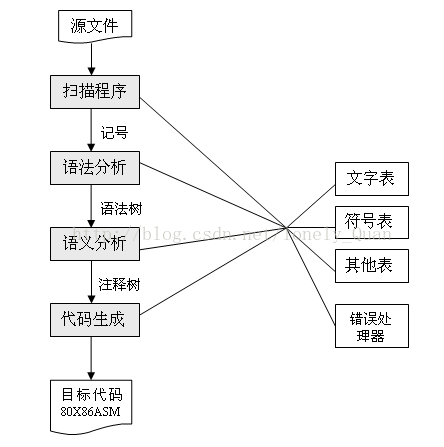
图1编译器的阶段
(1)扫描程序(scanner)
在这个阶段编译器实际阅读源程序(通常以字符流的形式表示)。扫描程序执行词法分析(Lexical analysis):它将字符序列收集到称作记号(token)的有意义单元中,记号同自然语言,如英语中的字词相似。因此可以认为扫描程序执行与拼写相似的任务。
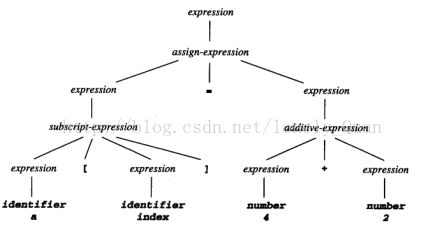
例如在下面的代码行(它可以是C程序的一部分)中:
a [index] = 4 + 2
这个代码包括了12个非空字符,但只有8个记号:
a 标识符
[ 左括号
i n d e x 标识符
] 右括号
= 赋值
4 数字
+ 加号
2 数字
每一个记号均由一个或多个字符组成,在进一步处理之前它已被收集在一个单元中。
(2)语法分析程序(parser)
语法分析程序从扫描程序中获取记号形式的源代码,并完成定义程序结构的语法分析(syntax analysis),这与自然语言中句子的语法分析类似。语法分析定义了程序的结构元素及其关系。通常将语法分析的结果表示为分析树(parse tree)或语法树(syntax tree)。
例如,还是那行C代码,它表示一个称为表达式的结构元素,该表达式是一个由左边为下标表达式、右边为整型表达式的赋值表达式组成。这个结构可按下面的形式表示为一个分析树:
(1)语义分析程序(semantic analyzer)
程序的语义就是它的“意思”,它与语法或结构不同,程序的语义确定程序的运行,但是大多数的程序设计语言都在执行之前被确定而不易由语法表示和由分析程序分析的特征。这些特征被称作静态语义(staticsemantic),而语义分析程序的任务就是分析这样的语义(程序的“动态”语义具有只有在程序执行时才能确定的特性,由于编译器不能执行程序,所以它不能由编译器来确定)。一般的程序设计语言的典型静态语义包括声明和类型检查。由语义分析程序计算的额外信息被称为属性(attribute),它们通常是作为注释或“装饰”增加到树中(还可以将属性添加到符号表中)。
(2)代码生成器(codegenerator)
代码生成器得到中间代码(IR),并生成目标机器的代码,尽管大多数编译器直接生成目标代码,但是为了便于理解,本项目用汇编语言来编写目标代码。正是在编译的这个阶段,目标机器的特性成为了主要因素。当它存在与目标机器时,使用指令不仅是必须的而且数据的形式表示也起着重要的作用。
3.项目文件定义
3.1文件描述
C-编译器包括以下的文件,(为了包含而)把它的头文件放在左边,他的代码文件放在右边:
globals.h main.cpp
util.h util.cpp
scan.h scan.cpp
parse.h parse.cpp
symtab.h symtab.cpp
analyze.h analyse.cpp
code.h code.cpp
cgen.h cgen.cpp
这些文件的源代码都按顺序列在附录中。任何代码文件都包含globals.h头文件,它包括了数据类型的定义和整个编译器均使用的全程变量。main.cpp文件包括运行编译器的主程序,它还分配和初始化全程变量。其他的文件则包含了头/代码文件对、在头文件中给出了外部可用的函数原型以及在相关代码文件中的实现(包括静态局部函数)。scan、parse、analyze和cgen文件与图1中的扫描程序、分析程序、语义分析程序和代码生成器各阶段完全相符。util文件包括了实用程序函数,生成源代码(语法树)的内部表示和显示列表与出错信息均需要这些函数。symtab文件包括执行与C-应用相符的符号表的杂凑表。code文件包括用于依赖目标机器的代码生成的实用程序。图1还缺少一些其他部分:没有单独的错误处理器或
文字表且没有优化阶段;没有从语法树上分隔出来的中间代码;另外,符号表只与语义分析程序和代码生成器交互。
虽然这些文件中的交互少了,但是编译器仍有4遍:第1遍由构造语法树的扫描程序和分析程序组成;第2遍和第3遍执行语义分析,其中第2遍构造符号表而第3遍完成类型检查;最后一遍是代码生成器。在main.cpp中驱动这些遍的代码十分简单。当忽略了标记和编辑时,它的中心代码如下:
syntaxTree=parse();
buildSymtab(syntaxTree);
typeCheck(syntaxTree);
codeGen(syntaxTree,codefile);
为了灵活起见,我们还编写了条件编译标志,以使得有可能创建出一部分的编译器。如下是该标志及其效果:
标志 设置效果 编译所需文件(附加)
NO_COMMAND 创建不通过命令就可以运行的编译器
NO_PARSE 创建只扫描的编译器 globals.h,main.cpp,util.h,util.cpp, scan.h,scan.cpp,parse.h,parse.cpp
NO_ANALYZE 创建只分析和扫描的编译器 parse.h,parse.cpp
NO_CODE 创建执行语义分析, symtab.h,symtab.cpp,analyze.h,
但不生成代码的编译器 analyze.cpp
尽管这个C-编译器设计得有些不太实际,但却单个文件与阶段基本一致的好处,在VC6.0及以上版本的开发工具中可以编译运行。注意在编译运行期间可以适当修改源代码main.cpp文件,在编辑列表的信息中有若干选项,以下的标志均可用:
标志 设置效果
EchoSourse 将C-源程序回显到带有行号的列表
TraceScan 当扫描程序识别出记号时,就显示每个行号的信息
TraceParse 将语法树以线性化格式显示
TraceAnalyze 显示符号表和类型检查的小结信息
TraceCode 打印有关代码文件的代码生成跟踪注释
此外,还有一些测试用例文件:
名称 效果
T1.txt T1的策略(永远合作)测试用例
T2.txt T2的策略(随机)测试用例
T3.txt T3的策略(针锋相对)测试用例
T4.txt T4的策略(老实人探测器)测试用例
T5.txt T5的策略(//永不原谅)测试用例
test.txt 排序测试用例
fun1.txt 得分测试用例
comp.txt 项目要求实现的程序代码
4.详细设计过程
4.1 C-惯用的词法
4.1.1下面是语言的关键字:
else if int return void while
所有的关键字都是保留字,并且必须是小写。
4.1.2下面是专用符号:
+ - * / < <= > >= == !== ; , () [] {} /**/ //
4.1.3其他标记是ID和NUM,通过下列正则表达式定义:
ID=letterletter*
NUM=digitdigit*
letter=a|..|z|A|..|Z
digit=0|..|9
小写和大写字母是有区别的。
4.1.4空格由空白、换行符和制表符组成。空格通常被忽略,除了它必须分开ID、NUM关键字。
4.1.5注释用通常的C语言符号/*...*/围起来。注释可以放在任何空白出现的位置(即注释不能放在标记内)上,且可以超过一行。注释不能嵌套。
4.2 C-的语法和语义
C-的BNF语法如下:
1.program→declaration-list
2.declaration-list→declaration-listdeclaration|declaration
3.declaration→var-declaration|fun-declaration
4.var-declaration→type-specifierID;|type-specifierID[NUM];
5.type-specifier→int|void
6.fun-declaration→type-specifierID(params)|compound-stmt
7.params→params-list|void
8.param-list→param-list,param|param
9.param→type-specifierID|type-specifierID[]
10.compound-stmt→{local-declaration sstatement-list}
11.local-declarations→local-declarationsvar-declaration|empty
12.statement-list→statement-liststatement|empty
13.statement→expression-stmt|compound-stmt|selection-stmt|iteration-stmt|return-stmt
14.expression-stmt→expression;|;
15.selection-stmt→if(expression)statement|if(expression)statementelse statement
16.iteration-stmt→while(expression)statement
17.return-stmt→return;|return expression;
18.expression→var=expression|simple-expression
19.var→ID|ID[expression]
20.simple-expression→additive-expression relopadditive-expression|additive-expression
21.relop→<=|<|>|>=|==|!=
22.additive-expression→additive-expression addop term|term
23.addop→+|-
24.term→term mulop factor|factor
25.mulop→*|/
26.factor→(expression)|var|call|NUM
27.call→ID(args)
28.args→arg-list|empty
29.arg-list→arg-list,expression|expression
30.read→ready(int)
31.write→write(int)
32.random→random(int)
对以上每条文法规则,给出了相关语义的简短解释。
1.program→declaration-list
2.declaration-list→declaration-listdeclaration|declaration
3.declaration→var-declaration|fun-declaration
程序由声明的列表(或序列)组成,声明可以是函数或变量声明,顺序是任意的。至少必须有一个声明。接下来是语义限制(这些在C中不会出现)。所有的变量和函数在使用前必须声明(这避免了向后backpatching引用)。程序中最后的声明必须是一个函数声明,名字为main。注意,C-缺乏原型,因此声明和定义之间没有区别(像C一样)。
4.var-declaration→type-specifierID;|type-specifierID[NUM];
5.type-specifier→int|void
变量声明或者声明了简单的整数类型变量,或者是基类型为整数的数组变量,索引范围从0到NUM-1。注意,在C-中仅有的基本类型是整型和空类型。在一个变量声明中,只能使用类型指示符int。void用于函数声明(参见下面)。也要注意,每个声明只能声明一个变量。
6.fun-declaration→type-specifierID(params)compound-stmt
7.params→param-list|void
8.param-list→param-list,param|param
9.param→type-specifierID|type-specifierID[]
函数声明由返回类型指示符、标识符以及在圆括号内的用逗号分开的参数列表组成,后面跟着一个复合语句,是函数的代码。如果函数的返回类型是void,那么函数不返回任何值(即
是一个过程)。函数的参数可以是void(即没有参数),或者一列描述函数的参数。参数后面跟
着方括号是数组参数,其大小是可变的。简单的整型参数由值传递。数组参数由引用来传递
(也就是指针),在调用时必须通过数组变量来匹配。注意,类型“函数”没有参数。一个函数参数的作用域等于函数声明的复合语句,函数的每次请求都有一个独立的参数集。函数可以是递归的(对于使用声明允许的范围)。
10.compound-stmt→{local-declarations statement-list}
复合语句由用花括号围起来的一组声明和语句组成。复合语句通过用给定的顺序执行语句序列来执行。局部声明的作用域等于复合语句的语句列表,并代替任何全局声明。
11.local-declarations→local-declarationsvar-declaration|empty
12.statement-list→statement-liststatement|empty
注意声明和语句列表都可以是空的(非终结符empty表示空字符串,有时写作。)
13.statement→expression-stmt
|compound-stmt
|selection-stmt
|iteration-stmt
|return-stmt
14.expression-stmt→expression;|;
表达式语句有一个可选的且后面跟着分号的表达式。这样的表达式通常求出它们一方的结
果。因此,这个语句用于赋值和函数调用。
15.selection-stmt→if(expression)statement
|if(expression)statement else statement
if语句有通常的语义:表达式进行计算;非0值引起第一条语句的执行;0值引起第二条语
句的执行,如果它存在的话。这个规则导致了典型的悬挂else二义性,可以用一种标准的方法解决:else部分通常作为当前if的一个子结构立即分析(“最近嵌套”非二义性规则)。
16.iteration-stmt→while(expression)statement
while语句是C-中唯一的重复语句。它重复执行表达式,并且如果表达式的求值为非0,则执行语句,当表达式的值为0时结束。
17.return-stmt→return;|returnexpression;
返回语句可以返回一个值也可无值返回。函数没有说明为void就必须返回一个值。函数
声明为void就没有返回值。return引起控制返回调用者(如果它在main中,则程序结束)。
18.expression→var=expression|simple-expression
19.var→ID|ID[expression]
表达式是一个变量引用,后面跟着赋值符号(等号)和一个表达式,或者就是一个简单的表达式。赋值有通常的存储语义:找到由var表示的变量的地址,然后由赋值符右边的子表达式进行求值,子表达式的值存储到给定的地址。这个值也作为整个表达式的值返回。var是简单的(整型)变量或下标数组变量。负的下标将引起程序停止(与C不同)。然而,不进行下标越界检查。var表示C-比C的进一步限制。在C中赋值的目标必须是左值(l-value),左值是可以由许多操作获得的地址。在C-中唯一的左值是由var语法给定的,因此这个种类按照句法进行检查,代替像C中那样的类型检查。故在C-中指针运算是禁止的。
20.simple-expression→additive-expressionrelopadditive-expression
|additive-expression
21.relop→<=|<|>|>=|==|!=
简单表达式由无结合的关系操作符组成(即无括号的表达式仅有一个关系操作符)。简单表达式在它不包含关系操作符时,其值是加法表达式的值,或者如果关系算式求值为ture,其值
为1,求值为false时值为0。
22.additive-expression→additive-expression addop term|term
23.addop→+|-
24.term→term mulop factor|factor
25.mulop→*|/
加法表达式和项表示了算术操作符的结合性和优先级。符号表示整数除;即任何余数都被截去。
26.factor→(expression)|var|call|NUM
因子是围在括号内的表达式;或一个变量,求出其变量的值;或者一个函数调用,求出函数的返回值;或者一个NUM,其值由扫描器计算。数组变量必须是下标变量,除非表达式由单个ID组成,并且以数组为参数在函数调用中使用(如下所示)。
27.call→ID(args)
28.args→arg-list|empty
29.arg-list→arg-list,expression|expression
函数调用的组成是一个ID(函数名),后面是用括号围起来的参数。参数或者为空,或者由逗号分割的表达式列表组成,表示在一次调用期间分配的参数的值。函数在调用之前必须声明,声明中参数的数目必须等于调用中参数的数目。函数声明中的数组参数必须和一个表达式匹配,这个表达式由一个标识符组成表示一个数组变量。最后,上面的规则没有给出输入和输出语句。在C-的定义中必须包含这样的函数,因为与C不同,C-没有独立的编译和链接工具;因此,考虑两个在全局环境中预定义的函数,好像它们已进行了声明:
void input(int x){...}
void output(int x){...}
intrandom(int x){...}
input函数接受一个整形参数从标准输入设备(通常是键盘)返回一个整数值。output函数接受
一个整型参数,其值和一个换行符一起打印到标准输出设备(通常是屏幕)。random函数接受一个整形参数,其值返回一个0-x-1的一个随机数。
5.简要的用户使用说明
5.1测试过程
用户可以根据喜好在主函数(main.cpp)上修改标志,参考3.1。可以使用测试用例,也可以根据问法规则自己编写程序代码。现在举一个测试(1.3的B3要求)用例说明情况。
5.1.1程序(comp.txt)代码如下:
//永远合作
int T1()
{
return 1;
}
//随机
int T2()
{
if(random(4)==3)
return0;
else
return1;
}
// 针锋相对
intT3(int now3,int b3[])
{
if(now3==0)return 1;
else return b3[now3-1];
}
//老实人探测器
intT4(int now4,int b4[])
{
if(now4==0)return 1;
else{
if(random(10)==9)return0;
elsereturn b4[now4-1];
}
}
//永不原谅
intT5(int now5,int b5[])
{
if(now5==0)return 1;
else
{
while(now5>=0)
{
now5=now5-1;
if(b5[now5]==0)
{return 0;}
}
}
return 1;
}
//得分测试用例
/*
根据pos返回是A的结果还是B的结果
*/
intscore(int pos,int A,int B)
{
if(A==0){
if(B==1){
if(pos==1)return 5;
else return 0;
}elsereturn 1;
}
if(A==1){
if(B==0){
if(pos==1)return 0;
else return 5;
}elsereturn 3;
}
}
voidmain(void)
{
int n;
int sum[5];//存放5种策略的得分总和
int round1[200];//保存每次的选择
int round2[200];
int i;
int j;
int temp1;
int temp2;
n=200;
//T1和T2策略的比较
i=0;
while(i<200)
{
round1[i]=T1();
temp1=round1[i];
round2[i]=T2();
temp2=round2[i];
//功能不完善,只能这样传参
sum[0]=sum[0]+score(1,temp1,temp2);
sum[1]=sum[1]+score(0,temp1,temp2);
i=i+1;
}
//T1和T3策略的比较
i=0;
while(i<200)
{
round1[i]=T1();
temp1=round1[i];
round2[i]=T3(i,round1);
temp2=round2[i];
sum[0]=sum[0]+score(1,temp1,temp2);
sum[2]=sum[2]+score(0,temp1,temp2);
i=i+1;
}
//T1和T4策略的比较
i=0;
while(i<200)
{
round1[i]=T1();
temp1=round1[i];
round2[i]=T4(i,round1);
temp2=round2[i];
sum[0]=sum[0]+score(1,temp1,temp2);
sum[3]=sum[3]+score(0,temp1,temp2);
i=i+1;
}
//T1和T5策略的比较
i=0;
while(i<200)
{
round1[i]=T1();
temp1=round1[i];
round2[i]=T5(i,round1);
temp2=round2[i];
sum[0]=sum[0]+score(1,temp1,temp2);
sum[4]=sum[4]+score(0,temp1,temp2);
i=i+1;
}
//T2和T3策略的比较
i=0;
while(i<200)
{
round1[i]=T2();
temp1=round1[i];
round2[i]=T3(i,round1);
temp2=round2[i];
sum[1]=sum[1]+score(1,temp1,temp2);
sum[2]=sum[2]+score(0,temp1,temp2);
i=i+1;
}
//T2和T4策略的比较
i=0;
while(i<200)
{
round1[i]=T2();
temp1=round1[i];
round2[i]=T4(i,round1);
temp2=round2[i];
sum[1]=sum[1]+score(1,temp1,temp2);
sum[3]=sum[3]+score(0,temp1,temp2);
i=i+1;
}
//T2和T5策略的比较
i=0;
while(i<200)
{
round1[i]=T2();
temp1=round1[i];
round2[i]=T5(i,round1);
temp2=round2[i];
sum[1]=sum[1]+score(1,temp1,temp2);
sum[4]=sum[4]+score(0,temp1,temp2);
i=i+1;
}
//T3和T4策略的比较
i=0;
while(i<200)
{
round1[i]=T3(i,round2);
temp1=round1[i];
round2[i]=T4(i,round1);
temp2=round2[i];
sum[2]=sum[2]+score(1,temp1,temp2);
sum[3]=sum[3]+score(0,temp1,temp2);
i=i+1;
}
//T3和T5策略的比较
i=0;
while(i<200)
{
round1[i]=T3(i,round2);
temp1=round1[i];
round2[i]=T5(i,round1);
temp2=round2[i];
sum[2]=sum[2]+score(1,temp1,temp2);
sum[4]=sum[4]+score(0,temp1,temp2);
i=i+1;
}
//T4和T5策略的比较
i=0;
while(i<200)
{
round1[i]=T4(i,round2);
temp1=round1[i];
round2[i]=T5(i,round1);
temp2=round2[i];
sum[3]=sum[3]+score(1,temp1,temp2);
sum[4]=sum[4]+score(0,temp1,temp2);
i=i+1;
}
//排序前得分
i=0;
while(i<5)
{
write(sum[i]);
i=i+1;
}
//分割线
write(00000);
//怕麻烦,只好用冒泡了
i=0;
while(i<(5-1))
{
j=0;
while(j<(5-i-1))
{
temp1=j+1;
if(sum[j]>sum[temp1])
{
temp2=sum[j];
sum[j]=sum[temp1];
sum[temp1]=temp2;
}
j=j+1;
}
i=i+1;
}
//排序后的得分
i=0;
while(i<5)
{
write(sum[i]);
i=i+1;
}
}
5.1.2 修改标志
首先要知道词法分析,语法分析,语义分析的结果是回显到dos界面的,如果用户想改变输出流,可以自己编写代码。而最后的目标代码是生成.asm文件,这个是汇编文件,生成的汇编文件可以在masm6.15以上的版本运行。修改标志主要参照3.1的标志效果修改标志即可。首先将NO_COMMAND标志设为TRUE不采用命令行模式,然后在主函数添加comp.txt,标志将comp.txt进行编译,如下图所示:

5.1.2.1 词法分析
只需要将NO_PARSE设置为TRUE,就可以进行词法分析了,当然,如果在词法分析过程中出现不能识别的字符会显示在dos界面,如果没有错误则表示词法分析完毕。如果用户想查看词法分析的结果,需要将标志TraceScan设置为TRUE。显示结果如下图所示:

5.1.2.2 语法分析
要进行语法分析,首先将标志为NO_PARSE为FALSE。其实无论NO_PARSE设置为TRUE还是FALSE都是会执行词法分析的,但是为了保留TINY编译器的编程风格,所以保存了标志NO_PARSE。但是要进行语法分析,NO_PARSE必须设置为FALSE。如果在语法分析过程中出现不能识别的字符或者语法错误会显示在dos界面,这满足了1.3的B2要求(实现对这个语言的语法分析。定义相应的语法树,并且可以输出语法分析的结果。当出现可能的输入错误时,可以指出出错的位置和可能的错误原因),如果没有错误则表示词法分析完毕。如果用户想查看语法分析的结果,需要将标志TraceParse设置为TRUE。显示结果如下图所示:

5.1.2.3语义分析
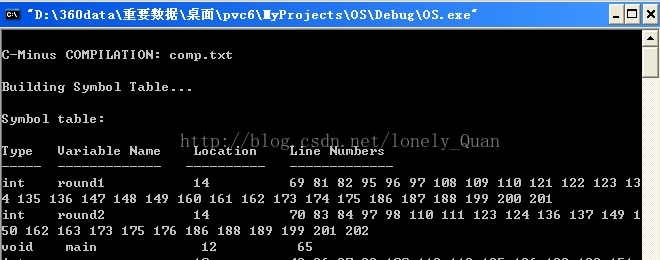
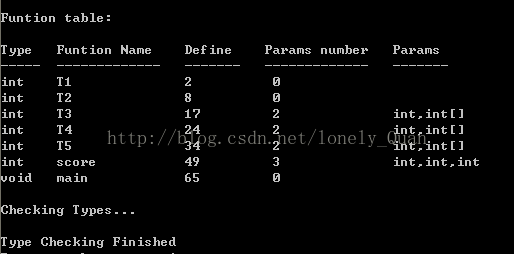
语义分析,主要是生成符号表,需要将NO_ANALYZE设置为FALSE,如果程序在前面的语法分析中没有出现错误(Error)就可以进行语义分析。设置TraceAnalyze为TRUE就可以查看语义分析的结果了。语义分析的结果是显示两个部分,第一部分是显示用户设计的程序所用到的变量和函数符号表,分别是:变量的类型(int/void),变量的名字,变量内存的位置,变量出现的位置。第二部分是函数表,这个函数表会显示函数的类型(int/void),函数的名字,函数定义的位置,函数的参数数量和参数的类型(变量/数组),显示结果如下:
5.1.2.4代码生成
代码主要生成的是汇编代码,需要将NO_CODE标志位设置为FALSE就可以了,如果程序在前面的语法分析中没有出现错误(Error)就可以进行代码生成。代码生成这部分的设置思想是没有直接用Symbol Table和Funtion Table来获得数据的,当时是考虑到如果用户直接跳过语义分析而进行代码生成,这样是会出现错误的,所以在设计的时候没有用到语义分析的数据,而是重新在语法树上遍历。如无意外就可以生成目标代码了,当然,如果用户想查看自己的目标代码,需要TraceCode设置为TRUE。此时就会看到“***.asm文件”。
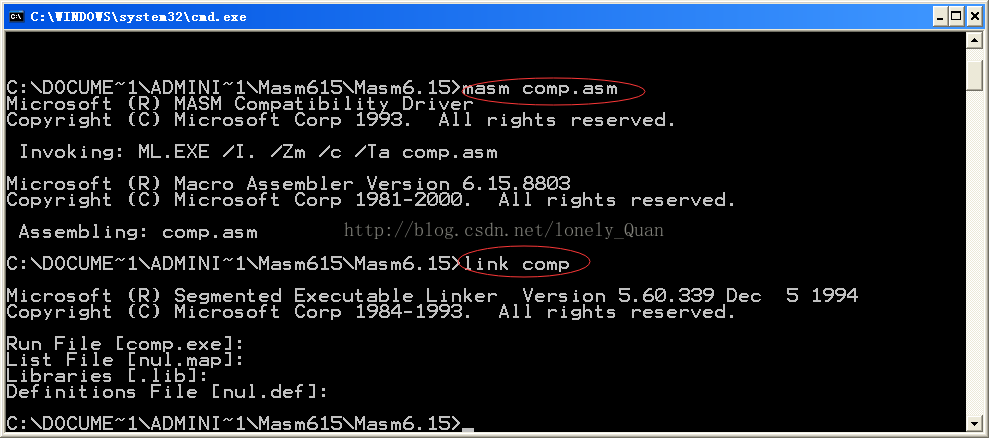
5.2 编译汇编代码
编译汇编代码需要第三方的编译工具masm,注意masm的版本是需要6.15以上。首先将汇编代码“***.asm”复制到masm的文件夹中,然后在电脑左下角开始→运行中输入cmd,用cd命令进入到masm的文件夹,接下来只需要编译链接运行即可,命令如下:
masm comp.asm
link comp
comp.exe

5.3结果分析
从结果来看,可以知道在模拟这些策略两两之间的N回合(n=200)的比特大战中,从所有对战的得分结果来看,永远合作和永不原谅是得分比较高的。可以知道好的策略不易被淘汰。当然,实验结果有一定的误差,因为可以知道,当永远合作和永不原谅这两种策略在进行博弈的时候,很明显是一个双赢的局面,这时候双倍的比分都会增多,用户可以自己编写一个永不合作的策略进行博弈,相信永远合作的比分就会拉低。用户也可以自己编写不同的策略来进行博弈,只需要注意文法规则和下文的风险预测即可。
6 风险预测
以前经常吐槽VC6.0不好用,但是当真正设计一款编译器的时候才发现这也不是简单的事情,也存在很多的bug。闲话不说,这模块需要说明一下用户在编写自己程序的时候需要注意的事项。
一、这是一款模仿C的设计语言,所以属性C语言的用户可以很快上手,但是这也只是一款模仿C的设计语言,所以有很多C的规则不通用,例如在定义变量的时候不能赋值,则int i=100;是错误的。没有for语句,所以用户在看测试用例的时候无论是排序还是其他都是用while实现的,当然,有时间的话可以自己扩充问法。二、也是最重要的一点,就是函数传参的问题,如果用户需要在函数中定义变量,就不能进行传参,如果用户需要传参,就不能在函数中定义变量。(虽然我也不知道怎么回事,当时在win7下用虚拟机是可以实现传参和定义的,但是后来因为某些原因只好在win xp上实现,这时候已经不能进行传参和定义同时进行的,由于时间不足,还没有解决这一问题)。三、用数组的时候需要注意,会出现很多奇奇怪怪的问题的,应该是汇编的原因,本人对汇编也不是很懂,所以在数组的赋值和传参的过程都会出现一些问题。
7.系统的源代码
需要的请联系邮箱[email protected]