论文阅读《GeTrust: A guarantee-based trust model in Chord-based P2P networks》
-
摘要
P2P网络的去中心化、自治性以及匿名性吸引了越来越多的用户。然而,用户不加约束的行为使得为peer之间建立信任模型是很有必要的。大部分现有的信任模型基于推荐,然而具备有收敛慢、信任计算复杂度高、网络开销大等的缺陷。收到人类社交的启发,本文提出了针对基于Chord的P2P网络的基于担保的信任模型GeTrust。一个服务peer需要选择它的担保peers,这些担保peers要求给出声誉抵押,并将评价值最高的作为服务提供者。为了增大GeTrust的可用性以及防止恶意行为,我们也给出了激动机制与匿名信誉管理策略。
本文的主要工作如下:
- GeTrust模型,在担保节点的帮助下,请求的节点不需要使用全局推荐来评估服务节点,从而减少了计算和消息复杂性。
- 利用声誉抵押与激励机制来确保GeTrust的正常运行。
- 使得高声誉值的节点能够获取更可靠的服务,能够提高诚实节点的体验与加强网络可用性。
-
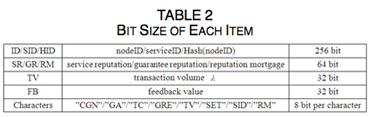
相关定义
- 服务节点与服务声誉:服务节点是在一个事务中提供服务的节点,服务声誉代表服务节点的信任度。每个节点在加入网络时的初始化服务声誉为0.5。
- 担保节点与担保声誉:担保节点为一个服务提供担保,担保声誉为担保节点的信任度。每个服务节点必须至少有一个担保节点。服务节点与担保节点都需要为它们的行为负责。
- 存档节点:管理服务声誉、担保声誉、对某个事务该负责的节点记录的节点。本文采用Chord-based声誉管理机制,所以每个节点都有可能成为存档节点。
- 请求节点:一个事务中请求服务的节点。在服务结束后,请求节点需要向存档节点对服务节点与担保节点进行反馈。
- 直接信任:请求节点根据历史事务记录对一个指定节点的信任评估。直接信任可分为服务直接信任与担保直接信任,分别针对服务节点与担保节点。直接信任存储在请求节点本地。
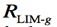 :判定一个节点是否有资格成为担保节点的标准:服务声誉的阈值。值在区间(0.5,1]内。
:判定一个节点是否有资格成为担保节点的标准:服务声誉的阈值。值在区间(0.5,1]内。
假定mb为事务号,请求节点为i,服务节点为b,i对b的直接信任计算公式如下。其中![]() 为i对b的第k次反馈,值在区间[-1,1]内,
为i对b的第k次反馈,值在区间[-1,1]内,![]() 为时间衰减函数,使得最近的反馈占比更高。t0为第一次反馈,tk为第k次反馈。
为时间衰减函数,使得最近的反馈占比更高。t0为第一次反馈,tk为第k次反馈。
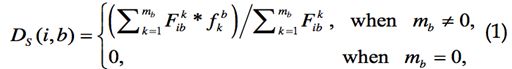
假定mg为事务号,请求节点i,担保节点g,i对g的直接信任计算公式如下。公式中的其他符号含义与计算类似于公式1。
-
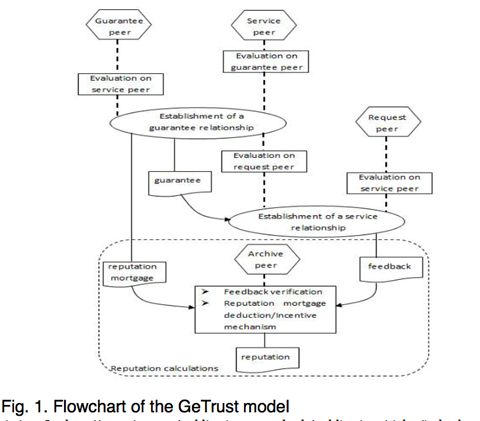
GeTrust
GeTrust的流程图包括以下三个方面:担保关系的建立、服务关系的建立以及声誉计算。在提供服务之前,担保关系需要首先确定,这一步需要担保节点与服务节点的相互评估。之后在担保节点的担保下,服务节点与请求节点相互评估以建立服务关系。在服务完成后,存档节点根据请求节点的反馈计算服务节点与担保节点的声誉,并更新记录。
-
担保关系建立前的评估
任何服务节点在提供服务前必须要有它自己的担保节点。申请一个好的担保节点有助于提高服务节点的声誉。在GeTrust中,每个节点维护两个担保节点列表:当前担保列表(current guarantee list,CGL)与备份担保列表(Backup guarantee list,BGL)。前者存储当前列表,后者备份担保节点信息。
考虑到查找担保节点的遍历性,我们使用一个转换函数将节点的IP转变为[1,L]之间一个整数,如r。之后通过一个安全hash函数来获取索引:![]() ,其中GID是一个数字化的前缀,用来帮助节点定位到担保节点的索引节点。将InodeID作为存储担保节点的索引信息的节点的nodeID。服务节点可以向索引节点查找HASH(GID+r)来获取担保节点。同时,我们还允许担保节点志愿担任某节点的担保节点。称志愿担任的节点为自推荐节点。当节点收到某节点的自推荐后,将自推荐节点加入BGL中。当服务节点确定由某节点担任担保节点时,将给自推荐节点发送一个担保应用,而同时自推荐节点的存档节点会通知两节点建立不需要评估的担保关系。这种方式对于刚加入网络的节点是有帮助的,因为这些节点的信誉还比较低。然而自推荐节点的信誉受损的风险也很大。
,其中GID是一个数字化的前缀,用来帮助节点定位到担保节点的索引节点。将InodeID作为存储担保节点的索引信息的节点的nodeID。服务节点可以向索引节点查找HASH(GID+r)来获取担保节点。同时,我们还允许担保节点志愿担任某节点的担保节点。称志愿担任的节点为自推荐节点。当节点收到某节点的自推荐后,将自推荐节点加入BGL中。当服务节点确定由某节点担任担保节点时,将给自推荐节点发送一个担保应用,而同时自推荐节点的存档节点会通知两节点建立不需要评估的担保关系。这种方式对于刚加入网络的节点是有帮助的,因为这些节点的信誉还比较低。然而自推荐节点的信誉受损的风险也很大。
在提供服务之前,服务节点b首先从BGL中找到他的担保节点。任何由b找到的担保节点都需要由b的存档节点确定有资格担任担保节点,并需要事先扣除担保节点在先前担保过程中所作出的声誉抵押。我们使用剩余担保声誉来代表一个新的担保关系下可用的担保声誉,这可通过以下式子进行计算:![]() 。其中
。其中![]() 为担保节点当前的担保声誉,
为担保节点当前的担保声誉,![]() 为第i次服务担保节点所需要扣除的担保声誉。只有当计算节点大于0时,该节点才有资格继续担任为担保节点。
为第i次服务担保节点所需要扣除的担保声誉。只有当计算节点大于0时,该节点才有资格继续担任为担保节点。
![]() 用来确定选中的担保节点是否足够的能力来担保当前服务。
用来确定选中的担保节点是否足够的能力来担保当前服务。![]() 为事务容量,能够用来防止节点利用一些小的事务累积的声誉来对大的事务进行欺骗,v为b所申请的担保节点数,
为事务容量,能够用来防止节点利用一些小的事务累积的声誉来对大的事务进行欺骗,v为b所申请的担保节点数,![]() 为第j个担保节点的剩余担保声誉,Rb为服务节点b的剩余服务声誉,计算公式如下:
为第j个担保节点的剩余担保声誉,Rb为服务节点b的剩余服务声誉,计算公式如下:![]() ,其中
,其中![]() 、
、![]() 与之前所表述的一致,
与之前所表述的一致,![]() 为第i次服务所填充的声誉。如果计算后得到的Rfill>0,则表示服务节点b还可以选择更好的担保节点,因此b将继续通过hash来查找更多的担保节点,反之若Rfill<=0,则b的存档节点向所有的担保节点发送担保应用。当没有足够的担保节点来保证Rfill<=0时,b使用自己的服务声誉来填充当前Rfill的差值,若不能填充,则b必须等待。
为第i次服务所填充的声誉。如果计算后得到的Rfill>0,则表示服务节点b还可以选择更好的担保节点,因此b将继续通过hash来查找更多的担保节点,反之若Rfill<=0,则b的存档节点向所有的担保节点发送担保应用。当没有足够的担保节点来保证Rfill<=0时,b使用自己的服务声誉来填充当前Rfill的差值,若不能填充,则b必须等待。
当担保节点收到针对b的担保应用后,担保节点的存档节点Dg需要首先检查:Dg所记录的所有担保节点中,b是否出现过大于等于两次的恶意服务,若出现则b存在于黑名单中,从而通知担保节点拒绝提供担保。若b的服务声誉大于阈值![]() 时,可以从黑名单中移除。若b不在黑名单中,Dg根据公式6、7来确定担保节点是否应该提供担保。具体地,Dg计算历史反馈相似度,计算过程为联合担保节点与b所共同执行过事务的服务节点的集合所作出的反馈。CSet(b,g)为b与g的共同服务节点集合。公式6通过余弦相似度来计算历史反馈相似度。根据计算出来的相似度,公式7可以计算出相对声誉Wb,这是用来评价担保节点对服务节点的信任度。如果Wb大于0,担保节点将接受担保,否则拒绝担保。注意自推荐节点会因为激励机制的存在而主动承担担保。
时,可以从黑名单中移除。若b不在黑名单中,Dg根据公式6、7来确定担保节点是否应该提供担保。具体地,Dg计算历史反馈相似度,计算过程为联合担保节点与b所共同执行过事务的服务节点的集合所作出的反馈。CSet(b,g)为b与g的共同服务节点集合。公式6通过余弦相似度来计算历史反馈相似度。根据计算出来的相似度,公式7可以计算出相对声誉Wb,这是用来评价担保节点对服务节点的信任度。如果Wb大于0,担保节点将接受担保,否则拒绝担保。注意自推荐节点会因为激励机制的存在而主动承担担保。


当担保关系成功建立之后,服务节点将所有的担保节点加入CGL与BGL。
-
声誉抵押
服务节点提供服务与担保节点提供担保都需要抵押声誉。信誉抵押从担保关系建立时开始记录,在节点切断担保关系(如意外掉线、主动放弃等等)或者服务节点提供了恶意的服务时将扣除声誉。

此外,公式8、9表明声誉值越高的节点在出错时受到的惩罚越大。
-
担保关系建立过程
担保关系建立过程如图2所示,b为服务节点,g为担保节点,Db与Dg为b与g的存档节点。整个过程使用了三种消息:Notify、Query、Reply,如表1所示。执行步骤如下:
- b想要提供服务,b首先从BGL中找担保节点,如果BGL不能提供足够的担保节点的话,从索引节点中查找新的节点。g是一个候选的担保节点。b通知Db:Notify(b,Db)=CGN|HIDb|IDg。
- Db在收到Notify之后,向Dg请求g的担保声誉与扣除了的声誉:Query(Dg,Db)=HIDg|RM。Dg将回复:
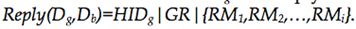
- Db计算g的剩余担保声誉,判断g是否有资格进行担保。若有资格,通知g与Dg:

- Dg在收到GA后,向Db请求获取b的声誉以及b的历史反馈节点的集合:
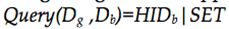 ,等待回复:
,等待回复: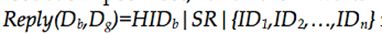
- Dg通过公式6、7计算相对声誉,若认为b有资格提供服务则发送:

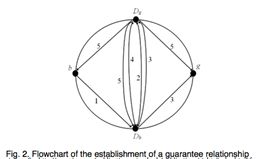

-
服务关系建立
服务关系指请求节点与服务节点关系的建立。
- 当请求节点a请求服务节点b提供服务时,b需要评估a以确定是否提供服务。
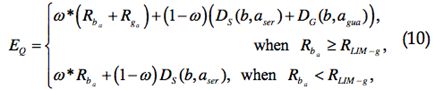
其中![]() 为声誉因子,m为a与p交互次数(包括服务以及担保)。m=0时
为声誉因子,m为a与p交互次数(包括服务以及担保)。m=0时![]() 。
。![]() 为a的服务声誉,
为a的服务声誉,![]() 为a的担保声誉,
为a的担保声誉,![]() 与
与![]() 为b对a的直接服务信任与直接担保信任。b接受a的服务请求的条件为:
为b对a的直接服务信任与直接担保信任。b接受a的服务请求的条件为:![]() 。其含义为请求节点必须提高自己的声誉,才能够增加Eq,并且能够与声誉更高的服务节点交互。
。其含义为请求节点必须提高自己的声誉,才能够增加Eq,并且能够与声誉更高的服务节点交互。
- 在事务开始前,请求节点a也需要评估服务节点b。
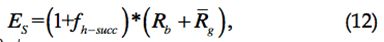
其中,![]() 为b的历史成功事务的比率,Sall为b提供的服务总数,Ssucc为成功提供的服务数,
为b的历史成功事务的比率,Sall为b提供的服务总数,Ssucc为成功提供的服务数,![]() 为第k次服务的事务容量,若首次提供服务则设置fh-succ为0。
为第k次服务的事务容量,若首次提供服务则设置fh-succ为0。![]() 为b的所有担保节点的平均担保声誉。因而,a将选择Es高的节点作为服务节点。
为b的所有担保节点的平均担保声誉。因而,a将选择Es高的节点作为服务节点。
-
声誉更新
在事务完成之后需要重新计算声誉。
-
反馈验证
在计算声誉之前,需要验证请求节点所提供的反馈,以丢弃没有通过认证的反馈。公式13给出了在一个过去时间窗口T内所收到的有效反馈的均值与方差,当前反馈F为T的最后一个反馈。
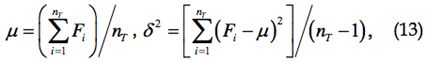
其中,nT为T内接收的反馈总数,Fi为第i个反馈。考虑一下三个方面:
- 当
 时,如果F位于区间
时,如果F位于区间 内,则被接受的概率为Rb|g(如果Rb|g<0.5则为1-Rb|g),否则,概率为1-Rb|g(如果Rb|g<0.5则为Rb|g)。Rb|g为对应的服务节点声誉或者担保节点声誉。
内,则被接受的概率为Rb|g(如果Rb|g<0.5则为1-Rb|g),否则,概率为1-Rb|g(如果Rb|g<0.5则为Rb|g)。Rb|g为对应的服务节点声誉或者担保节点声誉。 - 当
 时,反馈波动大,代表着可能存在服务节点与请求节点共谋的情况,此时反馈被接受的概率为0.5。
时,反馈波动大,代表着可能存在服务节点与请求节点共谋的情况,此时反馈被接受的概率为0.5。
注意即便没有被接受的反馈也被存档节点记录。此外,还存在第二次反馈认证,认证方法同第一次反馈认证,只是时间发生在以F为第一个接受反馈起的时间窗口T。
-
激励机制
在请求节点向服务节点请求服务时,公式10、11说明了高声誉的请求节点能够获得高声誉的服务节点所提供的服务。而在提供服务之后,对服务节点与担保节点的激励如公式14、15所示。Reward代表着节点提供服务或者担保的奖励。其中![]() ,代表着最近的窗口时间T内的成功事务比率。同时为了得到奖励,服务节点也会更倾向于与声誉高的担保节点来提高成功事务比率,担保节点也倾向于寻找声誉高的服务节点。
,代表着最近的窗口时间T内的成功事务比率。同时为了得到奖励,服务节点也会更倾向于与声誉高的担保节点来提高成功事务比率,担保节点也倾向于寻找声誉高的服务节点。

-
声誉更新
根据收到的反馈,在服务结束后,存档节点会计算服务节点与担保节点的声誉。公式16、17分别表示服务节点与担保节点声誉的更新。
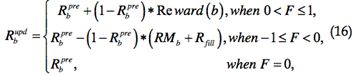

注意到节点声誉的更新由节点的存档节点执行,因此,设计声誉管理以及反馈通信机制是很重要的。
-
基于Chord的GeTrust实现
-
声誉管理
-
节点的声誉由其存档节点管理,而其自身应当是不可知的,这能防止共谋攻击。
在Chord网络中,节点ID是IP地址的hash,并且所有节点在一个圆上升序排列。对于服务id为k的服务,应当由顺时针下的下一个节点(或节点k)来分配。在一个请求过程中,请求节点从索引节点获取服务索引,并将这些节点作为服务节点候选。
为了避免存档节点来伪造节点的声誉,本文给出了匿名存储机制,该机制应该满足:
- 节点i的存档节点不能获取i的物理地址与逻辑地址
- 节点i的存档节点不是i,节点i不能选择自身的nodeID,以避免恶意的自己担任自己的存档节点。
- 任何节点j不能获取其他节点的存档节点的物理地址与逻辑地址。
为了满足这些要求,本文应用以下策略来选择一个节点的存档节点。节点i的存档节点由key=![]() 来决定,其存档节点是在chord圆上等于key或者follow key的第一个节点,或者称之为key的后继节点:successor(key)。由于hash的单向性,并且hash的最开始的key为i的物理地址,要求1、2得以满足。为了满足要求3,本文对Chord协议增加两点限制:1)只有i能够操作
来决定,其存档节点是在chord圆上等于key或者follow key的第一个节点,或者称之为key的后继节点:successor(key)。由于hash的单向性,并且hash的最开始的key为i的物理地址,要求1、2得以满足。为了满足要求3,本文对Chord协议增加两点限制:1)只有i能够操作![]() ,能迭代地获取后继节点2)j要与i的存档节点通信时,只有迭代模式能够允许向i的迭代节点路由消息,具体来说,假设j要知道i的声誉,根据Chord协议,j将nodeID=HASH(nodeIDi)的节点作为下一跳(p1),如此迭代,直到消息到达i的存档节点,i的声誉再沿着来的路径返回给j。
,能迭代地获取后继节点2)j要与i的存档节点通信时,只有迭代模式能够允许向i的迭代节点路由消息,具体来说,假设j要知道i的声誉,根据Chord协议,j将nodeID=HASH(nodeIDi)的节点作为下一跳(p1),如此迭代,直到消息到达i的存档节点,i的声誉再沿着来的路径返回给j。
-
GeTrust模型的事务
图3为Chord网络中GeTrust模型的事务处理过程,a为请求节点,b为服务节点,g为担保节点集,Da、Db、Dg分别为a、b、g的存档节点。一次事务中,拥有四种消息:Notify、Query、Reply、FeedBack。

- a向从索引节点获取到的节点发送
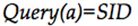 ,假设节点b接收了这个请求。通过
,假设节点b接收了这个请求。通过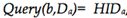 ,b从Da获取到了a的声誉:
,b从Da获取到了a的声誉: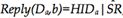 。b通过公式10、11对a进行评估,若成功,b查找担保节点,并建立担保关系,并向a回复:
。b通过公式10、11对a进行评估,若成功,b查找担保节点,并建立担保关系,并向a回复: 。
。 - a在收到b的回复后,询问b的担保节点以确定是否真正建立担保关系:
 ,若成功建立担保关系,担保节点回复:
,若成功建立担保关系,担保节点回复: 。
。 - 若a收到了担保节点的确认,a发送
 来请求获取b和g的历史事务记录,这会收到回复:
来请求获取b和g的历史事务记录,这会收到回复:
 ,之后a能够通过公式12评估服务节点,若通过则事务开始。
,之后a能够通过公式12评估服务节点,若通过则事务开始。 - 当事务结束之后,b与g需要通知存储节点以确保记录与a进行了事务交互,发送:
 。存档节点记录a的nodeID,并等待a的反馈。
。存档节点记录a的nodeID,并等待a的反馈。 - a发送反馈
 ,存档节点更新声誉。
,存档节点更新声誉。
-
仿真与结果分析
定义两种节点集:
- 正常节点:有两种类型。一是Nice-Peer(NP),这种节点真实地提供服务、担保与反馈;二是Unconscious Peer(UP),真实地提供担保与反馈,但以一定概率无意识地提供恶意服务,仿真时该概率设置为0.2。
- 恶意节点:有三种类型。1)Complete-malicious Peer(CMP):提供恶意服务、担保、反馈2)Strategic-malicious Peer(SMP):根据自身声誉有策略地作出反应,当声誉值低时,以一定概率(如0.4)跟NP一样,当声誉值高时,以很高的概率(如0.8)来攻击网络3)Malicious-feedback Peer(MFP):提供真实的服务与担保,提供假的反馈。
本文使用PeerSim来构造仿真环境。假设任一节点能找到需要的服务,尽管服务可能是恶意的。仿真环境中共1w节点,NP与UP分别占30%,CMP占20%,SMP与MFP各占10%。任一节点只要满足GeTrust模型条件,都可以成为服务、请求、担保节点。初始阶段没有担保节点,故随机地从服务节点的fingertable中选取担保节点。10000节点随机分配共10w不同的服务。L=10,T为一次模拟循环。每次模拟循环中,所有节点发送一个服务请求,在服务节点提供服务前,需要先建立担保关系,然后为请求节点提供服务,事务结束后,请求节点给出反馈,再根据反馈更新声誉。每次仿真包括30循环,共运行20次,取平均值作为仿真值。所有节点初始声誉为0.5。
-
参数的影响
GeTrust模型有两个参数:![]() 与
与![]() 。前者用来评估请求节点,取值范围(0,0.5),后者是可以作为担保节点的基本条件,取值(0.5,1)。
。前者用来评估请求节点,取值范围(0,0.5),后者是可以作为担保节点的基本条件,取值(0.5,1)。

首先设置 ,将恶意节点百分比从0.1到0.4以及
,将恶意节点百分比从0.1到0.4以及![]() 来比较成功事务比率,如图4(a)所示。4(b)为恶意节点百分比为0.4情况下不同delta的事务总数。Delta增加,成功事务比率下降,而总事务数增加。Delta为0.2时平衡最好。
来比较成功事务比率,如图4(a)所示。4(b)为恶意节点百分比为0.4情况下不同delta的事务总数。Delta增加,成功事务比率下降,而总事务数增加。Delta为0.2时平衡最好。
之后设置delta为0.2,将恶意节点百分比从0.1到0.4以及不同的RLIM-g来比较成功事务比率,如图4(c)所示。4(d)为恶意节点百分比为0.4情况下不同RLIM-g的事务总数。RLIM-g增加,总事务数下降。RLIM-g为0.7平衡最好。
因此,将之后的仿真参数设置为:Delta为0.2,RLIM-g为0.7。
-
不同相似系数的影响
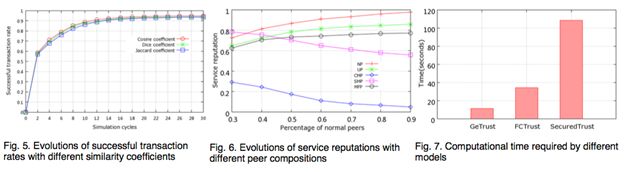
该小节实验针对公式6(计算相似度),仿真分别采用Jaccard\Dice\Cosine三种相似函数来进行评估。图5为实验结果,Consine、DICE基本一致,相对Jaccard成功事务比率更高,考虑到许多P2P网络模型中使用Consine,本文在之后的仿真中也使用Consine。
-
服务声誉的演化
设置正常节点的数目从30%到90%(NP与UP始终各占一半),其余节点CMP:SMP:MFP=2:1:1。图六为实验结果。当正常节点数目大于60%后,NP与UP的声誉大于0.8,CMP声誉小于0.1。
-
计算复杂度
图7为与FCTrust、SecuredTrust的复杂度对比,可以看出GeTrust的计算复杂度最低。
-
反馈验证的有效性
图8为实验结果,其中FMF为filtered malicious feedbacks,而SFR为successful filtered rate of malicious feedbacks。

-
不同比例的恶意节点的影响
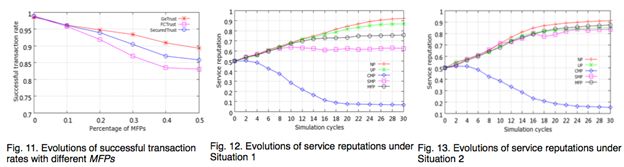
图9为将CMP的比例从0到50%情况下的成功事务比率,网络中的其他节点平均设定为NP与UP。
图10为将SMP的比例从0到50%情况下的成功事务比率,网络中的其他节点平均设定为NP与UP。
图11为将MFP的比例从0到50%情况下的成功事务比率,网络中的其他节点平均设定为NP与UP。
-
抵抗攻击
-
共谋攻击
-
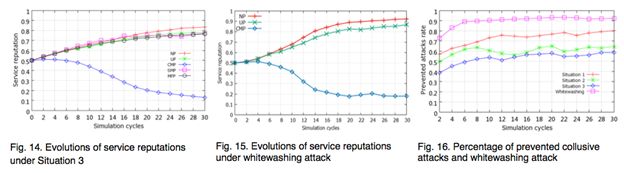
共谋攻击发生在服务节点与担保节点、请求节点与服务节点之间、请求节点服务节点担保节点之间。仿真时把SMP当成一个共谋组,SMP节点占比20%,NP:UP:CMP:MFP=3:3:1:1。
- 服务节点与担保节点共谋
进行额外的设定:共谋组节点接到共谋组节点的担保应用时,不进行评估。实验结果如图12所示。
- 请求节点与服务节点共谋
进行额外的设定:共谋组请求节点在事务结束后作出的反馈,若服务节点属于共谋组,给予好的反馈,否则低的反馈。实验结果如图13所示。
- 请求节点服务节点担保节点共谋
同时进行前两个额外的设定。实验结果如图14所示。
-
Whitewashing
CMP占比20%,NP与UP同比例分配剩余节点。假定CMP节点声誉低于0.1,该节点将离开网络然后再重新加入网络(并有一个新的nodeID)。实验结果如图15所示。
图16为四种攻击情况下的阻挡的攻击的比率。