leetcode
leetcode记录–算法学习
2019.12.03 add Manchester algorithm
2019.12.03 add Graph
2019.12.03 add 有向图的最长路径问题
2019.12.24 add 二分法
2019.12.27 add 牛顿迭代法
2019.12.30 add 二分查找数组旋转点
2019.12.31 add 排序算法的应用
2020.02.02 add 堆或链表的应用-设计推特
文章目录
- leetcode记录--算法学习
- 算法的时间复杂度和空间复杂度
- 时间复杂度(Time Complexity)
- 空间复杂度(Space Complexity)
- 排序算法的时间和空间复杂度
- 算法原则
- 两个链表倒序相加(中等-数学)
- 整数反转(简单-数学)
- dfs/bfs
- 栈
- 单栈
- leetcode-71-简化路径
- 双栈
- leetcode-155-最小栈
- 链表
- 单指针,增断链
- 二叉树展开为链表
- 合并两个有序链表
- 双指针
- leetcode-148-链表排序
- leetcode-622设计循环队列
- 寻找数组的最小值
- 循环遍历寻找最小值
- Math.min Math.max方法:
- 未归类题目
- leetcode-计算字符串子串
- leetcode-电话号码的组合
- leetcode-卡牌分组
- leetcode-种花问题
- leetcode-格雷编码
- leetcode-奇偶排序
- leetcode-第K个最大元素
- leetcode-最大间距
- leetcode-缺失的第一个正数
- 正则
- 检测字符串是否由重复的子字符串组成
- 正则表达式匹配
- 关于快速排序
- in-place算法:
- 快排应用就地算法的原理分析
- 堆
- 基本概念
- 堆排序(构建大根堆的方式)
- 堆的一些应用
- leetcode-313-超级丑数
- leetcode-451-根据字符出现频率排序
- leetcode-355-设计推特
- 矩阵
- leetcode-54-螺旋矩阵
- leetcode-48-旋转图像
- 图
- 无向图的DFS应用:leetcode-399-除法求值
- 图的最长路径
- leetcode-310-最小高度树
- leetcode-329-矩阵中的最长递增路径
- 贪心算法
- leetcode-买卖股票
- 买卖股票简单版(只买入卖出一次)
- 买卖股票 leetcode-123
- leetcode-柠檬水找零
- 暴露问题
- 动态规划
- leetcode-62-不同路径
- leetcode-42-接雨水
- 关于动态规划问题
- dp是解决什么样的问题
- 状态
- 状态转移方程
- leetcode-5-最长回文子串问题
- Manchester算法
- 递归
- leetcode-复原IP地址
- leetcode-112-二叉树路径之和
- leetcode-101-对称二叉树
- leetcode-98-验证二叉搜索树
- leetcode-980-不同路径(3)
- 总结-分治-dp-贪心
- 分治法
- 动态规划
- dp到斐波那契数列
- 贪心算法
- leetcode84-柱状图中最大的图形
- leetcode85-最大矩形
- 钢条分割问题
- 二分查找法
- leetcode-4-寻找两个有序数组的中位数
- leetcode-29-两数相除
- 有序数组被截断后寻找旋转点
- leetcode-33-搜索旋转排序数组
- leetcode-81-搜索旋转排序数组 II
- leetcode-69-x 的平方根-++牛顿迭代法++
- 排序算法的应用
- 数学问题的转换
- leetcode-621任务调度器
- leetcode-9-回文数
- 计算时间复杂度和空间复杂度
- 主定理(master theorem)
算法的时间复杂度和空间复杂度
常用计算公式:
- n * O( 1 ) = O( n );
- c * O( n ) = O( n ); 【常数系数直接省略】
- O( cm ) + O( cn ) = O( cm ); 【常数相加取最大项】
- O( m ) * O( n ) = O( m * n);
时间复杂度(Time Complexity)
- 概念:
首先要说的是,时间复杂度的计算并不是计算程序具体运行的时间,而是算法执行语句的次数。执行算法所需要的计算工作量。
当我们面前有多个算法时,我们可以通过计算时间复杂度,判断出哪一个算法在具体执行时花费时间最多和最少。
-
解释:时间频度–>时间复杂度:一个算法花费的时间与算法中语句的执行次数成正比例。T(n),n表示问题的规模
-
计算方式:通常我们计算时间复杂度都是计算最坏情况
①选取相对增长最高的项:计算基本语句(执行次数最多的语句)执行次数的数量级。(一般就是找循环体)
②最高项系数是都化为1
③若是常数的话用O(1)表示
- 这三点的意思是:时间频度是T(n)=1000n²+10n+6和T(n)=10n²+10n的时间复杂度都是T(n)=O(n²)
空间复杂度(Space Complexity)
- 概念:
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的量度。
- 计算方式:
①忽略常数,用O(1)表示
②递归算法的空间复杂度=递归深度N*每次递归所要的辅助空间
③对于单线程来说,递归有运行时堆栈,求的是递归最深的那一次压栈所耗费的空间的个数,因为递归最深的那一次所耗费的空间足以容纳它所有递归过程。
- 更多的是我们需要计算时间复杂度。
- 表示方式:S(n)=O(n)
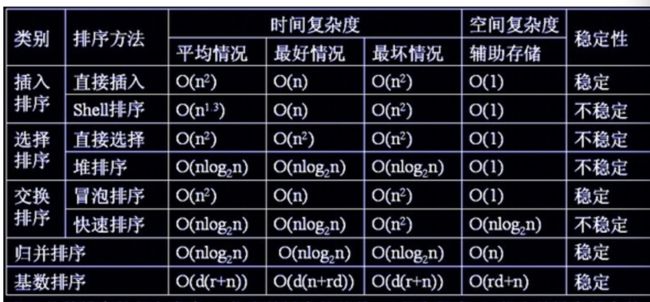
排序算法的时间和空间复杂度

算法原则
避免浮躁/按部就班,不投机取巧,循序渐进
难度大的算法题目如何解?
算法的本质就是寻找规律并实现
如何找到规律?
发现输入和输出的关系,寻找突破点
复杂的实现怎么办?
实现是程序和数据结构的结合体。
步骤:
找规律===>伪代码===>源代码
在给的测试用例输入很少的情况,自己把输入变长来测试。
- 问题抽象
- 数学建模
- 动态输入
两个链表倒序相加(中等-数学)
难点:
- 大整数相加:两个字符串相加
- 数组转链表
- 链表转数组
//大整数相加
var bigNum=function(a,b){
var aa=a.split('').reverse();
var bb=b.split('').reverse();
var temp=0;
var res=[];
var len=aa.length>bb.length?aa.length:bb.length;
for(var i=0;i<len;i++){
aa[i]=(aa[i]?aa[i]:0);
bb[i]=(bb[i]?bb[i]:0);
var res0=parseInt(aa[i])+parseInt(bb[i])+temp;
temp=res0>=10?1:0;
res.unshift(res0%10);
}
if (temp)
{res.unshift(1);}
return res.join('');
}
- 注意点:
-
代码过于冗长
-
占用内存较大
-
思路基本正确
处理点:
- 倒序处理,从后往前加
- 进位处理
- 最后一位处理(也可以理解为第一位处理)
改进版代码:
var addBigNum = function (a, b) {
var res = '', c = 0;
a = a.split('');
b = b.split('');
while (a.length || b.length || c) {
c += ~~a.pop()+~~b.pop();
//c +=(a.pop()|0)+(b.pop()|0);
res = c % 10 + res;
c = c > 9; //c=c>9
}
return res
}
知识点整理:
- ~~运算符:
"~"的作用是将数字转化为有符号32位整数并作位取反, 位取反即把数字转换为2进制补码然后把0和1反转.
那么:双波浪线的作用就是把一个小数舍弃小数点转换为整数,在数字较小转换为32位整数时不会溢出的情况下可以当作Math.floor的偷懒写法。但是位或0的方式写起来更一般。
总结:作用:
- “123”->123
- 123.5->123
- 字符串转换为整数或者undefined->0
//链表类
function ListNode(val) {
this.val = val;
this.next = null;
}
//数组转链表
var changeToLink=function(arr){
var link=new ListNode(arr[0]);
var cur=link;
arr.splice(0,1);
while(arr.length){
cur.next=new ListNode(arr[0]);
cur=cur.next;
arr.splice(0,1);
}
return link;
}
//改进版:既然每一次都使用上一次的next那么必须用reduce岂不是更加方便:
var changeToLink0=function(arr){
var link0=new ListNode(arr.pop());
return arr.reduceRight((res,cur)=>{
var node=new ListNode(cur);
node.next=res;
return node;
},link0)
}
//为什么时reduceRight而不是reduce呢?思考一下这个采坑点:用reduce时从左到右缩减,返回只能是res.next,但是最后缩减完毕就是只剩下最后一个数了,所以用reduceRight之后能从右向左挂上去,最后返回一条完整的链。
//链表转数组
var changeToArray=function(link){
var res=[];
var cur=link;
res.push(cur.val);
cur=link.next;
while(cur){
res.push(cur.val);
cur=cur.next;
}
return res;
}
//核心思想也是不停push,让cur不停后移
**采坑点 ** :
- reduce/reduce Right选择问题
- 使用上:不用到最后一个参数且要有初始值,只能从根源上改变数组。※※※
整数反转(简单-数学)
关键点:使用正则去首位的0,Math.pow(2,31)判断溢出
建议:正则不好用,建议用数组的 shift+while 检验
dfs/bfs
对每个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次。
深度优先搜索算法:
| 概念 | 特点 | |
|---|---|---|
| 深度优先 | 对每个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次 | 不全部保留节点,占用空间小;有回溯操作,及入栈出栈,运行速度慢 |
| 广度优先 | 从上向下对每一层依次访问,每一层从左往右访问节点,访问完一层就进入下一层,直到没有节点可以访问为止。 | 保留全部节点,占用空间少,无回溯操作,运行速度快 |
const reConstructBinaryTree0=(vin,post)=>{
if(vin.length==0||post.length==0){
return null;
}
const index=vin.indexOf(post[post.length-1]);
const left=vin.slice(0,index);
const right=vin.slice(index+1);
const newPost0=post.slice(0,index);
const newPost1=post.slice(index,post.length-1);
const node=new TreeNode(post[post.length-1]);
node.left=reConstructBinaryTree0(left,newPost0);
node.right=reConstructBinaryTree0(right,newPost1);
return node;
}
栈
单栈
leetcode-71-简化路径
如何更好的覆盖所有的边界情况,减小代码的冗余度?
- 建立好区分情况的基准,不要只关注一种特殊情况
- 提交代码时如果发现多次触发边界,说明情况没做好分类,要及时做到复盘。
/*
* 在处理这个问题上出现了较大的偏差,利用栈的方式没有错
* 但是首先对字符串进行了一系列操作后导致边界情况无法很好的覆盖
* 其实只要考虑好所有的情况就可以了,不应该遍历的时候只去处理两个点的问题,尤其在/..abc这种情况时
* 完全可以通过利用/去分割字符串的方式解决
*/
双栈
leetcode-155-最小栈
辅助栈和原栈同步的方式实现追踪最小值
/**
* 首先这个题目看似简单,但其实也有一些奥妙在里面,首先要求在常数时间内找到最小的元素
* 这就意味着时间复杂度为O(1)
* 因此我们应该在push数据的时候就已经做好最小数据的检测,因此利用辅助栈来实现获取最小值,同时辅助栈和原栈同步,
* 只是在push数据的时候需要额外判断push哪一个数。同时因为pop操作的存在,不能使用this.min来定义最小值,故而辅助栈是最好的选择
*/
var MinStack = function() {
this.data=[];
this.temp=[];
};
/**
* @param {number} x
* @return {void}
*/
MinStack.prototype.push = function(x) {
if(this.temp.length<1||this.temp[this.temp.length-1]>x){
this.temp.push(x);
}else{
this.temp.push(this.temp[this.temp.length-1]);
}
this.data.push(x);
};
/**
* @return {void}
*/
MinStack.prototype.pop = function() {
this.data.pop();
this.temp.pop();
};
/**
* @return {number}
*/
MinStack.prototype.top = function() {
return this.data[this.data.length-1];
};
/**
* @return {number}
*/
MinStack.prototype.getMin = function() {
return this.temp[this.temp.length-1];
};
链表
接下来的题都不同程度的和链表有关系
单指针,增断链
链表的题中一个重要的特点就是移动指针,以及增断链。
二叉树展开为链表

const flatten1=root=>{
let temp=[],pre=null;
root&&temp.push(root);
while(temp.length){
let tempTree=temp.pop();
// root.right=tempTree;
// root.left=null;
if(pre!==null){
pre.right=tempTree;
pre.left=null;
}
tempTree.right&&temp.push(tempTree.right);
tempTree.left&&temp.push(tempTree.left);
pre=tempTree;
}
console.info(root);
};
const flatten2=root=>{
let pre=null;
const recur=root=>{
if(!root) return;
recur(root.right);
recur(root.left);
root.right=pre;
root.left=null;
pre=root;
};
recur(root);
console.info(root);
};
const flatten3 = root=>{
if(!root) return null;
const stack = [];
while(root.left || root.right || stack.length>0){
if(root.right) stack.push(root.right);
if(root.left){
root.right = root.left;
root.left = null;
}else{
root.right = stack.pop()
}
root = root.right
}
};
合并两个有序链表
/**
* 如此就写出来了一种非递归的写法
* 主要通过以其中一个链表为标准依次遍历向其中添加另一个链表中数据的方式
* 时间复杂度O(m+n),空间复杂度O(1)
* @param l1
* @param l2
* @returns {null|*}
*/
const mergeTwoLists1=(l1,l2)=>{
// if(!l1&&!l2){
// return l1;
// }else if(!l1){
// return l2;
// }else if(!l2){
// return l1;
// }
// 对上面的代码进行简化
if(!l1) return l2;
if(!l2) return l1;
let res = new ListNode(),res0=res;
while(l1){
let temp1=l1.next;
while(l2){
let temp2=l2.next;
if (l2.val>=l1.val){
l1.next=l2;
res0.next=l1;
res0=res0.next;
break;
}else{
res0.next=l2;
res0=res0.next;
l2=temp2;
}
}
if(!l2){
res0.next=l1;
res0=res0.next;
}
l1=temp1;
}
console.info(res.next);
return res.next;
};
mergeTwoLists1(list1,list2);
/**
* 下面是对上面这段代码的优化,实际上我们总是在给res0向后追加
* 改进后的代码更加清晰简明扼要
* 思路的本质是迭代
*/
const mergeTwoLists2=(l1,l2)=>{
let res=new ListNode(),res0=res;
while(l1&&l2){
if(l1.val>=l2.val){
res0.next=l2;
l2=l2.next;
}else{
res0.next=l1;
l1=l1.next;
}
res0=res0.next;
}
res0.next=!l1===true?l2:l1;
return res.next;
};
/**
* 递归实现上面的内容,递归的关键是输入,输出还有边界条件
* 但是这个想法过于巧妙
* @param l1
* @param l2
*/
const mergeTwoLists3=(l1,l2)=>{
if(!l1) return l2;
if(!l2) return l1;
if(l1.val>=l2.val){
// 以l2为标准进行融合
l2.next=mergeTwoLists3(l1,l2.next);
return l2;
}else{
// 以l1为标准进行融合
l1.next=mergeTwoLists3(l1.next,l2);
return l1;
}
};
双指针
leetcode-148-链表排序
/**
* leetcode-148解决方案
* 巧妙的利用两个指针,一个遍历一个负责移动位置
* @param head
* @returns {*}
*/
var sortList = function(head) {
var swap=(n,m)=>{
var val=n.val;
n.val=m.val;
m.val=val;
};
var sort=(start,end)=>{
let val=start.val;
let p=start.next;
let q=start;
while(p!==end){
if(p.val<val){
q=q.next;
swap(p,q);
}
p=p.next;
}
swap(start,q);
return q;
};
var sort0=(start,end)=>{
if(start!==end){
let temp=sort(start,end);
sort0(start,temp);
sort0(temp.next,end);
}
};
sort0(head,null);
return head;
};
leetcode-622设计循环队列
同样是用双指针来解决一些方法的定义,通过对比首尾指针来确定数据是否满或空,需要领会这个思想。
寻找数组的最小值
循环遍历寻找最小值
类似于选择排序中定义好最小值然后进行寻找比它小的值的算法
Math.min Math.max方法:
但是他们只接受可变长度的参数列表,不接受直接传递数组的形式,可以用apply的方法改变传参的方式:
Math.min.apply(null,arr);
//或者 Math.min.apply(Math,arr);
即:call 和 apply的作用是什么?除了改变函数的this指向外,还有什么?—apply可以改变传递给函数参数的形式(其实我认为也是改变this指向的一种应用)
未归类题目
leetcode-计算字符串子串
关键点:
- 利用RegExp构造函数创建一个自己的正则表达式对象,
- RegExp.$1的使用:
$1, …, $9 属性是静态的, 他不是独立的的正则表达式属性. 所以, 我们总是像这样子使用他们RegExp.$1, …, RegExp.$9.
但是在str.replace中也可以直接用$1, … ,9等
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/RegExp/n
-
str.repeat使用:
"abc".repeat(2) // "abcabc"
针对leetcode上出现的正则表达式过长的现象
var countBinarySubstrings = function(str) {
let r = []
// 给定任意子输入都返回第一个符合条件的子串
let match = (str) => {
let j = str.match(/^(0+|1+)/)[0]
let o = (j[0] ^ 1).toString().repeat(j.length)
if(str.substr(j.length,j.length)===o)
return true;
}
// 通过for循环控制程序运行的流程
for (let i = 0, len = str.length - 1; i < len; i++) {
let sub = match(str.slice(i))
if (sub) {
r.push(sub)
}
}
return r.length
};
leetcode-电话号码的组合
抛出问题:如果我输入2,3,4呢,不是写三个for循环这么垃圾的算法的,要先算出2,3再跟4组合,显然最后的方案是:递归
本题:我暴露出来的缺点是映射没有做好,第一个想到的是object.keys object.value显然这是不对的,把算法做复杂的…
关键点:
- 做好字典的映射,应该单独提取一个数组来装字典
- 递归:不一定非要最外层递归,因为如果这样要处理数据的转换格式,可以内部定义函数递归
- 边缘情况要处理好
var letterCombinations = function(digits) {
var map=['','','abc','def','ghi','jkl','mno','pqrs','tuv','wxyz'];
if(digits.length===0) return [];
if(digits.length===1){
// 自己写的冗余
// return arr0[0].toString().split('');
return map[digits].split('');
};
// 递归可以不递归最外层的主函数,而是内部的函数
var arr=digits.split('');
var arr0=arr.map((item)=>{
return map[item];
})
var combine=function(arr0){
// 结果数组
var res=[];
for(var i=0;i<arr0[0].length;i++){
for(var j=0;j<arr0[1].length;j++){
res.push(`${arr0[0][i]}${arr0[1][j]}`);
}
}
if (arr0.length>2){
arr0.splice(0,2,res);
res=combine(arr0);
}
return res;
}
return combine(arr0);
};
leetcode-卡牌分组
关键点:
- 排序
- 找最大公约数(核心)

找最大公约数的一个规律:
总是在寻找b和d(其中a%b=d)
注意寻找规律:
d=0:最大公约数就是b,f=0:最大公约数就是d
因而还是用递归的方式来进行;
var GCD=(a,b)=>{
if(b===0){
return a;
}else {
return GCD(b,a%b);
}
}
找重复的数字:
- 方式一:转化成字符串,缺点:无法转化大于10的数,因为此时会按单个字符来做
str.match(/(\d)\1+|(\d)/g);//匹配全局中aaa或者a(单个字符)
知识点: 正则中\1的使用:匹配的是第一个()分组匹配的引用,即第一个分组()重复
正则\1\2和\1的理解
- 方式二:用中间对象承接所有内容,重点推荐:
let temp={};
arr.forEach(item=>{
temp[item]=temp[item]?temp[item]+1:1;
});
leetcode-种花问题
出现的问题:复杂度太高,用了递归来实现,分别判断了数组长度为1,数组的第一位,数组的最后一位。
var canPlaceFlowers = function(flowerbed, n) {
if (n<0||flowerbed.length<=0) return null;
if (n==0) return true;
if (flowerbed.length==1){
if (flowerbed[0]==0){
flowerbed.splice(0,1,1);
return canPlaceFlowers(flowerbed,n-1);
}else return false;
}
if (flowerbed[0]==0&&flowerbed[1]==0){
flowerbed.splice(0,1,1);
return canPlaceFlowers(flowerbed,n-1);
}
if (flowerbed[flowerbed.length-1]==0&&flowerbed[flowerbed.length-2]==0){
flowerbed.splice(flowerbed.length-1,1,1);
return canPlaceFlowers(flowerbed,n-1);
}
for (var i=1;i<flowerbed.length-1;i++){
if (flowerbed[i]==0&&flowerbed[i-1]==0&&flowerbed[i+1]==0){
flowerbed.splice(i,1,1);
return canPlaceFlowers(flowerbed,n-1);
}
}
return false;
};
最佳方案:
var canPlaceFlowers = function(arr, n) {
// 计数器
let max = 0
// 右边界补充[0,0,0],最后一块地能不能种只取决于前面的是不是1,所以默认最后一块地的右侧是0(无须考虑右侧边界有阻碍)(LeetCode测试用例)
arr.push(0)
for (let i = 0, len = arr.length - 1; i < len; i++) {
if (arr[i] === 0) {
if (i === 0 && arr[1] === 0) {
max++
i++
} else if (arr[i - 1] === 0 && arr[i + 1] === 0) {
max++
i++
}
}
}
return max >= n
}
此时只去判断能够插入的个数和想要插入的个数大小就可以了,复杂度直接将为n;
关键点:对于我考虑的已经加入新节点的位置不用再审查的问题,并不需要一定去操作数组,可以通过在for循环中再次通过i++越过这一位。
leetcode-格雷编码
这个题暴露的问题还是规律没有找好:

自己在找规律这方面实在是特别的欠缺。
leetcode-奇偶排序
这个题暴露出一个问题:思路基本正确,但是还是想的过于崎岖,虽然自己写的时间复杂度也是n,但是空间复杂度太大,过多的操作数组
// 想起了快排的思路
var sortArrayByParityII=function(arr){
if (arr.length<=0||arr.length%2!=0) return null;
if (arr.length==1) return A;
var single=[],double=[],res=[];
arr.forEach((item)=>{
if (item%2!=0){
single.push(item);
}else
double.push(item);
})
console.info(single,double);
for (var i=0;i<arr.length;i+=2){
res[i]=double.pop();
}
for (var j=1;j<arr.length;j+=2){
res[j]=single.pop();
}
return res;
}
改进版:
var sortArrayByParityII=function(arr){
if(arr.length<=0||arr.length%2!=0) return null;
if(arr.length==1) return arr;
var res=[];
// arr.sort((a,b)=>a-b);
var even=0;
var odd=1;
arr.forEach((item)=>{
if(item%2==0){
res[even]=item;
even+=2;
}else{
res[odd]=item;
odd+=2;
}
})
return res;
}
leetcode-第K个最大元素
优化方案:
使用sort其实把所有的数都遍历一次:而它内部的原理又是什么样的呢?
详解数组–sort()方法原理上
Array.sort()的使用方法以及原理
总是比较相邻的两个元素,相比a-b>0则交换位置,否则不交换位置。(有点类似于冒泡排序,并且在查找资料的时候发现在java中Array.sort原理会按数组的长度相应的使用对应的排序算法,而在MDN的解释上:js中,算法叫in-place algorithm就地算法)
就地算法(在快排的优化中也会用到)
leetcode-最大间距
优化方案:
区别于普通思路中的:
先利用sort函数进行排序,然后对排序后的数组进行一次遍历筛选,
在优化方案中利用冒泡排序中每一轮都能排出最大的值这一特点,边排序边比较;
另外
console.info(undefined-10);//NaN
console.info(undefined-undefined);//NaN
console.info(typeof null);// object
针对冒泡排序的写法(外层i的数量)有相应额解决方案:
const maximumGap = (nums)=>{
if (nums.length<2){
return 0;
}
let min=0;
// i是从nums.length开始的
for (let i=nums.length;i>0;i--){
for (let j=0;j<i;j++){
if (nums[j]>nums[j+1]){
let temp=nums[j];
nums[j]=nums[j+1];
nums[j+1]=temp;
}
}
if (nums[i]-nums[i-1]>min){
min=nums[i]-nums[i-1];
}
}
return min;
}
const maximumGap = (nums)=>{
if (nums.length<2){
return 0;
}
let min=0;
// i是从nums.length-1开始的
for (let i=nums.length-1;i>0;i--){
for (let j=0;j<i;j++){
if (nums[j]>nums[j+1]){
let temp=nums[j];
nums[j]=nums[j+1];
nums[j+1]=temp;
}
}
// console.info(nums,i);
if (nums[i+1]-nums[i]>min){
min=nums[i+1]-nums[i];
// console.info('testing==>',min);
}
}
return Math.max(min,nums[1]-nums[0]);
}
leetcode-缺失的第一个正数
- 方案1:先filter出正数===>sort排序===>for循环对比两个最小数之间的间隔
- 方案2:先filter出整数===>思考选择排序,每一轮都是找出最小的那个元素,所以可以结合选择排序降低时间复杂度,明显运行占用的时间降低了50%;
const firstMissingPositive = (nums)=>{
nums=nums.filter((item)=>item>0);
if(nums.length<1) return 1;
for (let i=0;i<nums.length;i++){
let min=i;
for (let j=i+1;j<nums.length;j++){
if (nums[j]<nums[min]){
min=j;
}
}
let temp=nums[min];
nums[min]=nums[i];
nums[i]=temp;
// console.info('==>',nums);
if (nums[0]>1) return 1;
// console.info(nums[i]-nums[i-1]);
if (nums[i]-nums[i-1]>1){
return nums[i-1]+1;
}
}
// 如果是排好顺序的
return nums[nums.length-1]+1;
}
正则
关于正则的知识点之前整理过一版:
检测字符串是否由重复的子字符串组成
/**
* 查看是否有重复的子字符串组成,如果是返回true
* 如果没有返回false
* 我最初写的这个代码时间复杂度过高,
* 下面列出来用正则和一种很牛逼的方法写的答案
*/
const repeatedSubstringPattern=str=>{
for (let i=1;i<str.length;i++){
let temp=str.slice(0,i);
let num=Math.ceil(str.length/i);
if (num!==1&&temp.repeat(num)===str){
// console.info(temp,i,j);
return true;
}
}
return false;
};
/**
/w匹配一个单字字符(字母、数字或者下划线)。等价于 [A-Za-z0-9_]。
/W匹配一个非单字字符。等价于 [^A-Za-z0-9_]。
*/
const repeatedSubstringPattern0=str=>{
return (/^(\w)\1+$/).test(str);
};
/**
* str+str 截取第一位往后和倒数第一位往前一定会包含之前的字符串
* 真是神操作啊
* @param str
* @returns {boolean}
*/
const repeatedSubstringPattern1=str=>{
return (str+str).slice(1,str.length*2-1).indexOf(str)!==-1;
};
let str='aba';
console.info(repeatedSubstringPattern0(str));
正则表达式匹配
leetcode-10
分不同情况来解决这个问题:

首先其实总体思路仍然是应用递归:
边界条件:s 和 p是否长度为0,因为第一种情况的存在,应该在p长度为0的时候检测s的长度.
输入: s和p
输出:裁剪后s和p
规则:
首先检测s和p的首字母是否一样,如果一样则置标志位为true.
关于标志位为何一定要存在:
因为我们分两种情况讨论:
- p是有模式的
所谓有模式:即存在✳️,存不存在点 只需要一句话检查一下即可,而✳️肯定不能在第一位,只能在第二位。所以s p第一位要先核对,把它单独拿出来。
有模式情况下还分两种情况:
- 有模式先不管模式,因为✳️可以代表0个,可以代表1个或多个,检查✳️后的内容是否能匹配s呢
- 第一种情况不行,有可能是因为✳️前面的那个字符有多个。
- p是无模式的
直接裁剪,然后递归重复整个流程
const isMatch=(s,p)=>{
const match=(s,p)=>{
if (p.length===0){
return s.length === 0;
}
let flag=false;
if (s.length>0&&(p[0]===s[0]||p[0]==='.')){
flag=true;
}
if (p.length>1&&p[1]==='*'){
// p *后无法匹配s
// 则继续检查是不是*前的内容是否出现了多次
return match(s,p.slice(2))||(flag&&match(s.slice(1),p));
}else{
return flag&& match(s.slice(1),p.slice(1));
}
};
return match(s,p);
};
关于快速排序
- 快排的时间复杂度O(nlogn),空间复杂度也是O(nlogn),其他算法的空间复杂度基本都是O(1),显然快排有优化空间
in-place算法:
- 是什么?百度百科基本就是wikipedia的翻译版,基本含义就是就地算法致力于减少空间复杂度,采用的方式为替换或者交换元素,用输出覆盖输入。之前Array.prototype.sort也是用到这种就地算法,但具体源码没有看,步骤应该类似。
- The input is usually overwritten by the output as the algorithm executes. In-place algorithm updates input sequence only through replacement or swapping of elements.
const quickSortH=(arr)=>{
const swap=(arr0,i,j)=>{
// 交换两个数的位置
let temp=arr0[i];
arr0[i]=arr0[j];
arr0[j]=temp;
console.info('swap',arr0);
}
const findPivot=(arr,left,right)=>{
// 寻找基准,left和right指的是本次递归的过程中的左下标和右下标
let flag=arr[left];
let idx=left+1;// 交换的下角标
for (let i=idx;i<=right;i++){
if (arr[i]<flag){
swap(arr,i,idx);
idx++;// 交换结束后,交换的下角标应该往后移动一位
}
}
console.info('idx',idx);
// 最后要交换基准和标尺的第一位
swap(arr,idx-1,left);
console.info('find',arr);
return idx;
}
const sort=(arr,left,right)=>{
if(left<right) {
let pivot=findPivot(arr,left,right);
console.info(arr);
sort(arr,left,pivot-1);
sort(arr,pivot,arr.length-1);
}
}
sort(arr,0,arr.length-1);
return arr;
}
const my_arr=[7,1,3,2,8,0,5];
console.info('res===>',quickSortH(my_arr));
快排应用就地算法的原理分析
| 原理分析 |
|---|
| 1.pivot:也就是快排的基准,之后的所有元素都是跟它进行对比 |
| 2.left:本次遍历的起始指针,一般pivot选为arr[left] |
| 3.right:本次遍历的结束指针 |
| 4.idx:交换的角标,每次交换都是在left的后一位,而且每次交换结束后这个角标应该往后加一个 |
| 5.一轮结束后就根据基准分出了左右,而基准在哪里了呢,所以还要进行一次交换就是left和idx-1的交换,将基准放在交换角标的前面一个位置 |
| 6.最后一步进行递归,也就是左侧left,idx-1,右侧idx,arr.length-1 |
堆
更多关于堆的总结请参看我的整理:堆
基本概念
- 必须是完全二叉树(如果二叉树有n层,那么n-1层必须是满二叉树)
- 任一节点的值是其子树所有节点的最大值(此时为大根堆)或最小值(此时为小根堆)
堆排序(构建大根堆的方式)
和冒泡排序和选择排序一样,构建最大堆:每次总是从最后一个根节点开始比较,每次排序一遍之后总能找出最大的值,然后将这个最大值和堆的最后一个数交换,并把最大值剔除,此时又破坏了堆的结构,然后进行重新排序。最后只剩下一个节点的时候就排序完成。
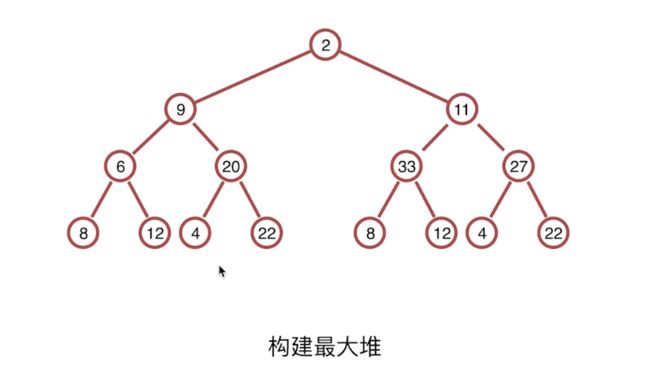
堆的一些应用
- 构建最大堆在应用于堆排序上有很大的优势。
- 在查找方面也具有很大优势:譬如构建最大堆之后,查找效率提高(一般如果比父节点大就没必要比较它的子节点了)。
leetcode-313-超级丑数
超级丑数是指所有质因数都是长度为k的质数列表primes中的正整数
解题顺序:求质因数(找约数–>是否为质数)–>是否在列表primes中–>是否达到指定个数n
难点:
- 如何找约数:首先一个整数n的约数不会大于n/2,因此可以通过遍历的方法进行找到所有约数
- 如何判断是否为质数:和找约数的方式一样,除了1没有其他约数那就意味着它是质数
leetcode-451-根据字符出现频率排序
这个题可以用堆排序来实现,使用堆排序。
学到了两点:
- map数据结构:以前了解到它就是类似于object,只不过键值类型不只局限于字符串类型,常用API(实例属性和方法):
- set(k,v)
- get(k)
- delete(k)
- has(k)
- clear()
- size属性
- 遍历方法:keys,values,entries,forEach
- 数组转换:扩展运算符或者Array.from()
- 比如在这里用到的就是map.values()返回的是所有值的遍历器,Iterator是一种接口,为不同的数据结构提供统一的访问机制:
map[Symbol.iterator]===map.entries
Iterator 接口的目的,就是为所有数据结构,提供了一种统一的访问机制,即for…of循环(详见下文)。当使用for…of循环遍历某种数据结构时,该循环会自动去寻找 Iterator 接口。ES6 规定,默认的 Iterator 接口部署在数据结构的Symbol.iterator属性,或者说,一个数据结构只要具有Symbol.iterator属性,就可以认为是“可遍历的”(iterable)。Symbol.iterator属性本身是一个函数,就是当前数据结构默认的遍历器生成函数。更多内容可以访问阮一峰es6
- 除了使用for循环遍历数组以外也可以这样来使用数组:使用while+pop()来遍历数组
leetcode-355-设计推特
本题是一个非常有挑战的设计题也是一个算法题;关于算法部分具体解题思路参看我的题解
矩阵
leetcode-54-螺旋矩阵

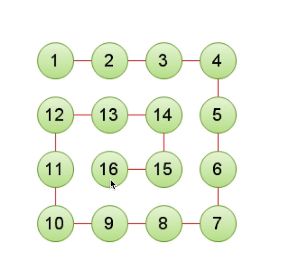
思路讲解:
可以先看第一圈,每次永远在重复的查找一圈,化难为简。
- 第一行直接放入,最后一行翻转存入
- 中间各行只存最后一位(最好通过pop的方式)
- 去头去尾,倒着存入第一位数据(通过shift的方式)
- 递归
学习总结:
- 复杂问题化难为简,一定要把复杂的问题进行拆分
- 一般一些复杂问题可以用递归或者循环解决,尤其是递归,要学会去寻找每个mini 问题的思路,就能解决好一个问题。
leetcode-48-旋转图像
这个题主要思路还是观察找规律,其实是一个矩阵的转置加一些交换操作。时间复杂度为O(n^2)
图
关于图的各种基本算法:涉及BFS,DFS,拓扑排序,Hierholzer算法等。
参考我的另一篇Blog:
数据结构javascript描述
无向图的DFS应用:leetcode-399-除法求值
/**
* 这个题剥去题意本身,考虑各种除法,可以认为是一个无向图的问题
* 首先建立邻接表,对queries里面的数组定义为start和end
* 对邻接表从起点开始进行dfs,同时注意:dfs时无法返回,只能在合适的条件收集结果
* 必须用回溯的原因是起点和终点固定住了,而不是需要遍历所有元素,因此,需要回溯
*/
const calcEquation = (equations, values, queries)=>{
// initialize adj
let adj={},res0=1,ans=[],res;
for(let i=0;i<equations.length;i++){
if(!adj[equations[i][0]]){
adj[equations[i][0]]=[[equations[i][1],values[i]]];
}else{
adj[equations[i][0]].push([equations[i][1],values[i]]);
}
if(!adj[equations[i][1]]){
adj[equations[i][1]]=[[equations[i][0],Number((1/values[i]))]];
}else{
adj[equations[i][1]].push([equations[i][0],Number((1/values[i]))]);
}
}
const dfsGetVal=(st,ed,adj,map)=>{
if(st===ed){
res=res0;
return;
}
map.set(st,true);
for(let i=0;i<adj[st].length;i++){
if(!map.has(adj[st][i][0]))
{
res0*=adj[st][i][1];
dfsGetVal(adj[st][i][0],ed,adj,map);
// 回溯
res0/=adj[st][i][1];
}
}
};
// 然后进行深度优先探索找到值
for(let i=0;i<queries.length;i++){
res0=1.0;
if(!adj[queries[i][0]]||!adj[queries[i][1]]){
res=-1.0;
}else{
dfsGetVal(queries[i][0],queries[i][1],adj,new Map());
}
// console.info(res);
if(res===undefined){
ans[i]=-1.0;
}else{
ans[i]=res;
}
}
console.info(ans);
return ans;
};
图的最长路径
leetcode-310-最小高度树
=====> 无向图的最长路径:
/**
* 寻找无向图的最长路径,因为是无向图所以经过检测无法使用拓扑排序这种依赖顺序的排序
* @param n
* @param edges
*/
const longestPathUDG=(n,edges)=>{
let adj=[],leaves=[],maxLen=0,path=[];
for(let i=0;i<edges.length;i++){
if(!adj[edges[i][0]]){
adj[edges[i][0]]=[edges[i][1]];
}else{
adj[edges[i][0]].push(edges[i][1]);
}
if(!adj[edges[i][1]]){
adj[edges[i][1]]=[edges[i][0]];
}else{
adj[edges[i][1]].push(edges[i][0]);
}
}
for(let i=0;i<n;i++){
if(adj[i].length===1){
leaves.push(i);
}
}
const search=(start,adj,map,res)=>{
res.push(start);
// 判断最后一个访问的顶点是叶子节点并且它的邻接点已经被访问过了
if(adj[start].length===1&&map.has(adj[start][0])){
if(res.length>maxLen){
path=JSON.parse(JSON.stringify(res));
}
// console.info(res);
}
map.set(start,true);
for(let i=0;i<adj[start].length;i++){
if(!map.has(adj[start][i])){
search(adj[start][i],adj,map,res);
// 回溯
res.pop();
}
}
};
for(let i=0;i<leaves.length;i++){
search(leaves[i],adj,new Map(),[]);
}
return path;
};
console.info(longestPathUDG(7,[[0,1],[1,2],[1,3],[2,4],[3,5],[4,6]]));
// [6, 4, 2, 1, 3, 5]
leetcode-329-矩阵中的最长递增路径
=====> 有向图的最长路径:
本题结论:
- dfs递归可以返回值,必须有合理的返回才能再次利用返回值
- 记忆化: 对于大量重复调用的问题,缓存其结果,能降低时间复杂度
- 在用dp的时候用到依赖顺序即拓扑排序问题。(但有时想到此点并不是容易问题,必要时更推荐用方法2即记忆化的方式去解题)
/*
* 每个单元格可以看作图 G 中的一个定点。
* 若两相邻细胞的值满足 a < b,则存在有向边 (a, b)。问题转化成:
* 求有向图的最长路径长度问题
首先这道题是归类到拓扑排序条目下,但是目前想不到和拓扑排序相关的内容。
首先递增的路径可以是多个的,相当于求一组解,因此可以考虑回溯法
*/
const longestIncreasingPath = (matrix)=>{
if(matrix.length<1) return matrix.length;
let res=[],ans=0;
const check=(i,j)=>{
return i <= matrix.length - 1 && i >= 0 && j <= matrix[0].length - 1 && j >= 0;
};
const search=(matrix,i,j,flag)=>{
res.push(matrix[i][j]);
if(res.length>=1){
if(res.length>ans){
ans=res.length;
}
// console.info(res);
}
// 应该有四个方向可取
// code review
// 下方向
if (check(i+1,j)){
let ck=(matrix[i+1][j]>matrix[i][j]&&flag)||(matrix[i+1][j]<matrix[i][j]&&!flag);
if(ck){
search(matrix,i+1,j,flag);
// 回溯
res.pop();
}
}
// 上方向
if(check(i-1,j)){
let ck=(matrix[i-1][j]>matrix[i][j]&&flag)||(matrix[i-1][j]<matrix[i][j]&&!flag);
if(ck){
search(matrix,i-1,j,flag);
res.pop();
}
}
// 右方向
if(check(i,j+1)){
let ck=(matrix[i][j+1]>matrix[i][j]&&flag)||(matrix[i][j+1]<matrix[i][j]&&!flag);
if(ck){
search(matrix,i,j+1,flag);
res.pop();
}
}
// 左方向
if(check(i,j-1)){
let ck=(matrix[i][j-1]>matrix[i][j]&&flag)||(matrix[i][j-1]<matrix[i][j]&&!flag);
if(ck){
search(matrix,i,j-1,flag);
res.pop();
}
}
};
for (let i=0;i<matrix.length;i++){
for (let j=0;j<matrix[0].length;j++){
res=[];
search(matrix,i,j,true);
res=[];
search(matrix,i,j,false);
}
}
console.info(ans);
return ans;
};
/**
* 优化1:只寻找递增的路径
* @param matrix
* @returns {number|*}
*/
const longestIncreasingPath1 = (matrix)=>{
if(matrix.length<1) return matrix.length;
let ans=0;
const check=(i,j)=>{
return i <= matrix.length - 1 && i >= 0 && j <= matrix[0].length - 1 && j >= 0;
};
const search=(matrix,i,j)=>{
res.push(matrix[i][j]);
if(res.length>=1){
if(res.length>ans){
ans=res.length;
}
// console.info(res);
}
// 应该有四个方向可取
// code review
// 下方向
if (check(i+1,j)){
if(matrix[i+1][j]>matrix[i][j]){
search(matrix,i+1,j);
res.pop();
}
}
// 上方向
if(check(i-1,j)){
if(matrix[i-1][j]>matrix[i][j]){
search(matrix,i-1,j);
res.pop();
}
}
// 右方向
if(check(i,j+1)){
if(matrix[i][j+1]>matrix[i][j]){
search(matrix,i,j+1);
res.pop();
}
}
// 左方向
if(check(i,j-1)){
if(matrix[i][j-1]>matrix[i][j]){
search(matrix,i,j-1);
res.pop();
}
}
};
for (let i=0;i<matrix.length;i++){
for (let j=0;j<matrix[0].length;j++){
res=[];
search(matrix,i,j);
}
}
console.info(ans);
return ans;
};
/**
* 优化1:只寻找递增的路径
* 优化2:四个方向用数组表示使代码简洁
* dfs返回每次选取路径的长度,这样就不必占用太多空间构建数组了
* 此方法仍属于暴力深度优先搜索
* 时间复杂度:O(2^(m+n))。对每个有效递增路径均进行搜索。在最坏情况下,会有O(2^(m+n))次调用。
* 空间复杂度:O(mn)。对于每次深度优先搜索,系统栈需要 O(h) 空间,其中 h 为递归的最深深度。最坏情况下为mn
* @param matrix
* @returns {number|*}
*/
const longestIncreasingPath2 = (matrix)=>{
if(matrix.length<1) return matrix.length;
let ans=0,dir=[[-1,0],[0,1],[1,0],[0,-1]];
const check=(i,j)=>{
return i <= matrix.length - 1 && i >= 0 && j <= matrix[0].length - 1 && j >= 0;
};
const search=(matrix,i,j)=>{
let res=0;
// 应该有四个方向可取
for(let k=0;k<dir.length;k++){
if(check(i+dir[k][0],j+dir[k][1])&&matrix[i+dir[k][0]][j+dir[k][1]]>matrix[i][j]){
res=Math.max(search(matrix,i+dir[k][0],j+dir[k][1]),res);
}
}
// 返回时应该加上起点
return res+1;
};
for (let i=0;i<matrix.length;i++){
for (let j=0;j<matrix[0].length;j++){
ans=Math.max(ans,search(matrix,i,j));
}
}
console.info(ans);
return ans;
};
/**
* 优化1:只寻找递增的路径
* 优化2:四个方向用数组表示使代码简洁
* 优化3:利用数组缓存每个点的路径长度
* 时间复杂度:O(mn).每个顶点均计算且只计算一次,每条边也有且只计算一次,总时间复杂度是 O(V+E)。
* V 是顶点总数,E 是边总数。本问题中,O(V) = O(mn),O(E) = O(4V) = O(mn)。
* @param matrix
* @returns {number|*}
*/
const longestIncreasingPath3 = (matrix)=>{
if(matrix.length<1) return matrix.length;
let ans=0,dir=[[-1,0],[0,1],[1,0],[0,-1]],temp=[];
for (let i=0;i<matrix.length;i++){
temp[i]=new Array(matrix[0].length).fill(0);
}
const check=(i,j)=>{
return i <= matrix.length - 1 && i >= 0 && j <= matrix[0].length - 1 && j >= 0;
};
const search=(matrix,i,j,temp)=>{
if(temp[i][j]!==0) return temp[i][j];
// 应该有四个方向可取
for(let k=0;k<dir.length;k++){
if(check(i+dir[k][0],j+dir[k][1])&&matrix[i+dir[k][0]][j+dir[k][1]]>matrix[i][j]){
temp[i][j]=Math.max(search(matrix,i+dir[k][0],j+dir[k][1],temp),temp[i][j]);
}
}
// 返回时应该加上起点
temp[i][j]+=1;
return temp[i][j];
};
for (let i=0;i<matrix.length;i++){
for (let j=0;j<matrix[0].length;j++){
ans=Math.max(ans,search(matrix,i,j,temp));
}
}
console.info(ans);
return ans;
};
/**
* 我们注意到某个点的最长递增路径总是跟相邻的点有关系,子问题重叠,因此自然而然的就会想到动态规划
* 因此最优子结构 L(i,j)=1+Math.max(L(i-1,j),L(i,j+1),L(i+1,j),L(i,j-1))
* 并且需要判断相邻节点是否是增加关系,但是有一个问题是无法确定边界点的L长度,
* 而这种依赖其他顶点的现象又称为拓扑排序,将此题转化成拓扑排序
* 时间复杂度 : O(mn)。
* 拓扑排序的时间复杂度为 O(V+E) = O(mn) O(V+E)=O(mn)。
* V 是顶点总数,E 是边总数。
* 本问题中,O(V) = O(mn),O(E) = O(4V) = O(mn)。
* 空间复杂度 : O(mn) 我们需要存储出度和每层的叶子
* @param matrix
*/
const longestIncreasingPath4 =matrix=>{
if(matrix.length<1) return matrix.length;
let leaves=[],m=matrix.length,n=matrix[0].length,
dir=[[-1,0],[0,1],[1,0],[0,-1]],ans=0;
const check=(i,j)=>{
return i <= matrix.length - 1 && i >= 0 && j <= matrix[0].length - 1 && j >= 0;
};
// initialize degree
let degree=[];
for(let i=0;i<m;i++){
degree[i]=(new Array(n)).fill(0);
}
for(let i=0;i<m;i++){
for(let j=0;j<n;j++){
for(let k=0;k<dir.length;k++){
if(check(i+dir[k][0],j+dir[k][1])&&matrix[i][j]<matrix[i+dir[k][0]][j+dir[k][1]]){
degree[i][j]++;
}
}
}
}
// console.info(degree);
// collect which degree is 0,寻找叶子顶点,即不依赖于其他顶点的顶点
for(let i=0;i<m;i++){
for(let j=0;j<n;j++){
if (degree[i][j]===0){
leaves.push([i,j]);
}
}
}
console.info(leaves.map(item=>matrix[item[0]][item[1]]));
while(leaves.length>0){
ans++;
let newLeaves=[];
for(let i=0;i<leaves.length;i++)
{
for(let d=0;d<dir.length;d++){
let x=leaves[i][0]+dir[d][0],y=leaves[i][1]+dir[d][1];
// 此时check的却是比当前点小的点即寻找新的叶子的过程
if(check(x,y)&&matrix[leaves[i][0]][leaves[i][1]]>matrix[x][y]){
if(--degree[x][y]===0){
newLeaves.push([x,y]);
}
}
}
}
console.info(newLeaves.map(item=>matrix[item[0]][[item[1]]]));
leaves=newLeaves;
}
// console.info(ans);
return ans;
};
贪心算法
leetcode-买卖股票
贪心算法解题步骤:
- 先找问题:最大利润
- 最后决定策略是:从低点买入,到价格高点卖出,不断买卖(在保证单次利益的基础上,实现多次交易)
- 实现方法:
- 通过两层for循环,同时操作i的大小,不仅要在for循环上操作i++,还要额外在内部操作i的大小 即买股票的时机。
- 特别要注意的一点就是i和j的变化:
- 钱是相邻两位不断叠加,所以要注意更改i,j
- 假如下一位比当前小,那么我们应该直接break跳出循环就可以了,买入时机就是下个外层循环的i
买卖股票简单版(只买入卖出一次)
- 我的一个思路是找出所有可能的情况,Math.max求出最大的那一个,主体思路没错,但是嵌套循环搞起来复杂度太高了
- 发现了一个更加简单复杂度低的方法就是在一次循环中:找min 同时替换maxRes的方式
const maxProfit=arr=>{
let res=0;
let len=arr.length;
// Infinity为全局变量,表示无穷大
let min=Infinity;
for(let i=0;i<len;i++){
min=Math.min(min,arr[i]);
res=Math.max(res,arr[i]-min);
}
return res;
}
买卖股票 leetcode-123
//todo
leetcode-柠檬水找零
有两个策略:
- 有零钱就找,追求的是单次能找零
- 找零的时候先给大额钱,这样总是有足够多的零钱用来给顾客
暴露问题
这个题暴露出来的问题太多了
- while循环和shift结合 【知识点】
- 降低代码冗余度:比如
for(){
if(change-hand[i]>0){
change-=hand[i];
hand.splice(i,1);
i--
}else if(change-hand[i]===0){
change-=hand[i];
hand.splice(i,1);
hand.push(customer);
}
}
if(change!==0) return false;
降冗余===>(上面的代码有一部分产生了重复,这是不应该的)
for(){
if(change-hand[i]>=0){
change-=hand[i];
hand.splice(i,1);
i--;
}
if(change===0) break;
}
if(change!==0){
return false
}else{
hand.push(customer);
}
动态规划
leetcode-62-不同路径

- 仍然是先考虑最后一步有多少种走法:
一共两种,因为规定机器人只能向下或者向右走一步,得到- 状态转移方程 F(m,n)=F(m-1,n)+F(m,n-1)
- 最优子结构F(m-1,n),F(m,n-1)
- 边界 F(2,2)=1+1=2 F(1,m)=1 F(n,1)=1 实际上边界就是1种情况
- 对于时间复杂度,空间复杂度的思考以及优化
- 发散:杨辉三角。三角形最小路径和leetcode-120。
/**
* leetcode-62 不同路径
* typical dp: F(m,n)=F(m-1,n)+F(m,n-1);
* 运行超时,时间复杂度
* @param m
* @param n
*/
const uniquePaths0 = (m, n)=>{
let res=0;
if(m===1||n===1){
return 1;
}
return uniquePaths0(m-1,n)+uniquePaths0(m,n-1);
};
/*
* 下面是dp优化,暂存那些重复计算的部分
* 时间复杂度O(m*n) 空间复杂度O(m*n)
*/
const uniquePaths1=(m,n)=>{
let res=new Array(m);
for (let i=0;i<m;i++){
res[i]=new Array(n);
for(let j=0;j<n;j++){
if(i===0||j===0){
res[i][j]=1;
}else{
res[i][j]=res[i-1][j]+res[i][j-1];
}
}
}
// console.info(res);
return res[m-1][n-1];
};
/**
* 优化1:不需要二维数组进行暂存所有情况,只需要两个数组进行转存,就是杨辉三角
* 空间复杂度O(n)
*/
const uniquePaths2=(m,n)=>{
let temp0=new Array(n), temp1=new Array(n);
temp0.fill(1);
temp1.fill(1);
for (let i=1;i<m;i++){
for(let j=1;j<n;j++){
temp1[j]=temp1[j-1]+temp0[j];
}
temp1.forEach((item,idx)=>{
temp0[idx]=item;
});
console.info(temp0);
}
return temp0[n-1];
};
console.info(uniquePaths2(7,3));
/**
* 优化2:当前状态只需要上一行最后的状态和同行左边的状态
* 空间复杂度为O(n)
*/
const uniquePaths3=(m,n)=>{
let temp=new Array(n);
temp.fill(1);
for(let i=1;i<m;i++){
for(let j=1;j<n;j++){
temp[j]=temp[j]+temp[j-1];
}
}
return temp[n-1];
};
leetcode-42-接雨水
/**
* 当然这个题的解法很多,可以考虑一种正规的暴力解法:
* 时间复杂度为O(n^2) ,正是每个元素都会遍历一遍,并且进行向左向右查找最大值,因此时间复杂度较高
* 空间复杂度O(1)
*/
const trap1=height=>{
let ans=0,len=height.length;
for (let i=1;i<len-1;i++){
let left=0,right=0;
for(let j=i;j>=0;j--){
left=Math.max(left,height[j]);
}
for(let k=i;k<len;k++){
right=Math.max(right,height[k]);
}
// console.info(left,right);
ans+=Math.min(left,right)-height[i];
}
return ans;
};
/**
* 通过对暴力法的总结之后可以发现一个问题:总是在重复的计算左边最大,右边最大===>重复子问题
* 状态:每个item可接雨水的量 Math.min(left_max,right_max)-arr[i] 状态转移方程
* 最优子结构 left_max right_max
* 而dp在处理重复子问题上可以通过暂存的方式降低时间复杂度
* 因为只遍历了一次 T(n)=3n O(n)=n
* 空间复杂度 S(n)=2n O(n)=n
* @param height
*/
const trap2=height=>{
let res=0,left=[],right=[],len=height.length,left_max=0,right_max=0;
for(let i=0;i<len;i++){
left_max=Math.max(left_max,height[i]);
left.push(left_max);
}
for(let i=len-1;i>=0;i--){
right_max=Math.max(right_max,height[i]);
right.unshift(right_max);
}
for(let i=1;i<len-1;i++){
res+=Math.min(left[i],right[i])-height[i];
}
console.info(left,right);
return res;
};
/**
* 最后来一个终极版的代码,时间复杂度O(n)空间复杂度O(1)
* 我们已经将时间复杂度降到了O(n),空间复杂度仍有优化的空间
* 其实通过观察我们分析的表格发现0-6我们总是在用max_left来计算res,剩下的则用max_right来计算
* 因此可以只进行一次遍历即可完成对res的收集,利用双指针的方式,如果left比right小则选left,
* 但仍要维护的是max_left和max_right
* 分析图如下图2
*/
const trap3=height=>{
let res=0,left=0,right=height.length-1,max_left=0,max_right=0;
while(left<right){
if(height[left]<height[right]){
//todo 利用左边进行累加
if(height[left]>max_left){
max_left=height[left];
}
res+=max_left-height[left];
left++;
}else{
//todo 利用右边进行累加
if(height[right]>max_right){
max_right=height[right];
}
res+=max_right-height[right];
right--;
}
}
return res;
};
当然这道题并不限于以上几种方法,我的解法是通过对暴力法的简单优化,但是显然dp做起来更优雅方便。因此也能得出一条结论,做题的思路对是一方面,怎么优化又是另一方面,而从前者到后者其实是一个很大的跨度,将问题解剖图置于如下:
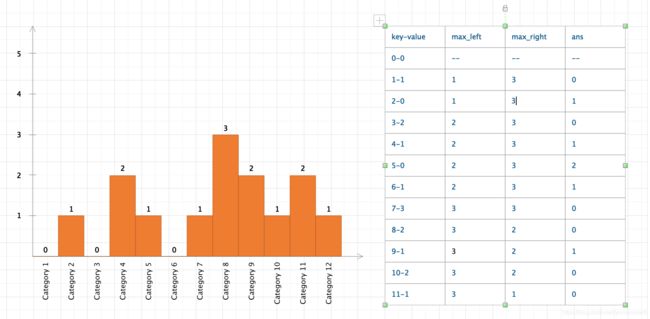
显然通过图示解剖问题,能够得到极好的思路提示和优化提示。

关于动态规划问题
references:
动态规划解题的一般思路
动态规划解题的一般思路
最近在做313超级丑数的问题时重新思考了一下为什么用dp怎么用dp的问题。
在处理313问题时,我们可以先求约数–>是否为质数–>质因数是否为primes中的数字来解决,无奈在处理这个问题时用到了大量的递归来解决求质因数的问题,尽管继续用构建最大堆的方式查找是否在primes中的方式进行优化后仍然复杂度过于高。下面我们重新从动态规划的角度考虑一下这个问题。

dp是解决什么样的问题
- 问题具有最优子结构性质。如果问题的最优解所包含的子问题的解也是最优的,那么我们就称该问题具有最优子结构性质。
- 无后效性。当前的若干个状态值一旦确定,则此后过程的演变就只和这若干个状态的值有关,和之前是采取哪种手段或经过哪条路径演变到当前的若干个状态,没有关系
- 子问题重叠。子问题本质上是和母问题一样的,只是问题的输入参数不一样,就可以称之为子问题重叠,这是动态规划解决问题的高效的本质所在,我们可以利用很多子问题具有相同的输入参数这一个性质,来减少计算量。
- dp问题的关键是将一个大问题分解成若干个子问题,找到子问题,就意味着找到了将整个问题逐渐分解的办法。
状态
用动态规划解题时,将和子问题相关的各个变量的一组取值,称之为一个“状态”。一个“状态”对应于一个或多个子问题,所谓某个“状态”下的“值”,就是这个“状态”所对应的子问题的解。
状态转移方程
定义出什么是“状态”,以及在该 “状态”下的“值”后,就要找出不同的状态之间如何迁移――即如何从一个或多个“值”已知的 “状态”,求出另一个“状态”的“值”。状态的迁移可以用递推公式表示,此递推公式也可被称作“状态转移方程”。
leetcode-5-最长回文子串问题
这是一道经典问题,有暴力法,dp, 中心扩展,Manchester算法
- 暴力法
/**
* 时间复杂度为O(N*N*N),空间复杂度为O(1)
* 时间复杂度过高,无法通过leetcode测试
*/
const longestPalindrome = s=>{
/**
* 检查是否为回文子串
* @param s
* @returns {boolean}
*/
let res='';
const testStr=s=>{
let pivot=Math.floor(s.length/2);
let idx=s.length%2!==0?pivot+1:pivot;
return s.slice(0,pivot)===s.slice(idx).split('').reverse().join('')
};
for(let i=0;i<s.length;i++){
for(let j=i+1;j<s.length+1;j++){
if (testStr(s.slice(i,j))){
if(j-i>res.length){
res=s.slice(i,j);
}
}
}
}
return res;
};
- dp
以"babad"为测试用例

/**
* dp
* 因为暴力求解的方式无法通过所有测试用例
* 利用动态规划用空间换取时间的减少,去暂存那些已经是回文串的字符串
* P[s][e]=P[s+1][e-1]&&s.charAt(s)===s.chatAt(e)
* 显然最终时间复杂度变成了O(n2) 空间复杂度也是O(n2)
*/
const longestPalindrome1=s=>{
let length=s.length;
let P=new Array(length),res="";
/**
* js 语法需要预设数组的内容
*/
for(let prev=0;prev<length;prev++){
P[prev]=new Array(length);
}
for(let len=1;len<=length;len++){
for(let start=0;start<length;start++){
let end=start+len-1;
if(end>=length) break;
// 长度为 1 和 2 的单独判断下
P[start][end] = (len === 1 || len === 2 || P[start + 1][end - 1]) && s.charAt(start) === s.charAt(end);
if (P[start][end] && len > res.length) {
res = s.slice(start, end + 1);
}
}
}
return res;
};
- 中心扩展法
/**
* 第三种方法是采用从中间向两边进行扩散的方式来确定字符串是否为回文串
* 关键点在于奇数个数的子串和偶数个数的子串都要去验证避免出现遗漏的现象
* 时间复杂度O(n2) 空间复杂度O(1)
* @param str
*/
const longestPalindrome2=str=>{
const expandAroundCenter=(s,left,right)=>{
let L=left,R=right;
while(L>=0&&R<s.length&&s.charAt(L)===s.charAt(R)){
L--;
R++;
}
// 注意此处的R L已经是加过,减过的数了
return R-L-1;
};
if(!str||str.length<1) return "";
let start=0,end=0;
for(let i=0;i<str.length;i++){
// 判断奇数子串问题
let len1=expandAroundCenter(str,i,i);
// 判断偶数子串问题
let len2=expandAroundCenter(str,i,i+1);
let len=Math.max(len1,len2);
if(len>end-start){
start = i - Math.floor((len - 1) / 2);
end = i + Math.floor(len / 2);
}
}
return str.substring(start,end+1);
};
Manchester算法
references:
对称字符串的最大长度 — 曼彻斯特算法
/**
* Manchester算法
* @param str
*/
/**
* 解决最长回文子串问题,采用Manchester算法
* key1:将原字符串进行变形,插入#,此时字符串变成了绝对奇数个
* key2:定义辅助数组P[]保存以当前字符为中心的回文串的半径长度
* key3:定义中心C,最右边界R,P[i]=R-i,P[i]取决于R-i和与i对称的点的位置的P[x]大小,为了防止i_mirror不在我们取最小值
* 2*P[i]+1 是新串中以nStr[i]为中心的回文子串的长度L,同时(L-1)/2是原串中回文子串的长度即为P[i]
* 思考时间复杂度:虽然有while循环,但是事实上每个节点都只访问了一次 O(n)
*/
const process=str=>{
let res='^';
if(str.length===0) return '^$';
for(let i=0;i<str.length;i++){
res+=`#${str[i]}`;
}
return res+'#$';
};
const longestPalindrome3=str=>{
let nStr=process(str);
let C=0,R=0,P=new Array(nStr.length);
for(let i=0;i<nStr.length;i++){
let i_mirror=2*C-i;
if(R>i){
// 防止超过R
P[i]=Math.min(R-i,P[i_mirror]);
}else{
P[i]=0;
}
//console.info(nStr[i+1+P[i]],nStr[i-1-P[i]]);
while(nStr[i+1+P[i]]===nStr[i-1-P[i]]){
P[i]++;
}
/**
* update R C
*/
if(i+P[i]>R){
C=i;
R=i+P[i];
}
}
let maxLen=0,id=0;
for(let i=0;i<P.length;i++){
if (P[i]>maxLen){
maxLen=P[i];
id=i;
}
}
// console.info(P);
let start=Math.floor((id-maxLen)/2);
return str.slice(start,start+maxLen);
};
递归
本质:每个处理过程都是相同的,输入和输出是相同的,处理次数未知
leetcode-复原IP地址
一上来这个思路就错了,不应该是分割字符串的思路,因为255是最大的肯定就三个占满,
- IP有四段,每段0-255,因此可以用递归
递归处理的三个关键:
- 有输入
- 有输出
- 有边界条件处理
- 重点:不是一定要return,所以重新调用递归的时候也不是一定要return recurrence()
leetcode-112-二叉树路径之和
参考上面递归的特点,但是在这道题上没有解出来的原因是
- 路径可以走左树,也可以走右树,怎么确定最后的值–>当时一开始想用Array.every解决,但是其实最终只要对比两个布尔值就可以
- 路径可以走了左树又走右树,怎么解决–>递归是最好的解决方案
- 既然用递归边界条件怎么处理
const hasPathSum = (root, sum) => {
let res0=false,res1=false;
if (!root) return false;
// 边界条件处理的过于混乱
// if (sum===0&&!root.left&&!root.right) return false;
// if(root.val>=sum) return true;
if (!root.left && !root.right) {
return sum === root.val;
}
if (root.left) {
res0=hasPathSum(root.left, sum - root.val);
}
if (root.right) {
res1=hasPathSum(root.right, sum - root.val);
}
return res0||res1;
};
leetcode-101-对称二叉树
判断一个二叉树是否为对称二叉树。一开始我的思路是利用中序遍历后的值来查看,发现在leetcode上跑不通.原因不明,遍历的时候会将为null的值过滤掉,但是在本地跑却没有任何问题。然后思考可以用递归的方式实现。
理由如下:总是在重复同一个过程,有输入 有输出 有边界条件,因此可通过递归来解决这个问题:为null的情况,有值进行对比的情况。
leetcode-98-验证二叉搜索树
读题时出现了一个比较严重的错误:对题意出现了误解,导致无法通过测试用例。题目可以通过递归来实现,也可以通过变种为二叉树的遍历来实现。
下面介绍一种比较厉害的递归方式:
// 从我的角度来看这段代码并不能够一看到题目就能领会到这种解题方法,因为没有校验左树比根节点小的操作。
const isValidBST = (root)=>{
let lst=-Number.MAX_SAFE_INTEGER;
let isValidBST0=root=>{
if(root===null) return true;
if (isValidBST0(root.left)){
if(lst<root.val){
lst=root.val;
return isValidBST0(root.right);
}
}
return false;
};
return isValidBST0(root);
};
leetcode-980-不同路径(3)
首先分析一下这个题的思路:
- 必须经过所有网格===>路径长度应该是确定的,作为标志位之一。(重点)
- 某一个网格为起点时,它有上左下右四种移动方式。(重点)
- 边界条件是什么:路径长度确定,且起始点即为终止点。
总结-分治-dp-贪心
references:
分治法、动态规划、贪心算法区别
分治法
特征:
将原问题划分成若干个规模较小而结构与原问题相似的子问题,递归的解决这些子问题,然后再合其结果,就得到原问题的解。
解决什么样的问题:
- 该问题的规模缩小到一定的程度就很容易解决
- 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质
- 利用该问题分解出的子问题的解可以合并为该问题的解
- 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子问题
求解步骤:
- 将问题划分为互不相交的子问题。
- 递归的求解子问题。
- 组合子问题的解,求出原问题的解。
关于分治算法的总结参考我的另一篇博客:
详解分治算法
动态规划
特征:
与分治法相似,也是通过组合子问题的解而解决整个问题。区别是,动态规划适用于分解得到的子问题往往不是相互独立的。在这种情况下如果采用分治法,有些子问题会被重复计算多次,动态规划通过记录已解决的子问题,可以避免重复计算。(在必要的情况下记录重复的子问题的值。)
解决什么样的问题:
- 主要解决的问题的特征是:求解最优化问题,在这类问题中可能有多个可行解,最终得到的是其中一个最优解
- 最优子结构
- 无后效性
- 子问题重叠
求解步骤:
dp问题的解决通常通过递归来实现。
- 描述最优解的结构(找状态转移方程)
- 递归定义最优解的值(求最优子结构)
- 按自底向上的方式计算最优解的值
- 由计算出的结果构造一个最优解的值
dp到斐波那契数列
/**
* 前段时间已经写过关于一个铺地砖问题的答案,实际上就是斐波那契数列
* 而dp的关键是什么:有状态 有状态转移方程 有重叠的子问题 有边界
* 下面就写一下fib数列,同时通过一个中间数组保存每一个子问题的值,避免重复计算
*/
const fib = n => {
let res = [0, 1, 1];
if (n === 1 || n === 2) return res[n];
for (let i = 3; i <= n; i++) {
res.push(res[i - 1] + res[i - 2]);
}
console.info('fib===>',res);
return res[n];
};
console.info(fib(4));
console.info(fib(5));
贪心算法
特征:
通过做一系列的选择来给出某一问题的最优解,对算法中的每一个决策点,做一个当时(看起来)是最优的选择。这种启发式的策略并不是总能产生出最优解。
解决什么样的问题:
要素:贪心选择性质、最优子结构性质
贪心选择性质:一个全局最优解可以通过局部最(贪心)选择来达到。
求解步骤:
- 将优化问题转化成这样的一个问题,即先做出选择,在解决剩下的一个子问题
- 证明原问题总是有一个最优解是做贪心选择得到的,从而说明贪心选择的安全性
- 说明在作出贪心选择后,剩余的子问题具有这样一个性质。即如果将问题的最优解和我们所做的贪心选择联合起来,可以得出原问题的一个最优解。
leetcode84-柱状图中最大的图形
leetcode85-最大矩形
求二维01矩阵中最大矩形的问题可以转换为求柱状图中最大图形的问题。那么我们主要从第84题的角度来看看该类题适合用什么方法来做。
-
首先肯定我们把柱状图的规模缩小之后就会发现问题很容易解决了,通过求出可能的矩形,不停的找比当前值大的即可。
-
那么思考一下:子问题是否有重叠?是的,就拿下图来看:

只要56存在于子问题中,那么它就是最大的矩形,因此这是重叠的,每个子问题都重新求解一遍时会存在重复。
钢条分割问题
references:
算法导论笔记动态规划DP详解-钢条切割的分析与实现
/**
*问题描述,给定一个数组,表示的是出售长度为i的钢条的价格。如p = [1, 5, 8, 9, 10, 17, 17, 20, 24, 30]
* 表示的是长度为1的钢条为1美元,长度为2的钢条为5美元,以此类推。
* 现在有一个钢条长度为n,那么如何切割钢条能够使得收益最高,切割的时候不消耗费用。来源于算法导论15.1。
*/
对于这个问题其实可以归结为一个 dp问题:
满足最优子结构
子问题重叠
无后效性
const biggestProfit=(len,p)=>{
let res=0;
if (len<1) return res;
if (len===1) return p[0];
if (len<=p.length){
res=p[len-1];
}
for (let i=1;i<=Math.floor(len/2);i++){
if (biggestProfit(len-i,p)+biggestProfit(i,p)>res){
res=biggestProfit(len-i,p)+biggestProfit(i,p);
// console.info(biggestProfit(len-i,p),biggestProfit(i,p));
}
}
return res;
};
而朴素的递归方法正式在求解该问题的子问题时总是有重复计算的地方。而使用dp是通过用一个备忘把计算过的值存储下来。
如下图所示为朴素递归的方式:

const big=(len,p)=>{
let res=[0],s=[0],sRes=[];
let temp;
for (let i=1;i<=len;i++){
temp=-(Infinity);
for (let j=1;j<=i;j++){
// 思考这里:将问题分解成了p[j-1]+res[i-j]
// 那么其实是将钢条分成两端 一段不再切割 一段切割后求最大值
// 那么会想一段不切割的话这种方式并不一定得到最优解啊,但是因为for循环遍历了所有的可能,(因此双重for循环是必要的一层检测)
// 所以总是能找到最优解的
//temp=Math.max(temp,p[j-1]+res[i-j]);
if (p[j-1]+res[i-j]>temp) {
temp = p[j - 1] + res[i - j];
s[i]=j;
}
}
res[i]=temp;
}
let len0=len;
while(len0>0){
sRes.push(s[len0]);
len0=len0-sRes[sRes.length-1];
}
return `max:${res[len]},组合为:${sRes}`;
};
二分查找法
关于二分查找法的详解可以参考我的另一篇文章:详解二分查找法
leetcode-4-寻找两个有序数组的中位数
是一个比较难的题,值得推敲,以及怎么去二分
left_part | right_part
A[0], A[1], ..., A[i-1] | A[i], A[i+1], ..., A[m-1]
B[0], B[1], ..., B[j-1] | B[j], B[j+1], ..., B[n-1]
此时我们只需要知道两个数组的长度之和是奇数还是偶数即可:
可以总结出规律:
- 在m+n为偶数情况下i-1-0+1+j-1-0+1=m-1-i+1+n-1-j+1===>i+j=m+n-i-j i+j=(m+n)/2
如果m+n为奇数呢?
- 在m+n为奇数情况下:如果我们取左边最大值为中位数则i+j=(m+n+1)/2
- 在m+n为奇数情况下:如果我们取右边最小值为中位数则i+j=(m+n-1)/2 - - 因此为了统一两种情况,可以都归纳为
i+j=Math.floor((m+n-1)/2)i+j=Math.ceil((m+n-1)/2) - 并且满足 A[i-1]<=B[j]&&B[j-1]<=A[i]
同时 i和j之间的关系是怎样的呢:
i+j=m-i+n-j( or m-i+n-j+1)======>j=(m+n+1)/2-i,i=(0,...逐渐移动)
// 同时确保
A[i-1]<=B[j]
B[j-1]<=A[i]
鉴定条件:
if (i < ed && B[j-1] > A[i]){
iMin = i + 1; // i is too small
}
else if (i > st && A[i-1] > B[j]) {
iMax = i - 1; // i is too big
}
边界条件处理:
// 处理AB左侧无值或者右侧无值的情况下如何计算中位数
/**
* 先考虑如果不去计较时间复杂度的大小,如何确定中位数呢
* 通过以其中最长的数组为基准向数组中插入短数组数据的方式确定排序好的数组,最终确定中位数
* 时间复杂度为O(m+n)最差的情况下两个数组都需要遍历一遍
* @param A
* @param B
*/
const findMedianSortedArrays=(A,B)=>{
let sum=A.length+B.length;
if (A.length===B.length&&sum===2){
return (A[0]+B[0])/2
}
const sortAB=(a,b)=>{
let j=0;
for(let i=0;i<b.length;i++){
for(let k=j;k<a.length-1;k++){
if (k===0&&a[k]>=b[i]){
a.unshift(b[i]);
j=k;
break;
}else if(a[k]<=b[i]&&a[k+1]>=b[i]){
// console.info('k',k);
a.splice(k+1,0,b[i]);
j=k+1;
break;
}else{
j=k;
}
}
if(a.length<sum&&j+1===a.length-1&&a[j+1]<=b[i]){
a=a.concat(b.slice(i));
break;
}
}
return a;
};
if(A.length>=B.length){
A=sortAB(A,B);
}else{
A=sortAB(B,A);
}
console.info(A);
let len=A.length;
return len%2===0?(A[len/2]+A[len/2-1])/2:A[Math.floor(len/2)];
};
/**
* 其实上述的代码仍然具有冗余,首先不一定以长数组为基准进行插入,可以用任意一个数组作为基准
* 假如以B为基准向B中插入数据
*/
const findMedianSortedArrays0=(A,B)=>{
let j=0;
for(let i=0;i<A.length;i++){
while(j<B.length){
if (B[j]>=A[i]){
B.splice(j,0,A[i]);
j++;
break;
}else if(j===B.length-1&&B[j]<A[i]){
B.push(A[i]);
j++;
break;
}else{
j++;
}
}
}
if(B.length===0){
B=A;
}
let len=B.length;
return len%2===0?(B[len/2]+B[len/2-1])/2:B[Math.floor(len/2)];
};
/**
* 以上的问题解法显然不符合题目要求的时间复杂度,因此有必要通过二分法来解决这个问题
* @param A
* @param B
*/
const findMedianSortedArrays1=(A,B)=>{
// make sure A.length
if(A.length>B.length){
let temp=A;
A=B;
B=temp;
}
let m=A.length,n=B.length;
// start binary-search,build start and end
let st = 0,ed=m;
while(st<=ed){
let i=Math.floor((st+ed)/2);
// to avoid m+n is odd
let j=Math.floor((m+n+1)/2)-i;
// case 1' 只是鉴于st可以等于ed的缘故,判断一下是否i就是st,如果不判断亦可
if(i>st&&A[i-1]>B[j]){
// binary search directly
// i is too big
ed=i-1;
// case 2'
}else if(i<ed&&B[j-1]>A[i]){
// i is too small
st=i+1;
}else{
let maxLeft=0;
if(i===0){
maxLeft=B[j-1];
}else if(j===0){
maxLeft=A[i-1];
}else{
maxLeft=Math.max(A[i-1],B[j-1]);
}
let minRight = 0;
if (i === m){
minRight = B[j];
}else if (j === n) {
minRight = A[i];
}else {
minRight = Math.min(B[j], A[i]);
}
return (m+n)%2===0?(maxLeft+minRight)/2:maxLeft;
}
}
};
leetcode-29-两数相除
总结:
- 处理边界过程中可以用测试用例去捋一下最终结果,如果答案介于res和res+1之间要去处理一下边界条件,review代码使代码更合理和简洁
- 二分思想能很好的降低时间复杂度,但是难点在于如何合理的进行二分判断
- 类似问题参考:leetcode-50-pow(x, n)
const divide = (dividend, divisor)=>{
if(dividend===0) return 0;
if(divisor===1) return dividend;
if(divisor===-1) {
if(-dividend>Math.pow(2,31)-1||-dividend<-Math.pow(2,31)){
return Math.pow(2,31)-1;
}
return -dividend;
}
let sign=1;
// check +-
if((dividend<0&&divisor>0)||(dividend>0&&divisor<0)){
sign=-1;
}
dividend=dividend>0?dividend:-dividend;
divisor=divisor>0?divisor:-divisor;
const div=(a,b)=>{
if(a<b) return 0;
let count=1,tb=b;
while((tb+b)<a){
count+=1;
tb+=b;
}
// key: 如果不递归,往往求的值是在count和count+1之间浮动,
// 相当于需要把头部代码重新写一遍,因此递归即可
return count+div(a-tb,b);
};
let res=div(dividend,divisor);
if(sign>0){
return res>Math.pow(2,31)?Math.pow(2,31)-1:res;
}else{
return -res;
}
};
/**
* optimize1:加快步伐
* @param dividend
* @param divisor
* @returns {number|*}
*/
const divide1 = (dividend, divisor)=>{
if(dividend===0) return 0;
if(divisor===1) return dividend;
if(divisor===-1) {
if(-dividend>Math.pow(2,31)-1||-dividend<-Math.pow(2,31)){
return Math.pow(2,31)-1;
}
return -dividend;
}
let sign=1;
// check +-
if((dividend<0&&divisor>0)||(dividend>0&&divisor<0)){
sign=-1;
}
dividend=dividend>0?dividend:-dividend;
divisor=divisor>0?divisor:-divisor;
/**
* 加快收缩的进程
* @param a
* @param b
* @returns {number|*}
*/
const div=(a,b)=>{
if(a<b) return 0;
let count=1,tb=b;
while((tb+tb)<a){
count+=count;
tb+=tb;
}
return count+div(a-tb,b);
};
let res=div(dividend,divisor);
if(sign>0){
return res>Math.pow(2,31)?Math.pow(2,31)-1:res;
}else{
return -res;
}
};
有序数组被截断后寻找旋转点
接下来两道题非常的有意思,有重复元素的数组相对寻找起来更加困难,但究其根本也不过是移动指针。那么在logN的时间复杂度内寻找到旋转点的关键是什么呢?
- 最后一位大于第一位的情况一定是升序没有旋转的,因此应该返回0;
arr[mid]>arr[mid+1]是判断该点是不是旋转点的根本arr[mid]>arr[left]是一种正常的情况,应该移动leftarr[mid]arr[mid]===arr[left]??此时应该是移动left:为什么呢?因为我们取mid时用的floor,如果移动right根据代码流程会跳过旋转点
const find=arr=>{
let left=0,right=arr.length-1;
if (arr[right]>arr[left]){
// 此时没有旋转,也就是说旋转索引为0
return 0;
}
while(left<=right){
let mid=Math.floor((left+right)/2);
// 依靠判断后一位是否比当前位的值大来决断是否位旋转点
// mid+1一定存在,因为我们mid取的是floor
if (arr[mid]>arr[mid+1]){
return mid;
}else {
// 难点+:和开头的判断一样
if(arr[mid]<arr[left]){
right=mid-1;
}else{
left=mid+1;
}
}
}
};
console.info(find([3,4,5,6,7,0,1,2])); // 4
leetcode-33-搜索旋转排序数组
总结:
- 题目要求时间复杂度是log(N),显然要用到二分查找的方法,但是不满足二分查找的硬性条件,因此应该没有条件创造条件:查找旋转点
- 题目要求时间复杂度是log(N):因此此时查找旋转点的时候也用二分查找法即可,这个地方区别于普通的二分查找法
- 利用二分法寻找旋转点是一个难点:很难想到这种拆分的方式
- 难点+:在代码中标注部分为什么我们不可以通过对比右半部分呢即
nums[mid]>nums[right]来判断呢?当然可以,但是限于这个问题我们通过Math.floor来取中间值,所以右边界不能每次都让mid-1需要保留mid以避免丢失判断项。但是我们一般不采用这种方式的原因是:前面判断mid与mid+1已经默认右边暂时符合条件
- 难点+:在代码中标注部分为什么我们不可以通过对比右半部分呢即
/**
* 假设按照升序排序的数组在预先未知的某个点上进行了旋转。
( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
搜索一个给定的目标值,如果数组中存在这个目标值,则返回它的索引,否则返回 -1 。
你可以假设数组中不存在重复的元素。
你的算法时间复杂度必须是 O(log n) 级别。
输入: nums = [4,5,6,7,0,1,2], target = 0
输出: 4
首先我们知道如果利用二分查找,那么时间复杂度符合要求,但是该数组不是严格有序
那么为了符合条件,其实有一个很巧妙的方法,就是利用二分查找法找到旋转点
* @param nums
* @param target
*/
const search = (nums, target)=>{
const find=arr=>{
let left=0,right=arr.length-1;
if (arr[right]>arr[left]){
// 此时没有旋转,也就是说旋转索引为0
return 0;
}
while(left<=right){
let mid=Math.floor((left+right)/2);
// 依靠判断后一位是否比当前位的值大来决断是否位旋转点
// mid+1一定存在,因为我们mid取的是floor
if (arr[mid]>arr[mid+1]){
return mid;
}else {
// 和开头的判断一样
if(arr[mid]<arr[left]){
right=mid-1;
}else{
left=mid+1;
}
}
}
};
const search0=(left,right)=>{
while(left<=right){
let mid=Math.floor((left+right)/2);
if(nums[mid]===target){
return mid;
}else if(nums[mid]>target){
right=mid-1;
}else if(nums[mid]<target){
left=mid+1;
}
}
return -1;
};
if(nums.length===0){
return -1;
}else if(nums.length===1){
return nums[0]===target?0:-1;
}
let rotate=find(nums);
// console.info(find(nums));
if(nums[rotate]===target){
return rotate;
}else{
let a=search0(0,rotate);
let b=search0(rotate+1,nums.length-1);
if(a===-1&&b===-1){
return -1;
}else if(a===-1){
return b;
}else{
return a;
}
}
};
leetcode-81-搜索旋转排序数组 II
和33题的区别是数组中有了重复的元素,因此相对于原来的代码也就有了移动left right的操作。
总结:
因为javascript是动态变量类型的语言,即运行时确定数据类型,因此必须用Math.floor或者Math.ceil控制mid大小
- key1: 不能让mid和left一样的时候移动left,不然此时会发生像[3,1]这种无法通过的情况
- key2: arr[mid]=arr[left]的情况要移动left而不是移动right
const search = (nums, target)=>{
if(nums.length===0) return false;
if(nums.length===1) return nums[0]===target;
const find=arr=>{
let left=0,right=arr.length-1;
while(left<=right){
let mid=Math.floor((left+right)/2);
// 因为mid取的是floor
if(arr[mid]===arr[left]&&mid!==left){
// key1: 不能让mid和left一样的时候移动left,不然此时会发生像[3,1]这种无法通过的情况。究其原因是mid取floor的缘故
left+=1;
continue;
}
if(arr[mid]===arr[right]){
right-=1;
continue;
}
if(arr[mid]>arr[mid+1]){
return mid;
}else {
if (arr[mid] >= arr[left]) {
// key2: arr[mid]=arr[left]的情况要移动left而不是移动right。究其原因是mid取floor的缘故
left=mid+1;
} else {
right = mid - 1;
}
}
}
return left;
};
const search0=(left,right)=>{
while(left<=right){
let mid=Math.floor((left+right)/2);
if(nums[mid]===target){
return true;
}else if(nums[mid]>target){
right=mid-1;
}else{
left=mid+1;
}
}
return false;
};
let idx=find(nums);
console.info('idx',idx);
return (search0(0,idx)||search0(idx+1,nums.length-1));
};
leetcode-69-x 的平方根-++牛顿迭代法++
总结:
牛顿迭代法在求解平方根和最优化问题上得到广泛应用。
主要迭代关系式如下:
![]()
推导过程如下:

/**
* 首先利用二分法来寻找问题的答案,
* 结合以前几道做过的题目进行过的总结可以知道:
* 如果存在target则返回正好合适的mid值,如果不存在
* left就是待插入位置的索引,right比left小1
* 当然:以上mid的选取都是取的floor,在极少数的情况下我也用过ceil,无论哪一种都要仔细分析一下边界以免发生错误
* 应用到这个题中就是返回right值即可
* 时间复杂度:O(logN)
* 空间复杂度:O(1)
* @param x
*/
const mySqrt = (x)=>{
if(x===1||x===0) return x;
let left=0,right=Math.floor(x/2);
while(left<=right){
let mid=Math.floor((left+right)/2);
if(mid*mid===x){
return mid;
}else if(mid*mid>x){
// mid is too big
right=mid-1;
}else if(mid*mid<x){
left=mid+1;
}
}
// console.info('left===>',left,right);
return right;
};
/**
* 牛顿迭代法:Newton's method
* https://baike.baidu.com/item/%E7%89%9B%E9%A1%BF%E8%BF%AD%E4%BB%A3%E6%B3%95/10887580?fr=aladdin
* 牛顿迭代法是求方程根的重要方法之一,其最大优点是在方程 的单根附近具有平方收敛,
* 而且该法还可以用来求方程的重根、复根,此时线性收敛,但是可通过一些方法变成超线性收敛。
* 首先知道一阶泰勒展开公式f(x)=f(x0)+f'(x0)(x-x0)
* 将f(x)=x^2-a代入即可得到x=(x0+a/x0)/2 即得到了迭代关系式即:x1=(x0+a/x0)/2,x2=(x1+a/x1)/2
* 迭代变量即为x
* 迭代跳出为是否x*x为a
* @param x
* @returns {number}
*/
const mySqrt0=x=>{
let a=x;
while(x*x-a>1-Number.EPSILON){
// x=Math.floor((x+a/x)/2);
// 以下如果while判断为x*x>a会陷入死循环,比如取值5,那么x总是无限逼近√5且一直比a大而不跳出循环
// 因此为了避免进入死循环,将判断条件改为x*x-a>1-Number.EPSILON
// Number.EPSILON 属性表示 1 与Number可表示的大于 1 的最小的浮点数之间的差值。2^(-52)
x=(x+a/x)/2;
// console.info(x);
}
// console.info(x);
return (Math.floor(x));
};
排序算法的应用
references:
排序算法的应用-leetcode
数学问题的转换
关于数学问题的转换也是在算法题中常见的一种巧妙的解决问题的方法,比如说如何不使用中间变量交换两个数字可以通过如下数学方法解决
a=a+b;
b=a-b;
a=a-b;
a=a*b;
b=a/b;
a=a/b;
leetcode-621任务调度器
因为题目只需要求得最短时间,因此将题目转化为数学问题最为简单,复杂度也低。
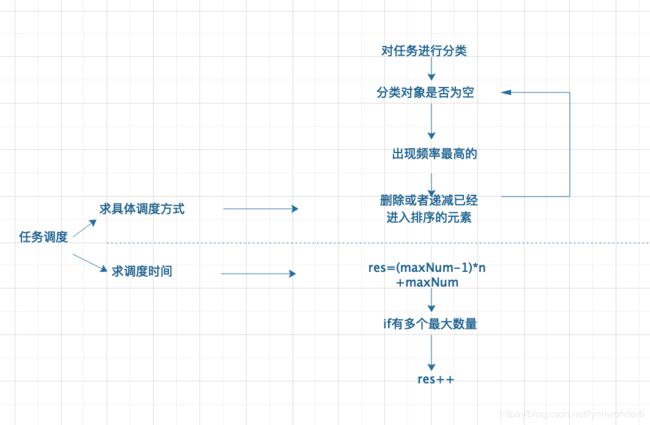
以下是部分核心代码
str.padEnd(len,str0),在str后面用str0补全使其长度为len
相应的还有str.padStart()
const leastInterval = (tasks, n)=>{
let obj={};
let res='';
if (tasks.length<1) return res;
tasks.forEach(item=>{
if(!obj[item]){
obj[item]=1;
}else{
obj[item]++;
}
});
/* 我所无法决定的点是如何排序这个obj对象,然后如何把待命给加进去,如何知道ab完之后继续进行a呢?
* 三个问题的解决方式是通过遍历的方式找到出现频率最大的,利用字符串的补齐API,利用参数n进行分组每组长度为n+1
*/
while(JSON.stringify(obj)!=="{}")
{
let temp=[];
let tempObj=JSON.parse(JSON.stringify(obj));
for(let i=0;i<n+1;i++){
if (JSON.stringify(tempObj)==="{}") break;
let keys=Object.keys(tempObj);
let maxKey=keys[0];
let maxVal=tempObj[maxKey];
for (let i=1;i<keys.length;i++){
if (obj[keys[i]]>maxVal){
maxVal=obj[keys[i]];
maxKey=keys[i];
}
}
temp.push(maxKey);
if (obj[maxKey]===1){
delete(obj[maxKey]);
}else{
obj[maxKey]--;
}
delete(tempObj[maxKey]);
}
res+=temp.join('').padEnd(n+1,'0');
}
res=res.replace(/0+$/,'');
return res.length
};
leetcode-9-回文数
/**
* 回文数,正着反着都一样
* 首先最简单的就是转成字符串来判断是否为回文字符串
*/
const isPalindrome = (x)=>{
let s=x.toString();
let pivot=Math.floor(s.length/2);
let idx=s.length%2!==0?pivot+1:pivot;
return s.slice(0,pivot)===s.slice(idx).split('').reverse().join('')
};
/**
* 思考能不能不转为字符串进行判断是否为回文数
* 参考官方题解:
* 负数首先排除
* 同时考虑到大整数溢出的问题,我们只去翻转一半的原数字
* 如何判断我们已经翻转了一半呢,比如122/10=12<=12*10即此时提前到达了中间数
* 同时记得奇数个数的回文数,最后判断的时候跳过中间位即可
*/
const isPalindrome1=x=>{
if(x<0||x%10===0&&x!==0){
return false;
}
let reverse=0;
while(x>reverse){
reverse=reverse*10+x%10;
x=Math.floor(x/10);
}
return x===reverse||x===Math.floor(reverse/10);
}
计算时间复杂度和空间复杂度
从二叉树的前序遍历和中序遍历还原出二叉树这个问题总结分治法计算复杂度的一种方式
主定理(master theorem)
在计算机科学中,分治法是建基于多项分支递归的一种重要的算法范式。
references:
Master theorem (analysis of algorithms)
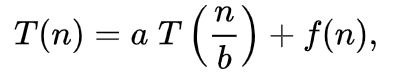
nis the size of an input problem
ais the number of subproblems in the recursion
b is the factor by which the subproblem size is reduced in each recursive call

const buildTree = (preorder, inorder) => {
if (preorder.length <= 0 || inorder.length <= 0) {
return null;
}
let root = preorder[0];
let node = new TreeNode(root);
let idx = inorder.indexOf(root);
node.left = buildTree(preorder.slice(1, idx + 1), inorder.slice(0, idx));
node.right = buildTree(preorder.slice(idx + 1), inorder.slice(idx + 1));
// console.info(node);
return node;
};
-
从以上这段代码来看
T(n)=2T(n/2)+n^0即a=2,b=2,c=0此时Ccrit=1>C=0满足第一种case:因此时间复杂度O(n)=n^Ccrit=n. -
空间复杂度:
O(n),存储整棵树的开销.