Python学习笔记之EXCEL文档操作
一、基本概念
我们使用python对excel文档进行读写操作时,需要知道下面基本概念:
# 工作薄:workbook
# 工作表:sheet
# 活动表: 打开工作薄默认所在的工作表;
# 列(column):A B C D E
# 行(row): 1 2 3 4 5 6
# 单元格(cell)二、工作簿、工作表、单元格的基本操作
import openpyxl
#读取excel文档,生成一个工作簿对象
wb = openpyxl.load_workbook('/root/PycharmProjects/day14/example.xlsx')
#wb一个workbook对象,有点类似文件对象
print(wb,type(wb))
#2.以列表的形式返回工作博中的工作表名称
print(wb.sheetnames)
#3.返回一个worksheet对象,返回当前活动表
print(wb.active)
#4.工作表sheet的属性
sheet = wb['example'] #创建一个工作簿中名为example的工作表的对象
print(sheet.max_column) #指定工作表的列数
print(sheet.max_row) #指定工作表的行数
print(sheet.title) #返回指定工作表的名字
sheet.title = 'example' #修改指定工作表的名字,想要生效,还需要对工作薄进行保存
print(sheet.title)
#5.获取工作表中单元格的信息
#sheet[\'A1\'] 是一个单元格对象
print('sheet:',sheet ,' ','sheet[\'A1\']:',sheet['A1'],' ','sheet[B1].value:',sheet['B1'].value)
cell = sheet['B1']
print(cell.row,' ** ',cell.column)
print(sheet.cell(row = 3 , column = 2))
print(sheet.cell(row = 3 , column = 2).value)
#我们可以对单元格的值进行更改
sheet.cell(row = 3 , column = 2).value = 'xiaomi'
print(sheet.cell(row = 3 , column = 2).value)
wb.save(filename='/root/PycharmProjects/day14/eample.xlsx') #保存工作薄,即前面的修改生效输出:
['example', 'Sheet2', 'Sheet3']
3
7
example
example
sheet: sheet['A1']: sheet[B1].value: Apples
1 ** B
|
Pears
xiaomi | | 原表格:

更改后的表格:

三、excel表的内容的排序读写
(一)、对表格的内容进行排序
读取上面的表格,并根据C列的信息从小到大进行排序。
import os
import openpyxl
def ReadWb(wbname,sheetname = None):
"""
:param wbname: 被读取内容的工作簿
:param sheetname: #工作簿的哪一张工作表
:return:
"""
wb = openpyxl.load_workbook(wbname)
if sheetname == None:
sheet = wb.active
else:
sheet = wb[sheetname]
all_infor = []
for row in sheet.rows:
child=[cell.value for cell in row]
all_infor.append(child)
return sorted(all_infor, key=lambda item: item[2])
def CreateWorkBook(filename):
"""
创建一个新的工作簿
:param filename: 新建的工作簿的名称(可以添加绝对路径)
:return:
"""
pwd = os.path.split(filename)
if not pwd[1].endswith('.xlsx'):
new_filename = pwd[1]+'.xlsx'
else:
new_filename = pwd[1]
wb = openpyxl.Workbook(new_filename)
wb.save(pwd[0]+os.path.sep+new_filename)
print("新建Excel[%s]成功!" % (pwd[0]+os.path.sep+new_filename))
def save_to_excel(data,wbname,sheetname = 'Sheet1'):
"""
将数据写入指定的excel表中
:param data: 数据
:param wbname: 新的excel工作薄
:param sheetname: 指定的工作表的名称
:return:
"""
CreateWorkBook(wbname)
wb = openpyxl.load_workbook(wbname)
sheet = wb.active
sheet.title = sheetname
#,枚举返回对象和对象当前的索引
for row ,item in enumerate(data):
for column ,cellValue in enumerate(item):
#sheet.cell是工作表的一个单元格进行操作,row,column代表了行和列值
sheet.cell(row = row+1,column = column+1,value = cellValue)
wb.save(filename=wbname)
print('保存成功')
sorted_info = ReadWb('/root/PycharmProjects/day14/example.xlsx')
save_to_excel(sorted_info,'/root/PycharmProjects/day14/sorted_eample.xlsx')输出:
新建Excel[/root/PycharmProjects/day14/sorted_eample.xlsx]成功!
保存成功排序后的表格:
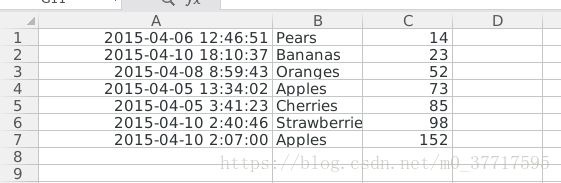
(二)、对表格的内容进行更新
现在有一个约23000行的表格,表格的表头信息如下图,现在需要将下面几个产品的价格进行更改,
Celery=1.22, Garlic=3.70,Lemon =1.78

思路,将需要更改价格的商品与其更改的价格作为一个字典,按行遍历整个excel表,如果产品名在字典
里面,那么就对改行产品的价格进行更改。
import openpyxl
price_update= {
'Celery':1.22,
'Garlic':3.70,
'Lemon' :1.78
}
filename = '/root/PycharmProjects/day14/produceSales.xlsx'
wb = openpyxl.load_workbook(filename)
sheet = wb.active
#一次遍历excel的每一行。使用枚举会返回当当前行的对象和索引
for index,row in enumerate(sheet.rows):
#索引是从零开始的,但是表格的内容是从第一行开始的,因此行数= 索引+1
##每一行的第一列的单元格的value是商品名称.
produce_name = sheet.cell(row = index+1,column =1)
if produce_name in price_update.keys():
sheet.cell(row = index+1,column = 2).value = price_update[produce_name]
wb.save(filename=filename)