知识图谱_关系抽取_文献笔记(三)———利用分层强化学习
本文介绍一篇发表在AAAI 2019上的关系抽取方向的文章:A Hierarchical Framework for Relation Extraction with Reinforcement Learning。对知识图谱关系抽取前世了解一下。
源代码:https://github.com/truthless11/HRL-RE
【一些废话】paper中其实对于任务具体是个什么样子,预训练的过程,为什么预训练之后需要用到强化学习、强化学习中的reward设计没有讲特别清楚,建议看源码!!建议看源码!!建议看源码!!我也是在看完源码后写下这篇笔记以备不时之需啦!强化学习在nlp中用的较少,这篇真是太厉害了!而且这是一篇看起来简单,其实蛮复杂的文章,一定要花大篇幅介绍。
一、数据格式
每一条数据如下图所示,看了数据对任务会更清晰一点,本文的任务就是训练一个模型,输入为下图的sentext,希望模型能输出relations(包含其中的rtext,em2,em1,tags),想一下人能不能通过输入标出这么多输出呢,答案是能,说明我们的人工智能真的是朝向自然人的思考方式在发展:


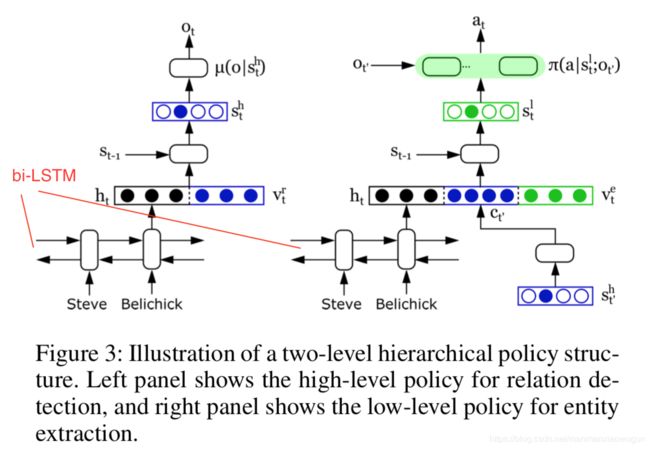
二、框架简介

分层强化学习包含两层强化学习,分别为high-level(用于检测关系)和low-level(用于提取描述该关系的实体对), 整个过程如上图所示: (I). 依次遍历句子的每个单词,high-level如果在某个单词处,鉴定之前的这段句子存在某种关系 ,就会激发一个low-level的序列标注 (II). 当low-level完成了实体抽取 (III), high- level就会继续遍历剩下的句子(IV) .
这个时候你会有疑问,high-level怎样检测关系,low-level怎样提取实体对,下面还会详细介绍!
三、方法优点
现有的关系抽取方法:
1)先识别实体,再确定实体之间的关系,一是没有考虑实体与关系之间的交互,将他们割裂成两个子任务分别处理,二是一个句子对不一定只描述一种关系;
2)关系抽取会存在重叠关系问题(也叫一对多问题):在一句话中,一个实体可能参与进了多个关系,或者一个实体对可能存在多种关系。目前已知只有CopyR方法研究了这个问题(但是本文作者实验证明了这种方法严重依赖数据,并且无法抽取多词语关系)。
本文改进:
1)应用分层强化学习框架来增强实体提及和关系类型之间的交互,将相关实体视为关系的证明,他们之间的依赖交互关系通过state和reward的设计来实现。state为强化学习中的状态,high-level的强化学习在启动low-level的强化学习来抽取实体时,会将自身的state传给low-level,low-level在完成任务后会把自身的state传给high-level;reward为强化学习中的奖赏,low-level在完成任务后也会把自身的reward传给high-level,来表示任务是不是被很好的完成。
2)因为会先检测关系,再抽取该关系的实体,重叠关系(overlapping relations)得以被分开处理。
四、框架细节
1. 整体框架
首先,文章定义了“关系指示符”(relation indicator)。 当在一句话中的某个位置有足够信息去识别语义关系时,我们把这个位置就叫做“关系指示符”。它可以是名词(his father)、动词(die of)、介词(in),或者是一些其他的符号比如逗号、时间等等。 关系指示符在本结构中非常重要,因为整个的关系抽取任务可以分解为“在关系指示符处检测关系”和“关系中的实体抽取”。
整体来看,关系抽取过程如下:
1)high-level主要是预测rtext:一个agent遍历句子的每一个单词,预测这个位置之前的那段句子表示的关系类型(不同于识别实体对之间关系的关系分类,该过程不需要对实体进行标注,你可以理解它是根据句子中是否包含his father,in,die of等预测的)。当在一个时间步中没有足够的信息来指示语义关系时,agent可以选择NR,表示没有关系。否则,触发一个关系指示符,agent启动一个用于实体提取的子任务。
2)实体提取是通过序列标注完成的,先根据第一步预测的关系对整个句子做标注(即得到tags),再根据tags得到em1和em2,当实体被识别时,子任务完成,agent继续扫描句子的其余部分寻找其他关系。
这时你会有疑问,在数据形式介绍的时候不是说模型输入只有句子文本嘛,那这个relation indicator的正确值是多少呢,其实事实上是没有这个正确值的,这块我们会在第五部分(一些思考)里面介绍(预训练也是在代码里面可以看到)。
2. Relation Detection with High-level RL
High-level RL的策略(policy)u目的是在句子中找到存在的关系,可以看做是带有options的RL policy。
Option: 当agent遍历到每个单词处时,根据当前的state作出选择(option),在集合O = {NR} ∪ R中选择,R为所有的关系集合,当option不等于NR时,agent被low-level RL接管,当low-level RL进入结束状态,agent的控制将被high-level接管去执行下一个option。
State:状态S由以下三者共同决定:当前的隐状态![]() ,前一个非NR的option的relation type vector
,前一个非NR的option的relation type vector ![]() 和上一个时步的state
和上一个时步的state ![]() 。公式如下:
。公式如下:
![]() 是非线性变换,
是非线性变换,![]() 是由Bi-LSTM得到隐状态。
是由Bi-LSTM得到隐状态。
Policy:关系检测的策略,也就是option的概率分布,如下,其中![]() 是权重
是权重
![]()
Reward: 环境在每个时步,提供给Agent的一个可量化的标量反馈信号,也就是reward,计算方法如下:
在这个公式里, 代表的是这个句子中的所有正确的关系,其实上面的公式指的是看预测的关系在不在正确的关系中啦。(虽然在代码中,为了更好的实验效果,鼓励某种关系预测,打击某种关系预测,reward的设计比这个复杂,但上述公式已经不影响对框架的理解啦)
代表的是这个句子中的所有正确的关系,其实上面的公式指的是看预测的关系在不在正确的关系中啦。(虽然在代码中,为了更好的实验效果,鼓励某种关系预测,打击某种关系预测,reward的设计比这个复杂,但上述公式已经不影响对框架的理解啦)
最后,用一个最终的reward ![]() 来评价句子级别的抽取效果
来评价句子级别的抽取效果
这里的精确率![]() 指的是在所有标注为非NR关系的时步中,真正在正确的关系中的比率(low-level将reward传递给high-level进行交互就是在这里完成的,因为只有当这个关系的实体对也被预测出来才算关系被正确预测);
指的是在所有标注为非NR关系的时步中,真正在正确的关系中的比率(low-level将reward传递给high-level进行交互就是在这里完成的,因为只有当这个关系的实体对也被预测出来才算关系被正确预测);![]() 指的是所有正确的关系,被预测出来的比率。
指的是所有正确的关系,被预测出来的比率。![]() 是被当成最后一个时步后面的那个时步的reward(可以理解为
是被当成最后一个时步后面的那个时步的reward(可以理解为![]() )算进累积reward的。
)算进累积reward的。
3. Entity Extraction with Low-level RL
当High-level RL policy预测了一个非NR的relation,Low-level RL会抽取relation中的实体。High-level RL的option会作为Low-level RL的额外输入(记得没,这就是前面说的交互)。
Action: action会给当前时步的词分配一个tag,tag包括![]() 。其中,S是参与的源实体,T是目标实体,O是和关系无关的实体,N是非实体单词,B和I表示一个实体的开始和内部(注意,基于当前时步的关系,相同的实体可能被标注不同的S、T、O)。可参看下图:
。其中,S是参与的源实体,T是目标实体,O是和关系无关的实体,N是非实体单词,B和I表示一个实体的开始和内部(注意,基于当前时步的关系,相同的实体可能被标注不同的S、T、O)。可参看下图:
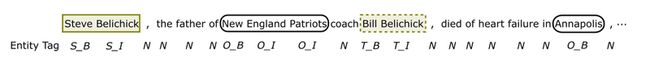
state:
![]() 是当前单词的隐状态,同样也是经过Bi-LSTM计算得到,
是当前单词的隐状态,同样也是经过Bi-LSTM计算得到,![]() 是上一时步的实体标签
是上一时步的实体标签![]() 的向量(可学习),
的向量(可学习),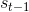 是上一阶段的state(注意,既可以是High-level的state,也可以是Low-level的上一时步的state)。g和f都是非线性变换。
是上一阶段的state(注意,既可以是High-level的state,也可以是Low-level的上一时步的state)。g和f都是非线性变换。
Policy:由句子到实体的概率计算如下:
![]() 是一个数组,数组的长度为总共的关系种类数,数组中的每个元素为对应某种关系的参数矩阵,也就是说,不同的关系tag标注的参数不共享哦!
是一个数组,数组的长度为总共的关系种类数,数组中的每个元素为对应某种关系的参数矩阵,也就是说,不同的关系tag标注的参数不共享哦!
Reward: 我们需要用reward来衡量预测的标签是否准确,一种是每个时步的reward:
![]()
![]()
其中,![]() 降低non-entity tag的权重,不然的话,机器为了获取高reward,全标成N了。
降低non-entity tag的权重,不然的话,机器为了获取高reward,全标成N了。
还有一种是对这个关系的序列标注完成后,对整体的reward ![]() 为:如果全部序列标注都对的话,
为:如果全部序列标注都对的话,![]() 为1,否则为-1;
为1,否则为-1;![]() 是被当成最后一个时步后面的那个时步的reward(可以理解为
是被当成最后一个时步后面的那个时步的reward(可以理解为![]() )算进累积reward的。
)算进累积reward的。
4. Hierarchical Policy Learning
在优化High-level policy时,我们需要最大化预期累积回报,如下:
 是RL中的折扣因子。在结束前,整个采样过程需要T个时间步长。
是RL中的折扣因子。在结束前,整个采样过程需要T个时间步长。
同样的,在优化Low-level policy时,我们也需要最大化累计回报,公式如下:
把累计回报分解成Bellman方程,得到:
当实体提取策略根据选项ot运行时,子任务持续的时间步数是N。当option是NR是,N=1。
可以一同优化High-level和Low-level两段策略,High-level的梯度是:
Low-level的梯度是:
整个训练过程如下:

五、一些思考
1. high-level为什么要用强化学习?
事实上我们不知道relation indicator的正确值是多少,所以我们先做数据预处理生成一些relation indicator(只是比较接近正确值),拿这些来做预训练,预训练的差不多了再利用强化学习来更精细化的接近relation indicator的正确值(你要知道,强化学习和非强化学习的区别在于,因为我们不知道什么是真正的对,无法直接教给模型,才用强化学习的,让它自行用reward来接近真正的对)。和强化学习不一样的是,预训练反向传播的时候不带reward,强化学习就是乘上了个reward。
2. low-level为什么要用强化学习?
你可能会问,low-level的tag标注是有正确值的呀,为什么还要用强化学习。其实是因为连high-level给它传的关系都不一定是准确的,基于这个关系的tag标注当然也只能给个reward来判断啦。
六、实验
数据集:通过远程监督得到的数据:NYT10和NYT11;
评价方法:采用micro-F1评价方法, 如果关系类型和两个对应的实体都正确,则认为三元组是正确的;
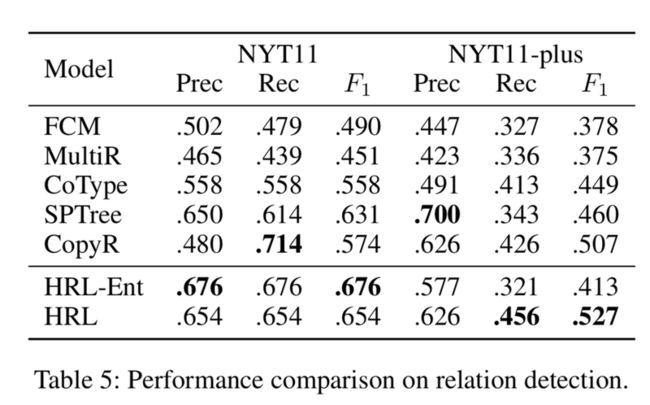
Baselines:作为对比的baseline方法有:FCM、MultiR、CoType、SPTree、Tagging和CopyR
关系抽取:

重叠关系抽取:

交互的优势:
参考文献:paperweekly https://www.paperweekly.site/papers/notes/667