深入理解计算机系统(笔记):链接
理解链接有很多好处:
- 有助于构造大型程序
- 有助于避免一些危险编程错误
- 有助于理解其他重要的系统概念
- 让你能够利用共享库
1. 编译器驱动程序
编译命令,假设有main.c和swap.c两个源文件
$ gcc -O2 -g -o p main.c swap.c实际上编译过程可以分解为以下步骤
1. 运行C预处理器(cpp),将main.c翻译成一个中间文件
$cpp [options] main.c main.i
2. 运行C编译器(ccl),将main.i翻译成汇编语言
$ccl main.i main.c -O2 [options] -o main.s
$gcc -S main.c -O2 [options] -o main.s
3. 运行汇编器(as),将main.s翻译成可重定位目标文件(relocatable object file) main.o
$as [options] -o main.o main.s
4. 重复以上步骤生成swap.o
5. 运行连接器(ld),将main.o swap.o以及一些必要的系统目标文件组合起来,生成可执行目标文件(executable object file) p
$ ld -o p [system object files and args] main.o swap.o
$ ./p2. 静态链接
上面提到的“ld”是一个静态连接器,它需要完成两个主要任务来构造可执行文件
1. 符号解析(symbol resolution)
将符号引用(object reference)和符号定义联系起来
2. 重定位(relocation)
编译器和汇编器生成从地址0开始的代码和数据节(section),链接器通过把每个符号定义与一个内存地址联系起来,然后修改所有对这些符号的引用,
使得他们指向这个内存地址,从而重定位这些sections
3. 目标文件
一共有3种目标文件类型
- 可重定位目标文件
- 可执行目标文件
- 共享目标文件:可动态加载到存储器与可执行文件链接执行
目标文件格式,这里讨论的都是ELF格式
- COFF(Common Object File Format):System V Unix早期版本使用
- PE(Portable Executable):COFF变种,Windows NT使用
- ELF(Executable and Linkable Format):System V Unix后来的版本使用
ELF格式相关知识可以参考下面两篇博客:
ELF Format
ELF Format:程序加载和动态链接
4. 可重定位目标文件
更详细内容参考:ELF Format
下图为一个典型的ELF可重定位目标文件格式

ELF头以一个16字节的序列开始,其中包含了生成该文件的系统的字大小和字节顺序,ELF头剩下部分包括ELF头大小、目标文件类型、机器类型、节头部表偏移(section header table)。
ELF文件中其他节(section)的位置信息都在节头部表中可以找到
ELF头和节头部表之间的都是各种各样的节(section)
.text: 已编译程序的机器代码
.rodata: 只读数据
.data: 已初始化的全局变量(ELF文件中不含局部变量,他们保存在栈中)
.bss:(Block Storage Start) 未初始化的全局变量,区分已初始化和未初始化全局变量的目的是为了节省磁盘空间,目标文件中这个节不占用空间,只是一个占位符
.symtab: 符号表,存放程序中定义和引用的函数和全局变量的信息(没有局部变量的条目)
.rel.text: 一个.text节中位置的列表。当链接器将此文件与其他目标文件链接时需要修改这些位置,一般任何调用外部函数或引用全局变量的指令都要修改
.rel.data: 引用或定义的任何全局变量的重定位信息,任何已初始化的全局变量,如果它的初值是一个全局变量地址或外部函数地址,就需要修改
.debug: 调试符号表,包含了程序中定义的局部变量和类型定义,定义或引用的全局变量,以及源文件。编译时使用-g选项才能生成这个section
.line: 源文件中的行号和.text节中机器指令间的映射,编译时使用-g生成这个表
.strtab: 字符串表,包含.symtab和.debug节中的符号表,以及节头部中的节名字
5. 符号和符号表
每个可重定位目标模块m都有一个符号表,包含m所定义和引用的符号信息。有3种不同的符号:
1. 由m定义,能被其他模块引用的全局符号。非static函数和非static全局变量
2. 其他模块定义,被m引用的全局符号。 源文件中使用external修饰
3. 只被m定义和引用的本地符号。带static的函数和带static的全局变量和本地变量
利用static隐藏变量和函数名:
一个源文件中声明的全局变量和函数,其他模块都可以看到。如果不想其他模块使用全局变量和函数,可以用static修饰,static全局变量和函数只有声明它的源文件可用
符号表结构如下:

name: symbol名字,指向字符串表中的字节偏移量
value: 符号地址
size: 目标大小
type/binding: 目标类型,binding表示符号是本地还是全局的
reserved: 保留
section: 每个符号都和目标文件中某个节相关联,这个字段存储的是到节头部表的索引。除了具体节,还有3个伪节(pseudo section):
ABS:不该被重定位的符号
UNDEF:未定义符号,表明被这个目标文件引用,但是在其他地方定义
COMMON:表示还未分配位置的未初始化的数据目标
6. 符号解析
链接器解析符号时,将符号引用于输入的可重定位目标文件的符号表中的个确定的符号定义联系起来。
本地符号的解析很简单,就在本目标文件中找到符号定义就行了。但是当链接器在本地没有找到符号定义时,就会尝试到其他目标文件中查找。如果其他文件也没找到,就会产生链接错误!
6.1 解析多重定义的全局符号
编译器将全局符号分为‘强’和‘弱’符号,函数和已初始化的全局变量是强符号,未初始化的全局变量是弱符号。
链接器使用如下规则处理多重符号定义(这是C的规则,C++中不允许出现多重定义,弱符号也不行)
规则1:不允许有多个同名强符号
规则2:如果有一个强符号和多个同名弱符号,那么选择强符号
规则3:如果有多个同名弱符号,那么从中任选一个
6.2 与静态库链接
系统可以将一组相关的目标模块打包成一个单独的文件,称为静态库(static library)。链接时可以使用静态库里的目标模块作为输入,链接器只会拷贝被应用程序引用的目标模块。
使用ar创建静态库
$ ar rcs libvector.a addvec.o multvec.o6.3 使用静态库进行引用解析
进行符号解析时,链接器按照命令行上从左到右顺序扫描可重定位目标文件和库文件,此过程中链接器维护3个集合:
- 可重定位目标文件集合E
- 未解析的符号集合U
- 在输入文件中已定义的符号集合D
初始时3个集合都为空,链接器按照如下规则填充3个集合:
- 对于输入文件f,判断它是一个目标文件还是一个库文件
- 如果是目标文件,添加到E,并且扫描f里的符号定义和引用来修改集合U和D。继续下一个文件
- 如果f是库文件,尝试在库文件中查找U中未定义的符号。如果在库文件的某个成员m中找到一个符号来解析U中的引用,就将m添加到E,并且扫描m来修改U和D。对库文件中所有成员目标文件都反复进行此过程,直到U和D都不再变化
- 当处理完所有文件,如果U是非空,那么就会产生链接错误。否则就就合并和重定位E中的目标文件,构建可执行文件
但是这个过程有一个问题,那就是输入文件需要以一定的顺序出现在命令行上,不然就可能出现链接错误(如果后面的文件中引用前面文件的符号)。不过现在的链接器应该使用了不同的策略(或者有其他步骤保证)。
7. 重定位
完成符号解析后,链接器就把代码中的每个符号引用和符号定义联系起来,此时链接器已经知道当前所有输入目标模块中的代码节和数据节的大小,可以进行重定位了。
重定位由两部组成:
- 重定位节和符号定义:链接器将所有相同类型的节合并到同一类型的新的聚合节,并将此节作为可执行文件的对应节。随后链接器将运行时内存地址赋给新的聚合节,赋给输入模块定义的每个节,以及每个符号,现在程序中每个指令和全局变量都有唯一的运行时地址了
- 重定位节中的符号引用:链接器修改代码和数据节中的符号引用,让他们指向正确的运行时地址。这一步需要“重定位条目”的支持
7.1 重定位条目
编译器在编译目标文件时,它并不知道数据和代码最终会放在内存的什么位置,也不知道引用的外部函数或全局变量的位置。所以,当编译器遇到最终内存位置未知的目标引用时,就会生成一个“重定位条目”,链接器根据重定位条目修改对应引用。代码(函数)的重定位条目放在.rel.text中,已初始化数据的重定位条目放在.rel.data中。
ELF重定位条目格式如下:
typedef struct { int offset; /* Offset of the reference to relocate */ int symbol:24, /* Symbol of the reference should point to */ type:8; /* Relocation type */} Elf32_Rel;R_386_PC32:重定位一个使用32位PC相对地址的引用R_386_32:重定位一个使用32位绝对地址的引用7.2 重定位符号引用
下面是链接器重定位算法的伪代码
foreach section s {
foreach relocation entry r {
refptr = s + r.offset; /* ptr to reference to be relocated */
/* Relocate a PC-relative reference */
if (r.type == R_386_PC32) {
refaddr = ADDR(s) + r.offset; /* ref's runtime address */
*refptr = (unsigned) (ADDR(r.symbol) + *refptr - refaddr);
}
/* Relocate an obsolute reference */
if (r.type == R_386_32)
*refptr = (unsigned) (ADDR(r.symbol) + *refptr);
}
} 前例中,main.o的.text节中,main函数调用了swap函数(在swap.o中定义),反汇编main.o如下:
$ objdump -d main.o
....
6: e8 fc ff ff ff call 7 swap();
7: R_386_PC32 swap relocation entry
..... r.offset = 0x7
r.symbol = swap
r.type = R_386_PC32重定位之前链接器已经指定好了目标模块中各节和符号的运行时地址,假设当前节和符号地址如下:
ADDR(s) = ADDR(.text) = 0x80483b4
ADDR(r.symbol) = ADDR(swap) = 0x80483c8
使用上面的算法,链接器首先计算处引用的运行时地址
refaddr = ADDR(s) + r.offset
= 0x80483b4 + 0x7
= 0x80483bb*refptr = (unsigned) (ADDR(r.symbol) + *refptr - refaddr)
= (unsigned) (0x80483c8 + (-4) - 0x80483bb)
= (unsigned) (0x9)80483ba: e8 09 00 00 00 call 80483c8 swap(); push PC onto stack
PC <- PC + 0x9 = 0x80483bf + 0x9 = 0x80483c8注意:
为什么call指令中引用的初始值为-4?
这是因为CPU执行call指令时,PC实际指向了下一条指令,然而引用的开始地址是下一条指令之前的4 bytes处(因为引用占4 bytes)。重定位绝对引用
前例中,swap.o中全局指针bufp0指向了全局数组buf的第一个元素
int *bufp0 = &buf[0];00000000 :
0: 00 00 00 00 int *bufp0 = &buf[0];
0: R_386_32 buf Relocation entry 假设链接器以及确定符号地址:
ADDR(r.symbol) = ADDR(buf) = 0x8049454*refptr = (unsigned) (ADDR(r.symbol) + *refptr)
= (unsigned) (0x8049454 + 0)
= (unsigned) (0x8049454)0804945c :
804945c: 54 94 04 08 Relocated 8. 可执行目标文件
下图为一个典型的ELF可执行文件格式: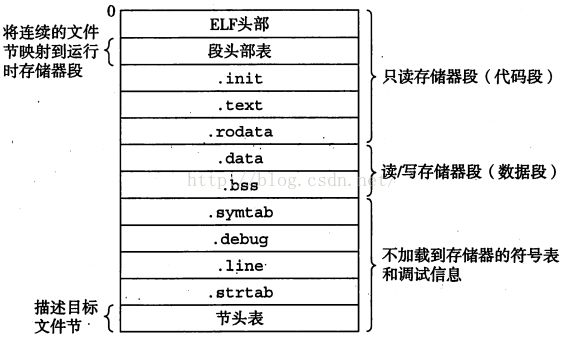
与可重定位文件类似,也有ELF头部、节头标、各种节,运行时系统把需要的一些节(sections)加载到相应的内存地址,怎么知道哪些节加载到什么位置呢?这是由段头部表(segment header table)决定的。下图为可执行文件的段头部:

从上图可看出,运行时加载了两个内存段:code segment和data segment。
代码段对齐到一个4KB(2^12)的边界,有读/执行权限,开始地址为0x08048000,占用内存大小为0x448字节。其中包括ELF头部、段头部表、.init、.text和.rodata节。
数据段同样对齐到4KB的边界,开始于0x8049448处,内存大小为0x104字节,其中的0xe8字节(.data节)使用文件中的内容初始化,剩下的初始化为0(也就是.bss)。
9. 加载可执行目标文件
运行可执行文件时,系统使用一个被称为加载器(loader)的程序,将可执行文件的代码和数据从磁盘加载到内存中,然后跳转到程序的第一条指令(或者入口点entry point)开始执行。
Unix程序运行时在有一个内存映像,表示程序在内存中的结构,如下图
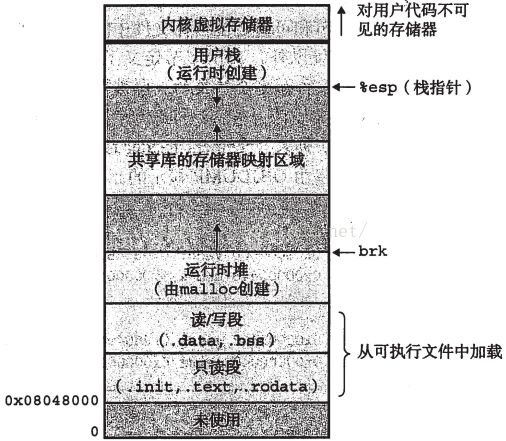
代码段总是从地址0x08048000开始,数据段是在紧接着的一个4KB对齐的地址处,堆在数据段之后,往上增长。中间有一个共享库保留的内存段。然后是用户栈,栈从最大的合法用户地址开始,向下增长。栈之上是系统保留的内存,用户进程不能访问(只能通过系统调用陷入内核态访问)。
10. 动态链接共享库
静态库可以为编译链接提供方便,但是缺点也很明显:每次改动使用到静态库的程序都有重新链接、很多程序使用相同的静态库会增加内存负载等
解决这些问题我们可以使用共享库(shared library,dll),在运行时使用动态链接器(dynamic linker)与程序进行动态链接来执行。
使用gcc可以生产共享库:
$ gcc -shared -fPIC -o libvector.so addvec.c multvec.c$ gcc -o p2 main.c libvector.so在与共享库进行静态链接的过程中,并没有拷贝共享库中的任何代码和数据,而只是拷贝了一些重定位和符号表信息,动态链接时使用这些信息解析共享库中的代码和数据。
当加载器加载和运行可执行文件时,先加载只进行了部分链接的可执行文件,它会发现其中有一个.interp节,里面包含了动态链接器的路径名,这时加载器会加载这个动态链接器,执行如下链接任务:
- 重定位libc.so的文本和数据到某个内存段
- 重定位libvector.so的文本和数据到另一个内存段
- 重定位可执行文件中所有对libc.so libvector.so中符号的引用
链接完成后,动态链接器将控制交给程序执行。
11. 从程序加载和连接共享库
除了在运行时由系统加载共享库,我们也可以在代码中直接加载指定的共享库,在编译时要加上编译选项-rdynamic
$ gcc -rdynamic -O2 -o p3 dll.c -ldl代码中加载共享库的函数如下:
#include
void* dlopen(const char* filename, int flag); // 成功时返回指针为指向句柄的指针,否则返回NULL
flag:
RTLD_GLOBAL: 解析库‘filename’中的外部符号
RTLD_NOW: 让链接器现在就解析符号引用
RTLD_LAZY: 使用到该符号引用时才解析 #include
void dlsym(void *handle, char *symbol); // 成功则返回指向符号的指针,否则返回NULL #include
int dlclose(void* handle); // 成功返回0, 否则返回-1 #include
const char* dlerror(void); //如果dlopen、dlsym、dlclose调用失败,则返回错误信息,成功则返回NULL Java中的JNI(Java Native Interface,Java本地接口)就是利用共享库来实现的,它允许Java程序调用“本地的”C和C++函数。JNI的思想是将本地C函数,如foo,编译到共享库foo.so中,当Java程序试图调用函数foo时,Java解释程序(位于JVM中)利用dlopen动态链接和加载foo.so,然后再调用。
12. 位置无关代码(PIC)
PIC:position-independent code
共享库可以让多个进程共享同一段内存中的代码,以节省宝贵的内存资源,那么它是怎么实现的呢?
一种方法是给每个库预留一个专用的地址空间,每次都加载到同一个地址空间。但是随着共享库的增加,这会带来严重的内存碎片和管理的问题。
更好的方法是将库代码编译成不需要链接器修改就可以在任何地址加载和执行的代码,这就叫位置无关代码(Position-Independent Code, PIC)。gcc使用选项-fPIC来生成PIC代码。
同一个目标模块中的过程调用不需要特殊处理,因为引用的都是本地符号,他们的偏移量是已知的,所以已经是PIC代码了。但是对于外部定义的过程调用和全局变量的引用通常都不是PIC,都需要连接是进行重定位。
12.1. PIC数据引用
生成全局变量的PIC引用有一个前提:加载目标模块(包括共享目标模块)时,数据段总是被分配成紧随代码段后面。这样代码段中的任何指令和数据段中的任何变量之间的距离都是一个运行时常量,与代码段和数据段的绝对内存位置无关。
基于此,编译器在数据段开始的地方创建了一个“全局偏移量表(Global Offset Table,GOT)”。GOT中,每个被改目标模块引用的全局数据对象都有一个条目,条目中存有重定位记录。加载时,动态链接器会重定位GOT中的每个条目,使之包含正确的地址。每个引用全局数据的目标模块都有自己的GOT。
运行时,使用形如下面的代码,通过GOT间接引用全局变量:
call L1
L1: popl %ebx ebx contains the current PC
addl $VAROFF, %ebx ebx points to the GOT entry for the var
movl (%ebx), %eax reference indirect through the GOT
movl (%eax), %eax got the real content of the reference
为什么popl %ebx会得到PC的值?
这是因为call L1会将当前PC的值压栈后再跳转到L1处开始执行,所以popl指令取的其实就是call压入的PC值。
取PC值的目的是什么呢?
当然是为了找到GOT中当前引用对应的条目,因为引用实际上存的是它在GOT中对应条目相对于下一条指令地址(PC值)的偏移量,
所以(%PC)加上这个偏移量就是此引用在GOT中对应的条目。
12.2 PIC函数调用
PIC代码的外部函数调用也可以用同样的方式:
call L1
L1: popl %ebx ebx contains the current PC
addl $PROCOFF, %ebx ebx points to the GOT entry for proc
call *(%ebx) call indirect through the GOT
延迟绑定通过两个数据结构的交互来实现:GOT和PLT(Procedure Linkage Table,过程链接表)。
任何调用了共享库中定义的函数的目标模块,都包含了自己的GOT和PLT。GOT位于.data节,PLT位于.text节。
下图为一个例子的GOT格式:

前3个条目是特殊的:
GOT[0]包含.dynamic段的地址,存有动态链接器用来绑定过程(函数)地址的信息,如符号表位置和重定位信息
GOT[1]包含定义这个模块的信息
GOT[2]包含动态链接器的延迟绑定代码的入口点
其他的对应于目标模块中的外部过程调用,可以看出调用了printf(在libc.so中)和addvec(libvector.so中)函数
下图为该例的PLT:

PLT是一个数组,其中每个条目大小为16字节。第一个条目PLT[0]是特殊条目,用于跳转到动态链接器中。从PLT[1]开始的条目对应于目标模块中的外部过程调用。
PLT[1]对应于printf
PLT[2]对应于addvec
程序刚被加载运行时,调用printf和addvec的地方分别绑定到相应PLT条目的第一条指令上,如调用addvec指令如下:
08485bb: e8 a4 fe ff ff call 8048464
call指令使用相对寻址方式,实际地址为当前PC地址+0xfffffea4 = 0x8048464, 刚好就是PLT[2]开始的地址
当下一次再调用addvec时,PLT[2]的第一条指令通过GOT[4]直接跳转到addvec开始执行。
13. 处理目标文件的工具
下面的工具可以帮助理解目标文件:
AR:创建静态库,插入、删除、列出和提取成员
STRINGS:列出一个目标文件中所有可打印的字符串
STRIP:从目标文件中删除符号表信息
NM:列出一个目标文件的符号表中定义的符号
SIZE:列出目标文件中节的名字和大小
READELF:显示一个目标文件的完整结构,包括ELF头中编码的所有信息。包含SIZE和NM的功能
OBJDUMP:所有二进制工具之母。。能够显示一个目标文件的所有信息。最大作用就是反汇编.text中的二进制指令
LDD:列出可执行文件在运行时需要的共享库