Flink on Yarn快速入门
Apache Flink是一个高效、分布式、基于Java实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API。从Apache官方博客中得知,Flink已于近日升级成为Apache基金会的顶级项目。
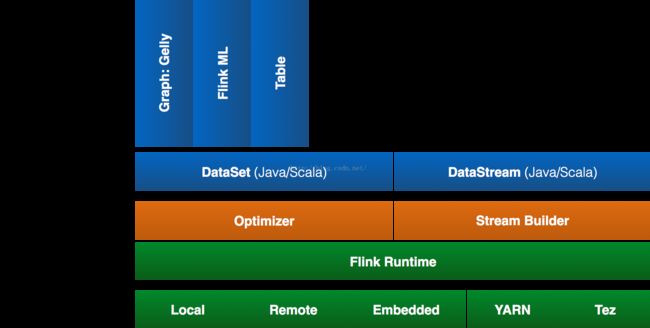
Apache Flink支持三种部署模式:local、standalone、yarn,本文将介绍Flink on yarn模式。
一、long-running Flink cluster on YARN
下面会启动yarn session,其中4 个Task Managers 进程,即yarn container,每个分配4 GB内存)。另外,使用-s选项指定每个Task Manager进程使用的processing slots数量,官方建议设置成每台机器(yarn node manager)的CPU processors 个数。
curl -O
tar xvzf flink-0.10.0-bin-hadoop2.tgz
cd flink-0.10.0/
./bin/yarn-session.sh -n 4 -jm 1024 -tm 4096 启动后,可以在yarn界面看到运行状态,之后就可以使用bin/flink run命令提交作业到Flink了!
二、Run a Flink job on YARN
该模式只会提交单个job到yarn,资源也是为单个job分配
curl -O
tar xvzf flink-0.10.0-bin-hadoop2.tgz
cd flink-0.10.0/
./bin/flink run -m yarn-cluster -yn 4 -yjm 1024 -ytm 4096 ./examples/WordCount.jar 三、Apache Flink on Hadoop YARN using a YARN Session
要求:Apache Hadoop2.2版本以上&&HDFS文件系统
1)启动Flink yarn session
启动Flink必须的服务(JobManager 和 TaskManagers),然后就可以在一次yarn session过程中提交多个Flink job了。
./bin/yarn-session.sh启动命令参数如下:
Usage:
Required
-n,--container Number of YARN container to allocate (=Number of Task Managers)
Optional
-D Dynamic properties
-d,--detached Start detached
-jm,--jobManagerMemory Memory for JobManager Container [in MB]
-nm,--name Set a custom name for the application on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue Specify YARN queue.
-s,--slots Number of slots per TaskManager
-st,--streaming Start Flink in streaming mode
-tm,--taskManagerMemory Memory per TaskManager Container [in MB] 注意:启动前必须配置YARN_CONF_DIR 或HADOOP_CONF_DIR,一般CDH发行版配置成/etc/hadoop/conf即可。
启动yarn-session,默认使用 conf/flink-config.yaml配置文件,配置文件详细介绍
./bin/yarn-session.sh -n 10 -tm 8192 -s 32Flink on Yarn会覆盖下面几个参数,如果不希望改变配置文件中的参数,可以动态的通过-D选项指定,如 -Dfs.overwrite-files=true -Dtaskmanager.network.numberOfBuffers=16368
jobmanager.rpc.address:因为JobManager会经常分配到不同的机器上
taskmanager.tmp.dirs:使用Yarn提供的tmp目录
parallelism.default:如果有指定slot个数的情况下
yarn-session.sh会挂起进程,所以可以通过在终端使用CTRL+C或输入stop停止yarn-session。
Detached YARN session
如果不希望Flink Yarn client长期运行,Flink提供了一种detached YARN session,启动时候加上参数-d或--detached。
在本例中,Flink Yarn Client只会提交Flink到Yarn中然后自己关闭,所以本例不能通过Flink关闭yarn session,但是可以使用yarn application -kill 命令停止。
2)提交作业到Flink
使用以下命令提交Flink作业到Yarn Cluster,命令详细介绍
./bin/flink[...]
Action "run" compiles and runs a program.
Syntax: run [OPTIONS]
"run" action arguments:
-c,--class Class with the program entry point ("main"
method or "getPlan()" method. Only needed
if the JAR file does not specify the class
in its manifest.
-m,--jobmanager Address of the JobManager (master) to
which to connect. Use this flag to connect
to a different JobManager than the one
specified in the configuration.
-p,--parallelism The parallelism with which to run the
program. Optional flag to override the
default value specified in the
configuration 启动wordcount示例
wget -O LICENSE-2.0.txt http://www.apache.org/licenses/LICENSE-2.0.txt
hadoop fs -copyFromLocal LICENSE-2.0.txt hdfs:/// ...
./bin/flink run ./examples/WordCount.jar \
hdfs:///..../LICENSE-2.0.txt hdfs:///.../wordcount-result.txt四、Run a single Flink job on Hadoop YARN
前面介绍了如何在hadoop Yarn环境下启动一个Flink Cluster,Flink同样支持在yarn中启动一个独立的Flink作业。
./bin/flink run -m yarn-cluster -yn 2 ./examples/WordCount.jar在这个模式下,同样可以使用-m yarn-cluster提交一个"运行后即焚"的detached yarn(-yd)作业到yarn cluster。