05_行销(Marketing)里推荐合适的产品(Product Recommendation)
行销(Marketing)里推荐合适的产品(Product Recommendation)
- Load the packages
- Load the data
- Data Preparation
- Customer-Item Matrix
- User-based Collaborative Filtering
- Making Recommendations
- Item-based Collaborative Filtering
在这篇文章里,我们将构建产品推荐系统,通过这些产品,我们可以使用针对个人客户量身定制的产品推荐来更好地定位客户。研究表明,个性化的产品推荐可以提高转化率和客户保留率。随着我们拥有更多可用于利用数据科学和机器学习进行目标营销的数据,定制产品推荐在营销信息中的重要性和有效性已大大提高。产品推荐系统是一种旨在预测和汇总客户可能购买的商品清单的系统。近年来,推荐系统已广受欢迎,并且已针对各种业务用例进行了开发和实施。例如,音乐流媒体服务Pandora将推荐器系统用于其听众的音乐推荐。电子商务公司Amazon利用推荐系统预测并显示客户可能购买的产品列表。媒体服务提供商Netflix使用推荐器系统为可能会观看的单个用户推荐电影或电视节目。推荐系统的使用不止于此。它还可以用于向用户推荐相关文章,新闻或书籍。推荐器系统具有在各个领域中使用的潜力,因为它们直接影响销售收入和用户参与度,因此在许多企业中,尤其是在电子商务和媒体业务中,都扮演着至关重要的角色。
在本章中,我们将讨论用于开发推荐系统,协作过滤的常用机器学习算法,以及实现针对产品推荐的协作过滤算法的两种方法。
- 协同过滤(Collaborative filtering )
协同过滤方法基于以前的用户行为,例如他们查看的页面,他们购买的产品或他们对不同项目的评分。然后,协作过滤方法使用此数据来查找用户或项目之间的相似性,并向用户推荐最相似的项目或内容。协作过滤方法背后的基本假设是,过去曾经浏览或购买过类似内容或产品的人将来可能会浏览或购买类似种类的内容或产品。因此,基于此假设,如果一个人过去购买了商品A,B和C,而另一个人过去购买了商品A,B和D,则第一个人可能会购买商品D,而另一个人可能会购买商品D。购买商品C,因为它们之间有很多相似之处。
如前一部分所述,协作过滤算法用于根据用户行为的历史记录和用户之间的相似性来推荐产品。为产品推荐系统实现协作过滤算法的第一步是构建用户对项目的矩阵。用户到项目矩阵包括行中的单个用户和列中的单个项目。用一个例子来解释会更容易。看一下下面的矩阵
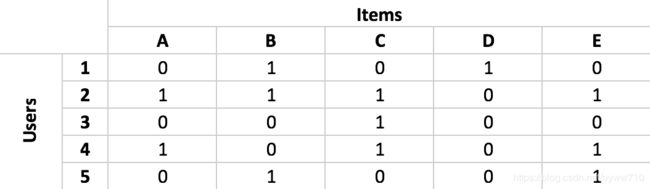
此矩阵中的行代表每个用户,列代表每个项目。每个单元格中的值表示给定用户是否购买了给定商品。例如,用户1购买了商品B和D,用户2购买了商品A,B,C和E。为了构建基于协作过滤的产品推荐系统,我们需要首先构建此类用户项目矩阵。有了这个用户对项目矩阵,构建基于协作过滤的产品推荐系统的下一步就是计算用户之间的相似度。为了测量相似度,经常使用余弦相似度。计算两个用户之间的余弦相似度的公式如下
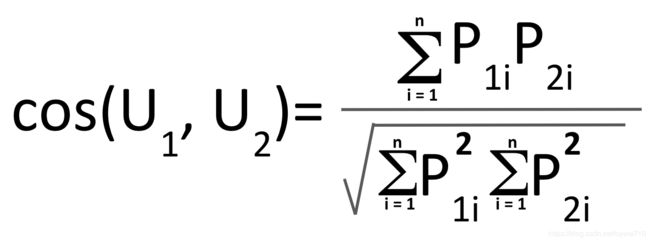
在此等式中,U1和U2代表用户1和用户2。P1i和P2i代表用户1和用户2购买的每个产品。可以想象,余弦相似度越大,则两个用户更相似。
- 基于内容的过滤(Item-based filtering)
基于内容的过滤会根据项目或用户的特征生成推荐列表。它通常查看描述项目特征的关键字。基于内容的过滤方法背后的基本假设是,用户可能会查看或购买与他们过去购买或查看过的商品相似的商品。例如,如果用户过去曾经听过某些歌曲,则基于内容的过滤方法将推荐与用户已经听过的歌曲具有相似特征的相似类型的歌曲。
最后,将协作式过滤算法用于产品推荐时,可以采用两种方法:基于用户的方法和基于项目的方法。顾名思义,基于用户的协作过滤方法利用了用户之间的相似性。另一方面,基于项目的方法协同过滤使用项目之间的相似性。这意味着,当我们在基于用户的方法协同过滤中计算两个用户之间的相似性时,我们需要构建并使用一个用户到项目的矩阵,如我们先前所讨论的。但是,对于基于项目的方法,我们需要计算两个项目之间的相似度,这意味着我们需要构建和使用项目对用户矩阵,我们可以通过简单地将用户对项目转置来获得该矩阵。
我们仍然使用04中的零售数据集OnlineRetail.csv 。
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 5GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
/kaggle/input/onlineretail/OnlineRetail.csv
Load the packages
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
Load the data
df=pd.read_csv(r"../input/onlineretail/OnlineRetail.csv", encoding="cp1252")
df.head(3)
| InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country | |
|---|---|---|---|---|---|---|---|---|
| 0 | 536365 | 85123A | WHITE HANGING HEART T-LIGHT HOLDER | 6 | 12/1/2010 8:26 | 2.55 | 17850.0 | United Kingdom |
| 1 | 536365 | 71053 | WHITE METAL LANTERN | 6 | 12/1/2010 8:26 | 3.39 | 17850.0 | United Kingdom |
| 2 | 536365 | 84406B | CREAM CUPID HEARTS COAT HANGER | 8 | 12/1/2010 8:26 | 2.75 | 17850.0 | United Kingdom |
df = df.loc[df['Quantity'] > 0]
Data Preparation
Handle NA in CustomerID field
df = df.dropna(subset=['CustomerID'])
Customer-Item Matrix
customer_item_matrix = df.pivot_table(
index='CustomerID',
columns='StockCode',
values='Quantity',
aggfunc='sum'
)
customer_item_matrix.loc[12481:].head()
| StockCode | 10002 | 10080 | 10120 | 10123C | 10124A | 10124G | 10125 | 10133 | 10135 | 11001 | ... | 90214V | 90214W | 90214Y | 90214Z | BANK CHARGES | C2 | DOT | M | PADS | POST |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CustomerID | |||||||||||||||||||||
| 12481.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 32.0 |
| 12483.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 16.0 |
| 12484.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 16.0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 21.0 |
| 12488.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 10.0 | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 3.0 |
| 12489.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2.0 |
5 rows ?? 3665 columns
customer_item_matrix = customer_item_matrix.applymap(lambda x: 1 if x > 0 else 0)
customer_item_matrix.loc[12481:].head()
| StockCode | 10002 | 10080 | 10120 | 10123C | 10124A | 10124G | 10125 | 10133 | 10135 | 11001 | ... | 90214V | 90214W | 90214Y | 90214Z | BANK CHARGES | C2 | DOT | M | PADS | POST |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CustomerID | |||||||||||||||||||||
| 12481.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 12483.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 12484.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 12488.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 12489.0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
5 rows ?? 3665 columns
User-based Collaborative Filtering
from sklearn.metrics.pairwise import cosine_similarity
User-to-User Similarity Matrix
user_user_sim_matrix = pd.DataFrame(
cosine_similarity(customer_item_matrix)
)
user_user_sim_matrix.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 4329 | 4330 | 4331 | 4332 | 4333 | 4334 | 4335 | 4336 | 4337 | 4338 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.000000 |
| 1 | 0.0 | 1.000000 | 0.063022 | 0.046130 | 0.047795 | 0.038484 | 0.0 | 0.025876 | 0.136641 | 0.094742 | ... | 0.0 | 0.029709 | 0.052668 | 0.0 | 0.032844 | 0.062318 | 0.0 | 0.113776 | 0.109364 | 0.012828 |
| 2 | 0.0 | 0.063022 | 1.000000 | 0.024953 | 0.051709 | 0.027756 | 0.0 | 0.027995 | 0.118262 | 0.146427 | ... | 0.0 | 0.064282 | 0.113961 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.170905 | 0.083269 |
| 3 | 0.0 | 0.046130 | 0.024953 | 1.000000 | 0.056773 | 0.137137 | 0.0 | 0.030737 | 0.032461 | 0.144692 | ... | 0.0 | 0.105868 | 0.000000 | 0.0 | 0.039014 | 0.000000 | 0.0 | 0.067574 | 0.137124 | 0.030475 |
| 4 | 0.0 | 0.047795 | 0.051709 | 0.056773 | 1.000000 | 0.031575 | 0.0 | 0.000000 | 0.000000 | 0.033315 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.044866 | 0.000000 |
5 rows ?? 4339 columns
user_user_sim_matrix.columns = customer_item_matrix.index
user_user_sim_matrix['CustomerID'] = customer_item_matrix.index
user_user_sim_matrix = user_user_sim_matrix.set_index('CustomerID')
user_user_sim_matrix.head()
| CustomerID | 12346.0 | 12347.0 | 12348.0 | 12349.0 | 12350.0 | 12352.0 | 12353.0 | 12354.0 | 12355.0 | 12356.0 | ... | 18273.0 | 18274.0 | 18276.0 | 18277.0 | 18278.0 | 18280.0 | 18281.0 | 18282.0 | 18283.0 | 18287.0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CustomerID | |||||||||||||||||||||
| 12346.0 | 1.0 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.000000 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.000000 |
| 12347.0 | 0.0 | 1.000000 | 0.063022 | 0.046130 | 0.047795 | 0.038484 | 0.0 | 0.025876 | 0.136641 | 0.094742 | ... | 0.0 | 0.029709 | 0.052668 | 0.0 | 0.032844 | 0.062318 | 0.0 | 0.113776 | 0.109364 | 0.012828 |
| 12348.0 | 0.0 | 0.063022 | 1.000000 | 0.024953 | 0.051709 | 0.027756 | 0.0 | 0.027995 | 0.118262 | 0.146427 | ... | 0.0 | 0.064282 | 0.113961 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.170905 | 0.083269 |
| 12349.0 | 0.0 | 0.046130 | 0.024953 | 1.000000 | 0.056773 | 0.137137 | 0.0 | 0.030737 | 0.032461 | 0.144692 | ... | 0.0 | 0.105868 | 0.000000 | 0.0 | 0.039014 | 0.000000 | 0.0 | 0.067574 | 0.137124 | 0.030475 |
| 12350.0 | 0.0 | 0.047795 | 0.051709 | 0.056773 | 1.000000 | 0.031575 | 0.0 | 0.000000 | 0.000000 | 0.033315 | ... | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.044866 | 0.000000 |
5 rows ?? 4339 columns
Making Recommendations
user_user_sim_matrix.loc[12350.0].sort_values(ascending=False)
CustomerID
12350.0 1.000000
17935.0 0.183340
12414.0 0.181902
12652.0 0.175035
16692.0 0.171499
...
15953.0 0.000000
15952.0 0.000000
15951.0 0.000000
15950.0 0.000000
12346.0 0.000000
Name: 12350.0, Length: 4339, dtype: float64
items_bought_by_A = set(customer_item_matrix.loc[12350.0].loc[
customer_item_matrix.loc[12350.0]==1
].index)
items_bought_by_A
{'20615',
'20652',
'21171',
'21832',
'21864',
'21866',
'21908',
'21915',
'22348',
'22412',
'22551',
'22557',
'22620',
'79066K',
'79191C',
'84086C',
'POST'}
items_bought_by_B = set(customer_item_matrix.loc[17935.0].loc[
customer_item_matrix.loc[17935.0]==1
].index)
items_bought_by_B
{'20657',
'20659',
'20828',
'20856',
'21051',
'21866',
'21867',
'22208',
'22209',
'22210',
'22211',
'22449',
'22450',
'22551',
'22553',
'22557',
'22640',
'22659',
'22749',
'22752',
'22753',
'22754',
'22755',
'23290',
'23292',
'23309',
'85099B',
'POST'}
items_to_recommend_to_B = items_bought_by_A - items_bought_by_B
items_to_recommend_to_B
{'20615',
'20652',
'21171',
'21832',
'21864',
'21908',
'21915',
'22348',
'22412',
'22620',
'79066K',
'79191C',
'84086C'}
df.loc[
df['StockCode'].isin(items_to_recommend_to_B),
['StockCode', 'Description']
].drop_duplicates().set_index('StockCode')
| Description | |
|---|---|
| StockCode | |
| 21832 | CHOCOLATE CALCULATOR |
| 21915 | RED HARMONICA IN BOX |
| 22620 | 4 TRADITIONAL SPINNING TOPS |
| 79066K | RETRO MOD TRAY |
| 21864 | UNION JACK FLAG PASSPORT COVER |
| 79191C | RETRO PLASTIC ELEPHANT TRAY |
| 21908 | CHOCOLATE THIS WAY METAL SIGN |
| 20615 | BLUE POLKADOT PASSPORT COVER |
| 20652 | BLUE POLKADOT LUGGAGE TAG |
| 22348 | TEA BAG PLATE RED RETROSPOT |
| 22412 | METAL SIGN NEIGHBOURHOOD WITCH |
| 21171 | BATHROOM METAL SIGN |
| 84086C | PINK/PURPLE RETRO RADIO |
Item-based Collaborative Filtering
Item-to-Item Similarity Matrix
item_item_sim_matrix = pd.DataFrame(cosine_similarity(customer_item_matrix.T))
item_item_sim_matrix.columns = customer_item_matrix.T.index
item_item_sim_matrix['StockCode'] = customer_item_matrix.T.index
item_item_sim_matrix = item_item_sim_matrix.set_index('StockCode')
item_item_sim_matrix
| StockCode | 10002 | 10080 | 10120 | 10123C | 10124A | 10124G | 10125 | 10133 | 10135 | 11001 | ... | 90214V | 90214W | 90214Y | 90214Z | BANK CHARGES | C2 | DOT | M | PADS | POST |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| StockCode | |||||||||||||||||||||
| 10002 | 1.000000 | 0.000000 | 0.094868 | 0.091287 | 0.0 | 0.000000 | 0.090351 | 0.062932 | 0.098907 | 0.095346 | ... | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.029361 | 0.0 | 0.066915 | 0.0 | 0.078217 |
| 10080 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.032774 | 0.045655 | 0.047836 | 0.000000 | ... | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.016182 | 0.0 | 0.000000 |
| 10120 | 0.094868 | 0.000000 | 1.000000 | 0.115470 | 0.0 | 0.000000 | 0.057143 | 0.059702 | 0.041703 | 0.060302 | ... | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.070535 | 0.0 | 0.010993 |
| 10123C | 0.091287 | 0.000000 | 0.115470 | 1.000000 | 0.0 | 0.000000 | 0.164957 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 |
| 10124A | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.0 | 0.447214 | 0.063888 | 0.044499 | 0.000000 | 0.000000 | ... | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| C2 | 0.029361 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.036955 | 0.019360 | 0.055989 | ... | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 1.000000 | 0.0 | 0.026196 | 0.0 | 0.020413 |
| DOT | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 0.104257 | 0.150756 | ... | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 1.0 | 0.000000 | 0.0 | 0.000000 |
| M | 0.066915 | 0.016182 | 0.070535 | 0.000000 | 0.0 | 0.000000 | 0.070535 | 0.070185 | 0.066184 | 0.106335 | ... | 0.049875 | 0.0 | 0.040723 | 0.0 | 0.089220 | 0.026196 | 0.0 | 1.000000 | 0.0 | 0.077539 |
| PADS | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.049752 | 0.000000 | 0.000000 | ... | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 1.0 | 0.000000 |
| POST | 0.078217 | 0.000000 | 0.010993 | 0.000000 | 0.0 | 0.000000 | 0.070669 | 0.021877 | 0.034383 | 0.058004 | ... | 0.038866 | 0.0 | 0.031734 | 0.0 | 0.017381 | 0.020413 | 0.0 | 0.077539 | 0.0 | 1.000000 |
3665 rows ?? 3665 columns
Making Recommendations
top_10_similar_items = list(
item_item_sim_matrix\
.loc['23166']\
.sort_values(ascending=False)\
.iloc[:10]\
.index
)
top_10_similar_items
['23166',
'23165',
'23167',
'22993',
'23307',
'22722',
'22720',
'22666',
'23243',
'22961']
df.loc[
df['StockCode'].isin(top_10_similar_items),
['StockCode', 'Description']
].drop_duplicates().set_index('StockCode').loc[top_10_similar_items]
| Description | |
|---|---|
| StockCode | |
| 23166 | MEDIUM CERAMIC TOP STORAGE JAR |
| 23165 | LARGE CERAMIC TOP STORAGE JAR |
| 23167 | SMALL CERAMIC TOP STORAGE JAR |
| 22993 | SET OF 4 PANTRY JELLY MOULDS |
| 23307 | SET OF 60 PANTRY DESIGN CAKE CASES |
| 22722 | SET OF 6 SPICE TINS PANTRY DESIGN |
| 22720 | SET OF 3 CAKE TINS PANTRY DESIGN |
| 22666 | RECIPE BOX PANTRY YELLOW DESIGN |
| 23243 | SET OF TEA COFFEE SUGAR TINS PANTRY |
| 22961 | JAM MAKING SET PRINTED |